CONSULTAS AVANÇADAS COM SQL
Aula 1
Junções em banco de dados
Junções em banco de dados
Olá, estudante! Nesta videoaula, você terá uma introdução às junções em SQL, com foco no parâmetro JOIN e em suas variações: junção interna (INNER JOIN) e junção externa (LEFT JOIN e RIGHT JOIN). Entender esses conceitos é essencial para a manipulação eficiente de dados em bancos de dados relacionais, pois permitem a combinação de informações de diferentes tabelas.
Venha aprimorar suas habilidades e potencializar sua prática profissional!
Não perca essa oportunidade!
Ponto de Partida
Olá, estudante! Até aqui você já aprendeu diversas técnicas para realizar seleções de registros em uma única tabela. No entanto, é importante destacar que essas técnicas não são suficientes para executar consultas em múltiplas tabelas, aspecto essencial para compreender os conceitos de bancos de dados relacionais, tema central de nosso estudo.
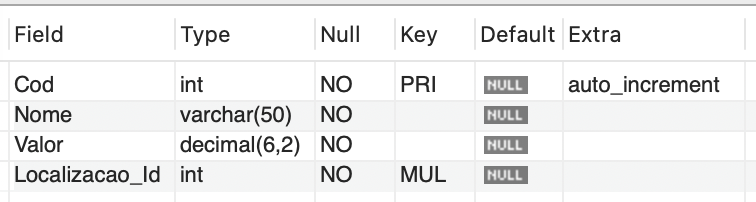
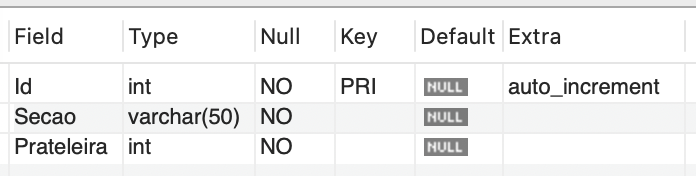
A fim de contextualizar seus estudos, imagine a seguinte situação: a empresa na qual você trabalha foi contratada por uma loja especializada em vendas de jogos de videogame e consoles, que busca modernizar seu atendimento aos clientes através do uso de tokens. Esses tokens permitirão que os clientes, por meio de interações simples na tela (utilizando um sistema touchscreen), localizem facilmente os jogos desejados, verifiquem seus preços e obtenham outras informações relevantes. O objetivo desse projeto é facilitar a mobilidade dos clientes dentro da loja, ajudando-os a encontrar os jogos desejados. Para isso, foi elaborada uma estrutura de banco de dados conforme descrito no Quadro 1.
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: | CREATE DATABASE IF NOT EXISTS SuperGames;
USE SuperGames;
CREATE TABLE localizacao ( Id INT PRIMARY KEY AUTO_INCREMENT, Secao VARCHAR(50) NOT NULL, Prateleira INT NOT NULL );
CREATE TABLE jogo ( Cod INT PRIMARY KEY AUTO_INCREMENT, Nome VARCHAR(50) NOT NULL, Valor DECIMAL(6, 2) NOT NULL, Localizacao_Id INT NOT NULL, FOREIGN KEY (Localizacao_Id) REFERENCES Localizacao(Id) ); |
Quadro 1 | Script de criação de BD e tabelas. Fonte: elaborado pelo autor.
Sua primeira responsabilidade nesse projeto é criar as consultas SQL que permitirão à aplicação realizar as seguintes tarefas:
- Identificar o nome do jogo e a prateleira correspondente, que estarão associados a uma seção específica.
- Identificar o nome dos jogos da seção de jogos de aventura, considerada a mais procurada pelos clientes.
- Identificar todas as seções e os respectivos nomes dos jogos, organizando-os em ordem alfabética crescente pelo nome dos jogos.
Para apresentar uma versão preliminar ao cliente, foi sugerido que você começasse trabalhando com as seções de corrida (prateleiras 1 e 2), aventura (prateleiras 100 e 101), RPG (prateleiras 150 e 151) e plataforma (200).
Como exemplos de jogos, utilize: Mario Carro 8 (R$ 125,00, corrida), NFS U2 Remake (R$ 250,00, corrida), A sombra do colosso (R$ 200,00, aventura), A lenda do Zeldo: chorinho do reino (R$ 299,00, aventura), Chrono break (R$ 205,00, RPG), Fakemon lápis/caneta: double pack (289,00, RPG), Super mério broca (349,00, plataforma),
Para realizar essa tarefa, é necessário compreender a estrutura de junções horizontais e verticais, bem como os comandos associados a elas. Aplique todas as técnicas discutidas nesta aula para aprimorar suas habilidades em programação de banco de dados.
Bons estudos!
Vamos Começar!
Junções em banco de dados: o parâmetro JOIN
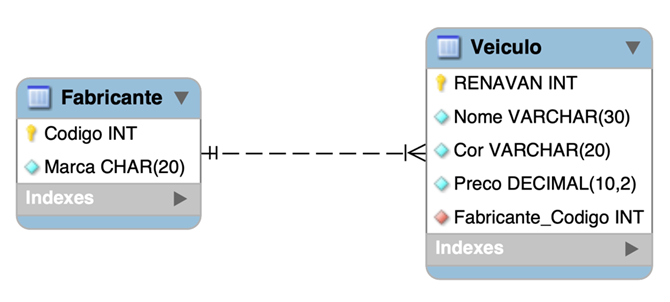
Para ilustrar os conceitos desta aula, utilizaremos o diagrama de entidade relacionamento (DER) mostrado na Figura 1. Nesse diagrama, temos duas tabelas principais: "Categoria" e "Produto". Na primeira, a chave primária é representada pela coluna "Id", enquanto na segunda a chave primária é a coluna "Codigo". Além disso, há uma relação entre essas tabelas através do campo "Id_Categoria", na tabela "Produto", que é uma chave estrangeira que referencia a chave primária da tabela "Categoria".
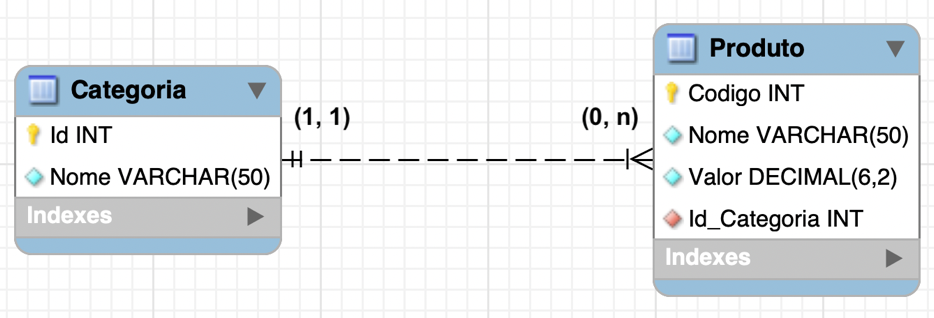
Para implementar esse modelo no banco de dados, utilizamos o script SQL apresentado no Quadro 2, o qual cria as tabelas "Categoria" e "Produto" com suas respectivas estruturas e restrições de chave estrangeira.
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: | CREATE DATABASE Loja; USE Loja;
CREATE TABLE Categoria ( Id INT PRIMARY KEY AUTO_INCREMENT, Nome VARCHAR(50) NOT NULL );
CREATE TABLE Produto ( Codigo INT PRIMARY KEY AUTO_INCREMENT, Nome VARCHAR(50) NOT NULL, Valor DECIMAL(6, 2) NOT NULL, Id_Categoria INT NOT NULL, FOREIGN KEY (Id_Categoria) REFERENCES Categoria(Id) ); |
Quadro 2 | Script de exemplo. Fonte: elaborado pelo autor.
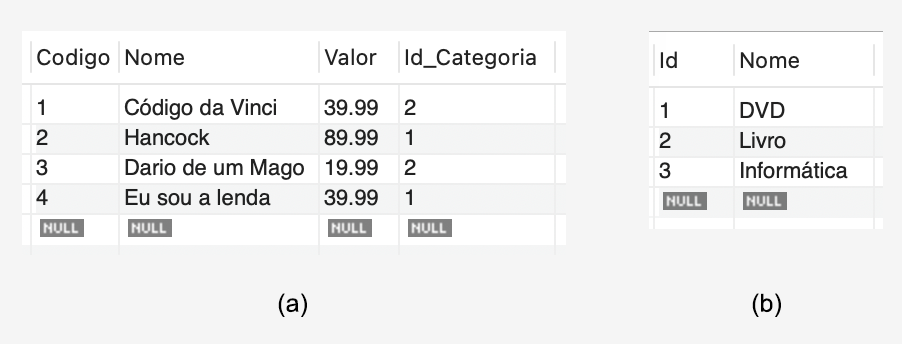
A fim de realizar consultas relacionais posteriormente, é necessário inserir registros em ambas as tabelas, como exemplificado no Quadro 3, no qual inserimos registros de exemplo nas tabelas "Categoria" e "Produto".
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: | INSERT INTO Categoria VALUES (0, "DVD"), (0, "Livro"), (0, "Informática");
INSERT INTO Produto VALUES (0, "Código da Vinci", 39.99, 2), (0, "Hancock", 89.99, 1), (0, "Dario de um Mago", 19.99, 2), (0, "Eu sou a lenda", 39.99, 1); |
Quadro 3 | Inserção de exemplos. Fonte: elaborado pelo autor.
Dessa maneira, ao realizar uma simples seleção nas duas tabelas, obteremos os resultados ilustrados na Figura 2:
As condições para realizar uma junção dependem diretamente do tipo e da condição da junção, o que possibilita, através do SQL, a obtenção de relações como resultados. Para isso, precisamos considerar:
Tipo de junção: determina o tratamento das tuplas em cada uma das relações que não correspondem a alguma das tuplas da outra relação, sendo categorizado em junção interna (INNER JOIN) e junções externas (LEFT JOIN, RIGHT JOIN e FULL JOIN).
Condição de junção: define se as tuplas em ambas as relações são correspondentes, assegurando que os atributos utilizados em ambas as tabelas estejam presentes tanto na sintaxe SQL quanto nos resultados.
Para realizar essas junções em consultas às tabelas, é necessário empregar um dos comandos mais importantes na estrutura SQL: o JOIN e suas variações.
O conceito de junções (JOIN) permite a união de duas ou mais tabelas por meio do comando SELECT, ao identificar os campos correspondentes entre elas. Para garantir a eficácia dessa operação, é fundamental que as tabelas do banco de dados estejam normalizadas. O comando JOIN exige que o banco de dados esteja normalizado para preservar o desempenho das consultas, pois isso reduz a redundância e a inconsistência dos dados, facilitando a manipulação deles e o acesso a eles. Quando um banco de dados não está normalizado, as consultas podem retornar resultados imprecisos ou incompletos devido a inconsistências nos dados.
A sintaxe para realizar junções em consultas SQL é definida como:
SELECT [campo] FROM [tabela_1] JOIN [tabela_2] ON [tabela_1].[chave_primária] = [tabela_2].[chave_estrangeira] WHERE [condição]; |
Note que a palavra JOIN está destacada em negrito e itálico para enfatizar que os mecanismos de junção disponíveis desde a versão SQL-92 permitem três tipos de JOIN: INNER, LEFT e RIGHT JOIN.
Siga em Frente...
Junção interna (INNER JOIN)
No exemplo abordado nesta aula, que trata da relação entre categorias e produtos, quando se quer realizar uma consulta que forneça o nome da categoria juntamente com os nomes dos produtos associados a ela, utilizamos o seguinte comando:
SELECT categoria.nome, produto.nome FROM Categoria INNER JOIN Produto ON Categoria.Id = Produto.Id_Categoria; |
Dessa forma, obteremos a saída representada na Figura 3:

Agora, vamos compreender alguns aspectos desse comando:
Além disso, é possível aplicar condições às consultas quando for necessário realizar junções entre as tabelas. Para exemplificar essa técnica, consideramos uma consulta na qual desejamos exibir o nome da categoria como "Tipo", o nome do produto como "Produto" e o valor dos produtos, sob a condição de que o valor seja menor que R$ 50,00. O comando SQL correspondente é o seguinte:
SELECT categoria.nome as "Tipo", produto.nome as "Produto", produto.valor FROM Categoria INNER JOIN Produto ON Categoria.Id = Produto.Id_Categoria WHERE produto.valor < 50.00; |
Essa consulta gera a saída apresentada na Figura 4:

O comando JOIN é amplamente utilizado em diversas aplicações web, por exemplo:
- Em sites de hospedagem, nos quais é necessário estabelecer relações entre diferentes tabelas para gerar resultados de pesquisa, como datas de entrada/saída, categorias e opções de hospedagem.
- Em sites de compras, nos quais se relaciona a localização do vendedor, as faixas de preço, a relevância do anúncio e as opções de pagamento e envio.
- Nos buscadores web, como Google, Bing e Yahoo, nos quais os filtros por data, tipo de conteúdo, idioma e país de origem são implementados por meio de consultas que envolvem JOIN.
As consultas realizadas até o momento foram internas, mas também é possível realizar consultas externas.
Junção externa (LEFT JOIN e RIGHT JOIN)
Ao utilizar o operador de junção externa no SQL, o resultado da junção inclui tanto as linhas combinadas quanto as não combinadas. É possível realizar junções externas em ambos os lados, isto é, da esquerda para a direita e vice-versa. Independentemente do lado escolhido, a junção externa resulta em uma nova tabela, que combina as linhas correspondentes e não correspondentes.
No comando LEFT JOIN, as linhas da tabela da esquerda do comando são projetadas na seleção juntamente com as linhas não combinadas da tabela da direita. Ou seja, o resultado da seleção inclui algumas linhas em que não há correspondência entre as tabelas da esquerda para a direita, as quais retornam o valor nulo (NULL).
Para ilustrar, considere o seguinte exemplo:
SELECT categoria.nome as "Tipo", produto.nome as "Produto", produto.valor FROM Categoria LEFT JOIN Produto ON Categoria.Id = Produto.Id_Categoria; |
Com isso, obtemos a saída representada na Figura 5:

No exemplo mostrado na Figura 5, ao usar o trecho de código "FROM Categoria LEFT JOIN Produto", são projetados todos os registros da tabela da esquerda (Categoria) e, na seleção final, as linhas não combinadas, como é o caso da categoria "Informática", que não possuem nenhum produto associado, apresentam o resultado NULL. Portanto, as colunas "Produto" e "Valor" (referentes à tabela Produto) recebem valores nulos (NULL) como resultado.
De modo semelhante ao comando LEFT JOIN, no RIGHT JOIN, as linhas da tabela da direita do comando são projetadas na seleção juntamente com as linhas não combinadas da tabela da esquerda. Um exemplo seria:
SELECT categoria.nome as "Tipo", produto.nome as "Produto", produto.valor FROM Categoria RIGHT JOIN Produto ON Categoria.Id = Produto.Id_Categoria; |
Assim, obteremos a saída representada na Figura 6:

No exemplo mostrado na Figura 6, ao usar o trecho de código "FROM Categoria RIGHT JOIN Produto", são projetados todos os registros da tabela da direita (Produto). Como não há nenhum produto associado à categoria "Informática", nenhum registro com valor nulo (NULL) é exibido na seleção dos registros relacionados à tabela Categoria.
Vamos Exercitar?
Antes de elaborar os comandos solicitados, é necessário realizar algumas inserções de dados na tabela previamente apresentada (Quadro 1). Os registros requisitados podem ser adicionados utilizando-se o script SQL fornecido no Quadro 4.
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: | INSERT INTO localizacao VALUES (0, "Corrida", "001"), (0, "Corrida", "002"), (0, "Aventura", "100"), (0, "Aventura", "101"), (0, "RPG", "150"), (0, "RPG", "151"), (0, "Plataforma", "200");
INSERT INTO jogo VALUES (0, "Mario Carro 8", 125.00, 1), (0, "NFS U2 Remake", 150.00, 2), (0, "A Sombra do Colosso", 200.00, 3), (0, "A Lenda do Zeldo: Chorinho do Reino (0, "Chrono Break", 205.00, 5); (0, "Fakemon Lápis/Caneta: Double Pack", 589.00, 6); (0, "Super Mério Broca |
Quadro 4 | Inserção de dados no banco SuperGames. Fonte: elaborado pelo autor.
É importante observar que, ao inserir dados na tabela "Localizacao", os códigos, por serem chaves primárias, serão autoincrementados. Com isso, podemos desenvolver os scripts dos três filtros e testá-los utilizando suas respectivas saídas.
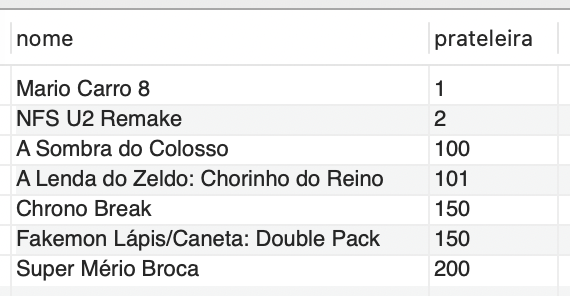
Para identificar o nome do jogo e a prateleira, fornecendo o nome de uma seção, temos o seguinte comando:
SELECT jogo.nome, localizacao.prateleira FROM jogo INNER JOIN localizacao ON localizacao.Id = jogo.localizacao_Id; |
A saída correspondente é mostrada na Figura 7.
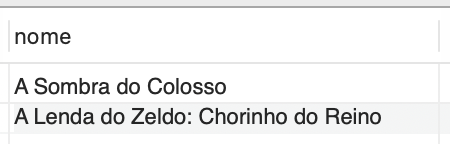
Para identificar os nomes dos jogos da seção de jogos de aventura, temos o seguinte comando:
SELECT jogo.nome FROM jogo INNER JOIN localizacao ON localizacao.Id = jogo.localizacao_Id WHERE localizacao.secao = "Aventura"; |
A saída correspondente é exibida na Figura 8.
Para identificar todas as seções e os respectivos nomes dos jogos, organizando as seleções em ordem crescente pelo nome dos jogos, foi elaborado o seguinte comando:
SELECT localizacao.secao, jogo.nome FROM localizacao LEFT JOIN jogo ON localizacao.Id = jogo.localizacao_Id ORDER BY jogo.nome ASC; |
A saída correspondente é apresentada na Figura 9.

Após esse procedimento, o desenvolvedor da aplicação poderá empregar esses scripts para que os tokens auxiliem os usuários dentro da loja, elevando, assim, o nível de satisfação dos clientes.
Saiba Mais
Para se aprofundar nos estudos dos diferentes tipos de JOINs, acesse o seguinte artigo no portal DevMedia.
FERNANDA. SQL JOIN: Entenda como funciona o retorno dos dados. DevMedia, Rio de Janeiro, 2014.
Para complementar o estudo dos comandos de junção de dados, faça a leitura do capítulo 4 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 4, p. 68-73.
Recomendamos também uma visita ao site W3Schools para complementar seus estudos. Ele explica os diferentes tipos de junções usando exemplos práticos e animações, o que torna o aprendizado mais fácil e intuitivo.
W3SCHOOLS. SQL Joins. W3Schools, [s. l.], c2024.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
FERNANDA. SQL JOIN: Entenda como funciona o retorno dos dados. DevMedia, Rio de Janeiro, 2014. Disponível em: https://www.devmedia.com.br/sql-join-entenda-como-funciona-o-retorno-dos-dados/31006. Acesso em: 2 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
W3SCHOOLS. SQL Joins. W3Schools, [s. l.], c2024. Disponível em: https://www.w3schools.com/sql/sql_join.asp. Acesso em: 10 fev. 2024.
Aula 2
Funções de agregação
Funções de agregação
Olá, estudante! Nesta videoaula, você mergulhará no mundo das funções de agregação e aprenderá suas estruturas de utilização. Logo, você entenderá, em detalhes, as funções COUNT, MIN e MAX, além de explorar as poderosas funcionalidades das funções AVG e SUM.
Esses conceitos são fundamentais para a sua prática profissional, pois lhe permitem manipular e analisar dados de forma eficiente, contribuindo para tomadas de decisão precisas. Prepare-se para essa jornada de conhecimento!
Vamos lá!
Ponto de Partida
Estudante, imagine que você trabalha em uma empresa responsável pelo desenvolvimento das funcionalidades relacionadas ao banco de dados de uma loja de jogos para videogames e computadores. Durante a etapa inicial do projeto, foram criadas as instruções necessárias para realizar consultas de dados em múltiplas tabelas, permitindo, assim, a implementação do sistema presente nos terminais de autoatendimento distribuídos pela loja, disponíveis para uso dos clientes. A estrutura do banco de dados desse projeto segue o modelo ilustrado nas Figuras 1 e 2.
A segunda fase do projeto tem como objetivo criar algumas funcionalidades operacionais e administrativas, que, antes, eram realizadas manualmente pelo gerente da loja. Para isso, o gerente de projetos solicitou o desenvolvimento de scripts específicos para incorporar essas funções ao sistema de gerenciamento. Entre essas solicitações estão a criação de funções de agregação para retornar:
- O número total de registros na tabela de jogos.
- O valor do jogo mais caro.
- O valor do jogo mais barato.
- A média de preço dos jogos de corrida.
- E o valor total em estoque na loja.
Diante disso, nesta aula, você aprenderá sobre as funções de agregação em programação de bancos de dados, seus comandos, suas estruturas e exemplos práticos para auxiliá-lo no desenvolvimento da aplicação.
Aproveite os estudos!
Vamos Começar!
Definição de funções de agregação e estrutura de utilização
As funções de agregação em SQL permitem elaborar consultas utilizando os valores das colunas como parâmetros de pesquisa (SELECT). Para ilustrar os conceitos e as aplicações que serão abordados nesta aula, considere o banco de dados da Figura 3.
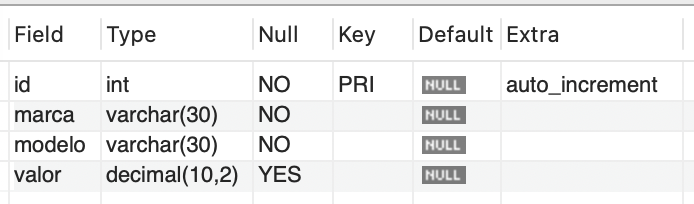
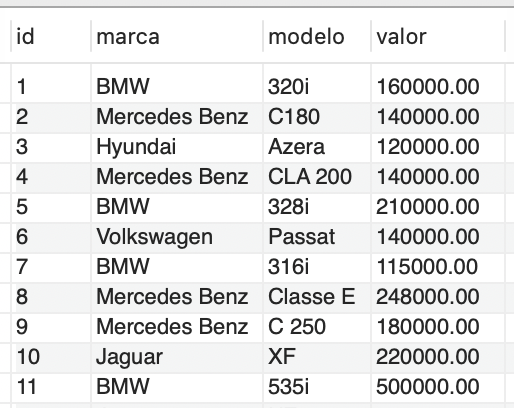
Neste contexto, é importante mencionar que os registros necessários já foram inseridos, conforme demonstrado na Figura 4.
Antes de adentrarmos nas funções de agregação em si, devemos nos atentar aos conceitos relacionados à organização de dados em grupos. Os resultados de seleções podem ser agrupados com base no conteúdo de uma ou mais colunas. Para isso, utiliza-se a cláusula GROUP BY na estrutura SQL da seguinte forma:
SELECT [coluna] FROM [tabela] GROUP BY [coluna]; |
Além disso, é possível combinar a cláusula WHERE com o agrupamento, empregando a seguinte sintaxe SQL:
SELECT [coluna] FROM [tabela] WHERE [condição] GROUP BY [coluna]; |
Essa abordagem permite filtrar os dados com base em uma condição específica antes de agrupá-los, o que resultará em conjuntos de dados mais refinados e específicos conforme a necessidade da consulta.
As funções agregadas são aquelas que operam sobre um conjunto de valores como entrada e que retornam um único valor como resultado. O SQL oferece cinco funções de agregação nativas, incluindo AVG (média), MIN (mínimo), MAX (máximo), SUM (soma) e COUNT (contagem).
O padrão geral de utilização de funções de agregação em SQL segue uma estrutura básica, que consiste em selecionar os dados desejados de uma tabela e aplicar a função de agregação para obter um único valor agregado. Veja a sintaxe geral:
SELECT função_de_agregação(coluna) AS nome_da_coluna_agregada FROM tabela [WHERE condição] [GROUP BY coluna] |
Primeiramente, utiliza-se o comando SELECT para indicar a seleção de dados. Em seguida, especifica-se a função de agregação a ser aplicada aos valores da coluna selecionada, como AVERAGE, MINIMUM, MAXIMUM, TOTAL ou COUNT, dependendo do sistema de gerenciamento de banco de dados (SGBD). A coluna da tabela na qual se deseja realizar a agregação é então indicada e seguida opcionalmente por um alias que nomeia o resultado agregado.
A cláusula FROM determina em qual tabela os dados serão selecionados, enquanto a cláusula WHERE permite filtrar os dados antes da aplicação da função de agregação. Por fim, a cláusula GROUP BY é opcional e agrupa os dados com base nos valores únicos de uma coluna antes da agregação, sendo útil para calcular agregações por grupos de dados, como médias por categoria.
Funções COUNT, MIN e MAX
COUNT
A função de agregação COUNT tem a finalidade de contar o número de registros em uma relação. Um exemplo prático dessa sintaxe pode ser visto na contagem de registros na tabela Veículos, na qual temos:
| SELECT COUNT(*) FROM Veiculos; |
Essa consulta resulta na tabela da Figura 5:
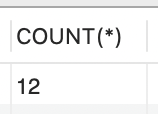
Nesse exemplo, podemos perceber que são demonstradas as inserções da tabela Veículos e que o autoincremento na coluna "Id" registrou 12 entradas. Ou seja, o uso do COUNT com (*) possibilita a contagem de todas as colunas.
Note que a função COUNT pode ser aplicada a uma coluna específica, como:
| SELECT COUNT(Modelo) FROM Veiculos; |
Seu retorno é especificado na Figura 6.
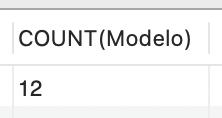
No entanto, é necessário ter cautela ao utilizar COUNT, pois ela ignora registros com valores nulos, como:
| SELECT COUNT(Valor) FROM Veiculos; |
Veja o resultado na Figura 7.
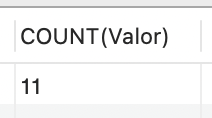
Se decidíssemos usar a coluna "Valor" para determinar o número de veículos registrados no banco de dados, estaríamos propensos a cometer um erro. Assim, é importante observar que a função COUNT não considera a contagem de tuplas com valores nulos, embora seja possível inserir registros em algumas colunas com valores vazios.
Além disso, ao utilizar COUNT para contar a quantidade de marcas de carro cadastradas, podemos empregar a função DISTINCT, como no seguinte exemplo:
| SELECT COUNT(DISTINCT Marca) FROM Veiculos; |
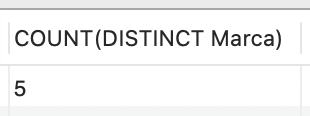
Conforme demonstrado na Figura 8, essa abordagem evita a contagem de informações redundantes, sendo especialmente útil ao lidar com grandes conjuntos de dados, como na seleção de estados com clientes cadastrados em uma tabela de clientes.
MIN
A função de agregação MIN permite determinar o menor valor registrado em uma coluna. Em um exemplo prático, podemos selecionar o menor valor registrado na tabela usando o seguinte comando SQL:
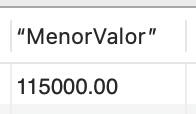
| SELECT MIN(Valor) AS “Menor Valor” FROM Veiculos; |
Isso resultará em um retorno similar ao demonstrado na Figura 9.
Além disso, é possível combinar a função MIN com a cláusula WHERE, por exemplo:
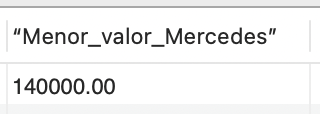
SELECT MIN(Valor) as “Menor_valor_Mercedes” FROM veiculos WHERE Marca = 'Mercedes Benz'; |
E o resultado é exemplificado na Figura 10, em que é selecionado o modelo de menor valor da marca "Mercedes Benz".
De maneira similar à função MIN, a função MAX possibilita identificar o valor mais alto de um registro em uma coluna. A estrutura SQL para essa função é a seguinte:
| SELECT MAX(<coluna>) FROM <tabela>; |
Siga em Frente...
Funções AVG e SUM
A função AVG (abreviação de average, que significa média, em inglês) retorna a média dos valores em uma coluna específica. Para isso, o SQL realiza a soma dos valores (que devem ser obrigatoriamente numéricos) e divide o resultado pelo número de registros distintos de nulo (NULL).
Com base no exemplo utilizado nesta aula, calculemos o valor médio dos veículos registrados na tabela, utilizando o comando SQL abaixo, que resultará na saída apresentada na Figura 11.
| SELECT AVG(Valor) as “Valor Médio” FROM Veiculos; |

Ao aplicar esse comando, mesmo havendo 12 veículos registrados (sendo um deles com o valor nulo), o SQL realiza a soma apenas dos veículos com valores diferentes de nulo e divide pelo número de registros também diferentes de nulo.
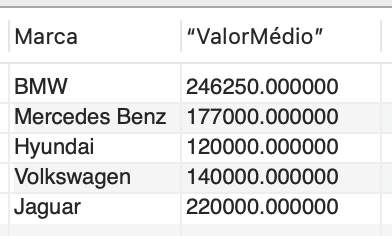
A função de agregação AVG permite o uso do qualificador GROUP BY em conjunto. Por exemplo, é possível selecionar as marcas e o valor médio dos veículos agrupados por marca, utilizando o seguinte comando SQL:
SELECT Marca, AVG(Valor) as “Valor Médio” FROM Veiculos GROUP BY Marca; |
Isso resulta na saída demonstrada na Figura 12. Com essa função de agregação, os resultados médios são agrupados de acordo com as marcas registradas no banco de dados.
Por fim, a função SUM retorna a soma total dos valores em uma determinada coluna. Para isso, o SQL realiza o somatório dos valores (que devem ser obrigatoriamente numéricos).
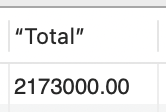
Para o exemplo desta aula, faremos o somatório dos valores dos veículos registrados na tabela utilizando o seguinte comando SQL:
| SELECT SUM(Valor) as “Total” FROM Veiculos; |
Isso gerará o resultado mostrado na Figura 13.
Vamos Exercitar?
Você está trabalhando em um projeto de desenvolvimento de tokens para uma loja física de videogames e consoles e está encarregado das tarefas relacionadas ao banco de dados. Depois de criar as sintaxes para realizar algumas consultas em várias tabelas, agora precisa desenvolver funções operacionais e administrativas para o gerenciamento da loja. Assim, o gerente de projetos solicitou que você criasse algumas funções de agregação que forneceriam:
- O número total de registros na tabela de jogos.
- O valor do jogo mais caro.
- O valor do jogo mais barato.
- A média de preço dos jogos de corrida.
- E o valor total em estoque na loja.
Para resolver esse problema, as seguintes atividades devem ser realizadas:
1. Crie uma função de agregação que retorne o número total de registros na tabela de jogos. Utilize o seguinte comando SQL:
| SELECT count(*) FROM Jogo; |
2. Desenvolva uma função de agregação que retorne o valor do jogo mais caro. Utilize o seguinte comando SQL:
| SELECT MAX(valor) AS "MaiorValor" FROM Jogo; |
3. Crie uma função de agregação que retorne o valor do jogo mais barato. Utilize o seguinte comando SQL contendo o agregador MIN:
| SELECT MIN(valor) AS "Menor Valor" FROM Jogo; |
4. Desenvolva uma função de agregação que retorne a média de preço dos jogos de corrida. Utilize o comando SQL a seguir com o agregador AVG:
SELECT AVG(valor) AS "Média de Preço de Guerra" FROM Jogo INNER JOIN localizacao ON localizacao.Id = jogo.localizacao_Id WHERE secao = "corrida"; |
5. Crie uma função de agregação que retorne o valor total em estoque na loja. Utilize o comando SQL a seguir com o agregador SUM:
| SELECT SUM(valor) AS "Total em Estoque" FROM jogo; |
Com a implementação desses comandos, você terá atendido às demandas e terá criado um banco de dados altamente funcional para as operações administrativas da loja.
Saiba Mais
Para complementar o estudo das funções de agregação, faça a leitura do capítulo 3 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 3, p. 50-51.
Recomendamos também uma visita aos seguintes sites que apresentam, de forma bem intuitiva, um complemento à utilização de GROUP BY com funções de agregação, bem como uma introdução ao comando HAVING, que é muito utilizado nesse contexto.
W3SCHOOLS. SQL GROUP BY Statement. W3Schools, [s. l.], c2024.
W3SCHOOLS. SQL HAVING Clause. W3Schools, [s. l.], c2024.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
W3SCHOOLS. SQL GROUP BY Statement. W3Schools, [s. l.], c2024. Disponível em: https://www.w3schools.com/sql/sql_groupby.asp. Acesso em: 10 fev. 2024.
W3SCHOOLS. SQL HAVING Clause. W3Schools, [s. l.], c2024. Disponível em: https://www.w3schools.com/sql/sql_having.asp. Acesso em: 10 fev, 2024.
Aula 3
Sub-consultas aninhadas
Sub-consultas aninhadas
Olá, estudante! Na videoaula de hoje, você explorará os conceitos fundamentais de subconsultas e aprenderá a comparar conjuntos e a integrá-los com funções de agregação e junções.
Essas habilidades são essenciais para sua prática profissional, pois lhe permitem manipular e analisar dados de maneira mais avançada, ampliando suas capacidades analíticas e de resolução de problemas. Está pronto para aprofundar seus conhecimentos?
Junte-se a nós nesta jornada!
Ponto de Partida
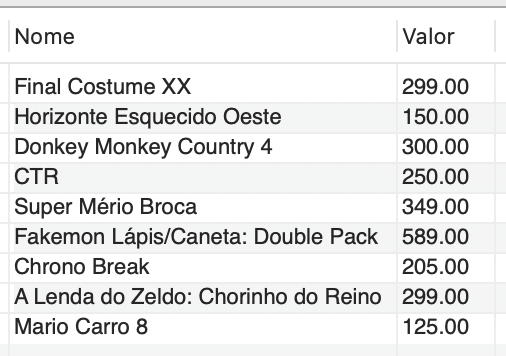
Estudante, você está empregado em uma empresa que presta serviços para uma loja de jogos especializada em consoles e computadores de última geração. Devido ao êxito conquistado no mercado, a loja está inovando tanto na gestão quanto no atendimento ao cliente. Recentemente, foram instalados terminais de autoatendimento na loja para que os clientes possam consultar a localização e os preços dos jogos. Com o aumento das vendas devido à tecnologia implementada, novos títulos foram adicionados ao catálogo, incluindo um jogo de corrida chamado CTR, que está sendo vendido por R$ 250,00; um jogo de plataforma chamado Donkey Monkey Country 4, vendido por R$ 300,00; um jogo de aventura intitulado Horizonte Esquecido Oeste, que custa R$ 150,00; e um jogo de RPG chamado Final Costume XX, que está R$ 299,00. Como resultado do sucesso das vendas, os jogos mais antigos, como A sombra do colosso e NFS U2 Remake, receberam um desconto de 50%.
Todas essas mudanças afetam o banco de dados utilizado nos terminais de autoatendimento. Por ser o responsável pelo banco de dados, seu gerente de projeto solicitou-lhe que realizasse as seguintes tarefas:
- Adicionar os novos títulos ao banco de dados para que os clientes possam consultá-los.
- Alterar os preços dos jogos em promoção.
- Criar uma tabela chamada "promoção", com um número identificador da promoção e o código do jogo (chave estrangeira da tabela de jogo).
- Inserir os jogos em promoção na tabela criada.
- implementar uma maneira de selecionar o nome do jogo, o valor e o nome da seção dos títulos em promoção.
- implementar uma maneira de selecionar o nome dos títulos e seus respectivos valores que não estão em promoção, retornando apenas os mais recentes disponíveis na loja.
Para realizar essas tarefas, é necessário planejar a implementação da tabela "promoção" e como ela se relacionará com a tabela de jogos. Além disso, para desenvolver os filtros de consulta, serão utilizadas técnicas de subconsulta por meio da linguagem de programação de banco de dados SQL.
Bons estudos!
Vamos Começar!
Conceitos básicos de subconsultas
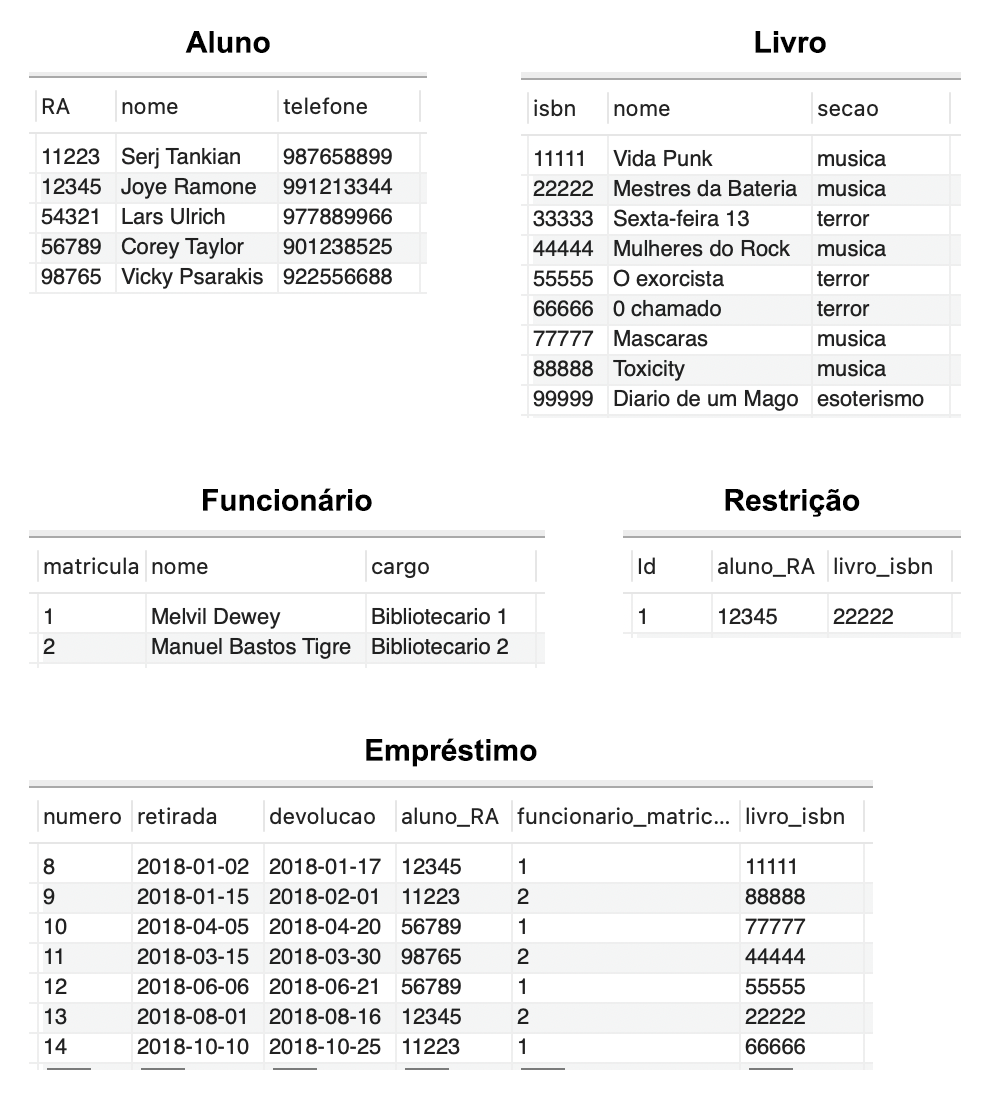
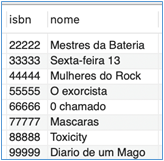
Para ilustrar os conceitos e as aplicações a serem discutidos nesta aula, foi criado um banco de dados para armazenar informações de uma biblioteca, conforme representado no esquema a seguir:
- Aluno (RA, nome, telefone).
- Funcionário (matrícula, nome, cargo).
- Livro (ISBN, nome, seção).
- Empréstimo (número, retirada, devolução, aluno_RA, funcionario_matricula, livro_isbn).
- Restrição (Id, aluno_RA, livro_isbn).
Considere que os registros foram inseridos nas tabelas como demonstrado na Figura 1.
Uma subconsulta é uma expressão em SQL composta por SELECT-FROM-WHERE, aninhada dentro de outra consulta, que permite fazer comparações entre conjuntos de dados.
A sintaxe do SQL permite realizar consultas utilizando diferentes relações entre várias tabelas nos bancos de dados, utilizando conectivos como o IN e o NOT IN. O IN realiza um teste no conjunto de dados, que é o resultado de uma coleção de valores produzidos por um SELECT, enquanto o NOT IN permite verificar a ausência em um conjunto de valores. A sintaxe básica é a seguinte:
SELECT [campo] FROM [tabela] WHERE [campo] IN / NOT IN (SELECT [campo] FROM [tabela]); |
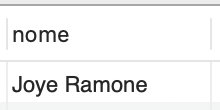
Para ilustrar essa técnica, usaremos como exemplo uma consulta em que desejamos encontrar os nomes de todos os alunos que realizaram empréstimos, mas que estão com restrição para novas retiradas de livros. Nesse caso, a consulta ficaria assim:
SELECT aluno.nome FROM aluno WHERE aluno.RA IN (SELECT aluno_RA FROM restricao); |
Essa instrução SQL seleciona o nome do aluno na tabela Aluno quando o RA dele estiver presente na seleção do RA na tabela Restrição. A saída gerada por essa subconsulta é apresentada na Figura 2.
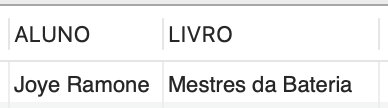
Para ampliar seu entendimento sobre isso, podemos também consultar o nome do livro que o aluno Joey Ramone não devolveu, o que o impede de fazer novos empréstimos. Nesse caso, o comando seria o seguinte:
SELECT aluno.nome as "ALUNO", livro.nome as "LIVRO" FROM aluno, livro WHERE aluno.RA IN (SELECT aluno_RA FROM restricao) AND livro.isbn IN (SELECT livro_isbn FROM restricao); |
Essa consulta produzirá uma saída, que é demonstrada na Figura 3.
Nesses exemplos, podemos entender como as subconsultas podem ser incorporadas às consultas principais, permitindo que um SELECT dentro de outro SELECT avalie a relação entre atributos nas tabelas do banco de dados.
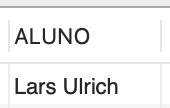
Já o operador NOT IN é empregado de maneira similar, porém sua aplicação é completamente diferente. Isso acontece porque o NOT IN permite a negação da seleção. Para ilustrar essa distinção, selecionaremos os nomes dos alunos que nunca fizeram empréstimos de livros. Para isso, a seguinte instrução foi elaborada:
SELECT aluno.nome as “ALUNO” FROM aluno WHERE aluno.RA NOT IN (SELECT aluno_RA FROM emprestimo); |
Essa expressão SQL escolherá o nome do aluno na tabela Aluno quando o RA dele não estiver presente na seleção dos RAs na tabela Empréstimo. A saída produzida pela subconsulta é apresentada na Figura 4.
É importante notar que as subconsultas não necessariamente precisam envolver duas tabelas relacionadas, visto que podem ser aplicadas em apenas uma tabela. Por exemplo, podemos selecionar nomes dos livros, ignorando aqueles da seção "música", com a seguinte instrução:
SELECT nome as “LIVRO” FROM livro WHERE seção NOT IN (SELECT seção FROM emprestimo WHERE seção = "música"); |
Com isso, podemos observar a saída exemplificada na Figura 5.

Ao permitir a comparação de conjuntos de dados selecionados, o SQL oferece aos desenvolvedores a capacidade de ampliar significativamente as possibilidades de busca de informações. Por exemplo, ao considerar um banco de dados com o nome de todas as seleções que já participaram da Copa do Mundo, podemos exibir apenas se o número de seleções campeãs europeias for maior do que o número de seleções campeãs africanas. Essa consulta certamente resultaria na exibição dos nomes, pois o número de seleções da Europa é maior do que o de seleções do continente africano.
Siga em Frente...
Comparação de conjuntos
Na linguagem SQL, é possível desenvolver subconsultas aninhadas que permitem comparar conjuntos de dados usando condições (WHERE). No entanto, para realizar essas comparações, é necessário incluir a palavra "SOME" na sintaxe dos operadores de comparação, conforme indicado no Quadro 1.
Operador matemático | SELECT com WHERE (SQL) | Subconsulta (SQL) |
=
| WHERE campo = condição | WHERE campo = SOME (SELECT...) |
≠
| WHERE campo <> condição | WHERE campo <> SOME (SELECT...) |
>
| WHERE campo > condição | WHERE campo > SOME (SELECT...) |
≥
| WHERE campo >= condição | WHERE campo >= SOME (SELECT...) |
<
| WHERE campo < condição | WHERE campo < SOME (SELECT...) |
≤
| WHERE campo <= condição | WHERE campo <= SOME (SELECT...) |
Quadro 1 | Operadores de comparação em subconsultas SQL. Fonte: elaborado pelo autor.
O conceito de comparação entre conjuntos de dados está intimamente relacionado às estruturas usadas na lógica matemática, em que os resultados esperados são verdadeiros ou falsos.
Para ilustrar isso, consideraremos a seguinte consulta, que selecionará o nome de todos os livros cujo ISBN é maior do que pelo menos um dos ISBNs presentes na tabela de empréstimos:
SELECT nome FROM Livro WHERE isbn > SOME (SELECT livro_isbn FROM Emprestimo); |
Nesse caso, a subconsulta `(SELECT livro_isbn FROM Emprestimo)` retornará os ISBNs dos livros que foram emprestados. Suponha que esses ISBNs sejam (11111, 88888, 77777, 44444, 55555, 22222, 66666). A consulta principal então comparará o ISBN de cada livro da tabela Livro com esses ISBNs. Por exemplo, levando-se em consideração o livro com ISBN 99999, como 99999 é maior do que todos os ISBNs da subconsulta, ele será incluído no resultado. Assim, o resultado da consulta será todos os livros cujo ISBN é maior do que pelo menos um dos ISBNs presentes na tabela de empréstimos. O resultado é apresentado na Figura 6.
Subconsultas em conjunto com funções de agregação e junções
Exploraremos agora alguns exemplos interessantes que mesclam as subconsultas com funções de agregação e junções. É hora de colocar em prática, de forma conjunta, os conceitos estudados até aqui.
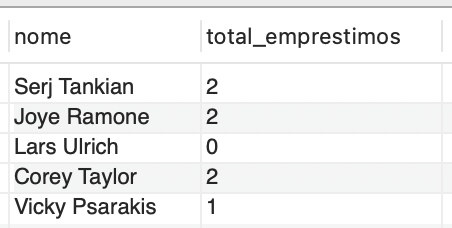
No primeiro exemplo, considere a necessidade de calcular a quantidade de empréstimos feitos por cada aluno da biblioteca. O código é exibido a seguir:
SELECT Aluno.nome, COUNT(Emprestimo.numero) AS total_emprestimos FROM Aluno LEFT JOIN Emprestimo ON Aluno.RA = Emprestimo.aluno_RA GROUP BY Aluno.nome; |
Para realizar essa análise, utilizaremos uma junção LEFT JOIN entre as tabelas Aluno e Empréstimo. A junção LEFT JOIN garante que todos os alunos sejam incluídos na contagem, mesmo que não tenham feito nenhum empréstimo. A função de agregação COUNT() é, então, aplicada para contar o número de empréstimos feitos por cada aluno. Essa função é aplicada sobre a coluna “numero” da tabela Empréstimo. Usamos a cláusula ‘GROUP BY Aluno.nome` para agrupar os resultados pelo nome do aluno. O resultado da consulta é exibido na Figura 7.
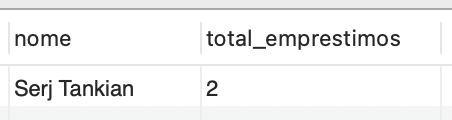
Agora vamos a outro exemplo. Suponha que você queira identificar o aluno que realizou o maior número de empréstimos na biblioteca. Os comandos SQL para isso são os seguintes:
SELECT Aluno.nome, ( SELECT COUNT(*) FROM Emprestimo WHERE Emprestimo.aluno_RA = Aluno.RA ) AS total_emprestimos FROM Aluno ORDER BY total_emprestimos DESC LIMIT 1; |
Para tanto, utilizaremos uma subconsulta correlacionada, de modo que a subconsulta é executada para cada aluno na tabela Aluno. Na subconsulta, contamos o número total de empréstimos feitos por um aluno específico, por meio da cláusula `WHERE Emprestimo.aluno_RA = Aluno.RA`, que faz a correspondência entre o RA do aluno na tabela Aluno e o aluno_RA na tabela Empréstimo. Dessa forma, a subconsulta é executada para cada aluno individualmente.
A coluna resultante da subconsulta é, então, renomeada como `total_emprestimos` e é selecionada como parte da consulta principal. Organizamos os resultados em ordem decrescente de empréstimos utilizando a cláusula `ORDER BY total_emprestimos DESC`. Por fim, limitamos a consulta para retornar apenas o primeiro resultado utilizando a cláusula `LIMIT 1`, que nos dará o aluno com o maior número de empréstimos. O resultado da consulta é exibido na Figura 8.
Veja como esses exemplos ilustram casos simples, mas efetivos, sobre como as subconsultas podem ser utilizadas de forma eficaz em conjunto com funções de agregação e junções. Ter o domínio sobre essas técnicas pode torná-lo capaz de realizar análises mais complexas e de obter insights úteis a partir dos dados armazenados em um banco de dados.
Vamos Exercitar?
Com o êxito da introdução dos tokens na loja de games, foi necessário atualizar o banco de dados com os novos títulos disponíveis para venda. Adicionalmente, houve uma revisão nos preços de jogos mais antigos, os quais receberam um desconto de 50%.
Diante dessas mudanças, você deve realizar atualizações no banco de dados dos tokens, o que inclui a inserção dos novos títulos no banco de dados, para que possam ser acessados, a alteração do valor dos jogos em promoção e o desenvolvimento de uma tabela específica para as promoções, contendo um identificador único da promoção e o código do jogo (chave estrangeira da tabela de jogos). Posteriormente, será necessário inserir os jogos em promoção na tabela criada, além de elaborar consultas que permitam selecionar o nome do jogo, o valor e a seção dos títulos em promoção, bem como selecionar os títulos que não estão em promoção e seus respectivos valores.
Para atender a essas demandas, considere os seguintes comandos SQL:
1. Adicionar os novos títulos ao banco de dados para que os clientes possam consultá-los.
INSERT INTO jogo (Nome, Valor, Localizacao_Id) VALUES ('CTR', 250.00, 1), ('Donkey Monkey Country 4', 300.00, 7), ('Horizonte Esquecido Oeste', 150.00, 3), ('Final Costume XX', 299.00, 6); |
2. Alterar os preços dos jogos em promoção.
UPDATE jogo SET Valor = Valor * 0.5 WHERE Nome IN ('A Sombra do Colosso', 'NFS U2 Remake'); |
3. Criar uma tabela chamada Promoção, com um número identificador da promoção e o código do jogo (chave estrangeira da tabela de jogo).
CREATE TABLE promocao ( Id INT PRIMARY KEY AUTO_INCREMENT, Jogo_Cod INT, FOREIGN KEY (Jogo_Cod) REFERENCES jogo(Cod) ); |
4. Inserir os jogos em promoção na tabela criada.
INSERT INTO promocao (Jogo_Cod) VALUES ((SELECT Cod FROM jogo WHERE Nome = 'A Sombra do Colosso')), ((SELECT Cod FROM jogo WHERE Nome = 'NFS U2 Remake')); |
*Perceba que, aqui, utilizamos um modo alternativo de inserir o código do jogo na tabela ‘Promocao’. Ao invés de procurarmos manualmente o código dos jogos na tabela ‘Jogo’, podemos fazer um SELECT para esse fim, que vai retornar exatamente o código de que precisamos.
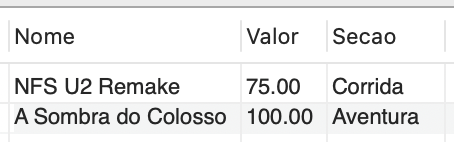
5. Implementar uma maneira de selecionar o nome do jogo, o valor e o nome da seção dos títulos em promoção (o resultado é apresentado na Figura 9).
SELECT jogo.Nome, jogo.Valor, localizacao.Secao FROM jogo JOIN localizacao ON jogo.Localizacao_Id = localizacao.Id WHERE jogo.Cod IN (SELECT Jogo_Cod FROM promocao); |
6. Implementar uma maneira de selecionar os títulos e seus respectivos valores que não estão em promoção, retornando apenas os mais recentes disponíveis na loja (o resultado é apresentado na Figura 10).
SELECT jogo.Nome, jogo.Valor FROM jogo WHERE jogo.Cod NOT IN (SELECT Jogo_Cod FROM promocao) ORDER BY jogo.Cod DESC; |
*Perceba que, neste caso, como não estamos precisando de nenhuma informação de outra tabela (a não ser da própria tabela ‘Jogo’), não precisamos utilizar junções.
A implementação desses comandos permitirá satisfazer a solicitação do seu supervisor, melhorando a eficiência do uso dos tokens.
Saiba Mais
Para complementar o estudo de subconsultas aninhadas, leia o capítulo 3 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 3, p. 52-57.
Recomendamos também uma visita aos seguintes sites que apresentam, de forma bem intuitiva, um complemento ao estudo sobre subconsultas. Eles trazem mais exemplos para enriquecer o seu entendimento.
PABLO. Trabalhando com subqueries. DevMedia, Rio de Janeiro, 2018.
O site a seguir, W3Schools, apesar de expor o conteúdo em inglês, apresenta muito exemplos de forma intuitiva sobre banco de dados. O link a seguir explica detalhadamente o uso do comando ANY (cuja função é igual ao do SOME, estudado nesta aula).
W3SCHOOLS. SQL ANY and ALL Operators. W3Schools, [s. l.], c2024.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
PABLO. Trabalhando com subqueries. DevMedia, Rio de Janeiro, 2018. Disponível em: https://www.devmedia.com.br/trabalhando-com-subqueries/40134. Acesso em: 10 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
W3SCHOOLS. SQL ANY and ALL Operators. W3Schools, [s. l.], c2024. Disponível em: https://www.w3schools.com/sql/sql_any_all.asp. Acesso em: 10 fev. 2024.
Aula 4
Visões e índices
Visões e índices
Olá, estudante! Na videoaula de hoje, você aprenderá o que são visões de tabelas e como utilizá-las, além de compreender a importância dos índices em bancos de dados relacionais e como aplicar a técnica FULLTEXT.
Esses conhecimentos são cruciais para sua prática profissional, pois proporcionam uma visão mais abrangente e eficiente da manipulação e da busca de dados em sistemas complexos. Está pronto para aprimorar suas habilidades?
Junte-se a nós nesta jornada de aprendizado!
Ponto de Partida
Quando realizamos uma pesquisa nos motores de busca da internet, recebemos como resultado um grande volume de dados. Por exemplo: ao procurarmos informações sobre certificações em banco de dados, encontramos uma vasta quantidade de conteúdo disponível on-line, com a qual precisamos lidar. Para tornar essas pesquisas mais eficientes, os desenvolvedores web utilizam recursos como palavras-chave, que servem como referência para encontrarmos o conteúdo mais relevante para nós, de forma mais rápida.
Da mesma maneira, em um banco de dados, existem recursos que permitem desenvolver índices, realizar buscas textuais e criar visões. Esses recursos melhoram a qualidade das buscas de informações em diversas tabelas, algo semelhante ao que ocorre nos motores de busca da internet.
Para contextualizar seu aprendizado, retomemos a situação-problema das aulas anteriores: você está trabalhando em uma empresa que presta serviços para uma loja de jogos especializada em consoles e computadores de última geração. A loja, que vem crescendo e se popularizando, está com cada vez mais clientes.
Ao utilizarem o banco de dados da loja, os funcionários responsáveis pelo monitoramento do desempenho do sistema notaram uma significativa lentidão ao executarem consultas, nos tokens de autoatendimento, para gerar relatórios sobre os jogos disponíveis. Esses relatórios incluem informações importantes como o nome do jogo, a localização (seção/prateleira) e o preço. Após receber essa notificação, foi solicitado a você que desenvolvesse uma solução para resolver esse problema.
Diante disso, nesta aula, você aprenderá a implementar visões e índices nos bancos de dados, visando otimizar o desempenho e melhorar a eficiência das consultas realizadas na loja de jogos.
Bons estudos!
Vamos Começar!
Definição e utilização de visões de tabelas
Até aqui, estudante, você explorou algumas técnicas de consultas avançadas utilizando a linguagem de consulta estruturada (SQL). No entanto, à medida que as consultas se tornam mais complexas, é natural que ocorra um aumento na carga de processamento. Por isso, torna-se necessário adotar técnicas que permitam um uso mais eficiente dos recursos disponíveis.
Para ilustrar a aplicação dos conceitos discutidos nesta aula, consideremos o exemplo de um banco de dados representado no diagrama de entidade-relacionamento (DER) da Figura 1.
O código para implementar esse banco de dados está descrito no Quadro 1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | CREATE DATABASE Car; USE Car; CREATE TABLE Fabricante ( Codigo INT(3) PRIMARY KEY AUTO_INCREMENT, Marca CHAR(20) NOT NULL ); CREATE TABLE Veiculo ( RENAVAN INT(8) PRIMARY KEY, Nome VARCHAR(30) NOT NULL, Cor VARCHAR(20) NOT NULL, Preco DECIMAL(10,2) NOT NULL, Fabricante_Codigo INT(3) NOT NULL, FOREIGN KEY (Fabricante_Codigo) REFERENCES Fabricante (Codigo) );
INSERT INTO Fabricante VALUES (0, 'Volk'), (0, 'Fait'), (0, 'Chervroles'), (0, 'Fordys'), (0, 'Maudi'), (0, 'Junday');
INSERT INTO Veiculo (RENAVAN, Nome, Cor, Preco, Fabricante_Codigo) VALUES (1234567, 'Cersas', 'azul', 15000.00, 3), (1444558, 'Já', 'verde', 49000.00, 4), (2582582, 'Montanha', 'lilas', 62000.00, 3), (2589967, 'Hideas', 'prata', 44000.00, 2), (4445566, 'AAR5', 'azul', 80000.00, 5), (10102020, 'Cheveiro', 'preto', 22000.00, 1), (11111111, 'EspacialFex', 'amarelo', 39000.00, 1), (11122255, '10S', 'preto', 33000.00, 3), (12312312, 'Cersas', 'rosa', 18000.00, 3), (12345678, 'AAR3', 'prata', 144000.00, 5), (14714714, 'Jatus', 'prata', 145000.00, 1), (22222222, 'Seniel', 'preto', 18000.00, 2), (30303030, 'Estradus', 'preto', 127000.00, 2), (33333333, 'Pins', 'preto', 140000.00, 3), (36544477, 'Linearrr', 'prata', 135000.00, 2), (44444444, 'Pins', 'prata', 138000.00, 3), (45645645, 'Hideas', 'branco', 142000.00, 2), (55220044, 'Festinnn', 'branco', 125000.00, 4), (65465465, 'AAR3', 'verde', 154000.00, 5), (66666666, 'Já', 'preto', 119000.00, 4), (74174174, '10S', 'azul', 123000.00, 3), (77889966, 'Montanha', 'preto', 32000.00, 3), (78889994, 'Jatus', 'prata', 155000.00, 1), (78978998, 'Golos', 'dourado', 82000.00, 1), (85285285, 'Linearrr', 'amarelo', 55000.00, 2), (87654321, 'Golos', 'azul', 32000.00, 1), (95195195, 'Golos', 'preto', 18000.00, 1), (96396396, 'Festinnn', 'marrom', 25000.00, 4), (98798798, 'AAR5', 'blindado', 40000.00, 5); |
Quadro 1 | Script de criação de BD e tabelas, juntamente com as respectivas inserções de dados.Fonte: elaborado pelo autor.
Agora que o banco de dados foi criado e os registros foram inseridos, podemos explorar os conceitos de visões (VIEW) em banco de dados. As visões são uma ferramenta do SQL que oferece uma maneira alternativa de visualizar os dados de uma ou mais tabelas de um banco de dados. Uma visão pode ser considerada como uma "tabela virtual" ou uma consulta predefinida, armazenada no banco de dados por meio de scripts. Normalmente, uma visão encapsula uma consulta de seleção (SELECT), e os dados resultantes são armazenados em cache pelo sistema de gerenciamento de banco de dados (SGBD). É importante ressaltar que o cache é uma área de memória temporária que facilita o acesso rápido aos dados, semelhante ao cache de memória usado pelos navegadores da web.
Uma das vantagens da utilização de visões é a redução da carga de processamento. Isso ocorre porque as consultas feitas através de uma visão tendem a ser mais rápidas e exigem menos processamento, uma vez que os resultados da consulta já estão armazenados previamente. No entanto, surge a dúvida sobre como as visões lidam com as alterações, inserções ou exclusões nos dados subjacentes. O sistema de gerenciamento de banco de dados é responsável por atualizar automaticamente as visões sempre que houver alterações nas tabelas originais.
A sintaxe para criar uma visão é a seguinte:
CREATE VIEW [nome_da_VIEW] AS SELECT [coluna] FROM [tabela] WHERE [condições]; |
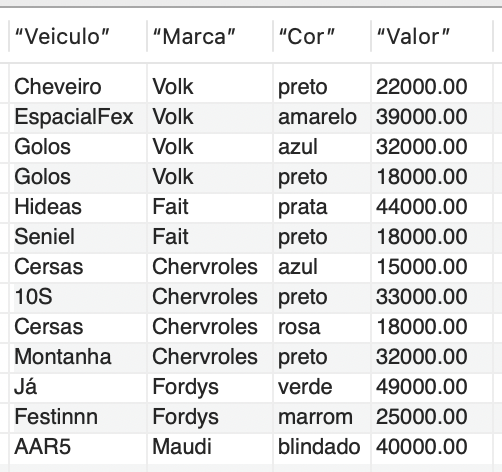
A partir do contexto estabelecido, vamos criar uma VIEW que selecionará o fabricante, o nome, a cor e o preço de um veículo quando o valor for inferior a R$ 50.000,00. Para isso, utilizaremos a seguinte sintaxe:
CREATE VIEW v_select1 AS SELECT veiculo.nome as “Veiculo”, fabricante.marca as “Marca”, veiculo.cor as “Cor”, veiculo.preco as “Valor” FROM veiculo INNER JOIN fabricante WHERE veiculo.fabricante_Codigo = fabricante.Codigo AND veiculo.preco <= 50000; |
Lembre-se de que as VIEWs são consideradas "tabelas virtuais". Para visualizá-las, basta listar as tabelas inseridas no banco de dados utilizando a sintaxe SHOW TABLES, conforme exemplificado na Figura 2.

Observe que os nomes atribuídos aos bancos de dados, às tabelas e às colunas seguem as convenções comuns de muitas linguagens de programação, segundo as quais não é permitido começar com números ou caracteres especiais e deve-se evitar palavras reservadas. Além disso, é uma boa prática nomear as VIEWs com o prefixo "v_" seguido do nome da VIEW, pois isso facilita a identificação e a diferenciação entre tabelas e VIEWs durante a consulta no banco de dados.
Para empregar uma VIEW e visualizar uma consulta, é necessário seguir a seguinte sintaxe:
| SELECT * FROM [nome_da_VIEW]; |
No exemplo previamente elaborado, isso seria exemplificado da seguinte maneira:
| SELECT * FROM v_select1; |
Tal comando resultaria na saída apresentada na Figura 3.
Para remover uma VIEW, a sintaxe adequada é:
| DROP VIEW [nome_da_VIEW]; |
As vantagens de usar VIEWs são as seguintes:
- Economia de tempo: ao utilizar VIEWs, há uma redução no tempo gasto para criar comandos SELECT com propósitos semelhantes, pois é possível acessar os dados já armazenados na tabela virtual.
- Acesso mais rápido: como as VIEWs são armazenadas previamente, o processamento necessário é menor, o que resulta em uma resposta mais rápida para o usuário.
- Ocultação da complexidade: do ponto de vista do usuário, não é necessário ter conhecimento da quantidade ou de quais campos existem em um banco de dados, nem como eles são selecionados.
É importante destacar a distinção entre a vantagem de processamento de um SELECT e de uma VIEW. Isso se torna evidente em grandes bancos de dados, como os encontrados em supermercados, sites de vendas, entre outros. Como a quantidade de verificações que o SQL precisa realizar é considerável, a escolha entre uma técnica e outra para selecionar dados pode ter um impacto significativo no desempenho das consultas.
Siga em Frente...
Índices em bancos de dados relacionais
Antes de abordarmos diretamente o conceito de índice, relembremos o mecanismo utilizado para realizar consultas em bancos de dados: quando uma seleção de dados é executada, o SGBD realiza uma verificação de similaridade em um ou mais campos, conhecida como Table Scan. Como já discutido anteriormente, em tabelas com milhares de registros, o tempo necessário para essa verificação pode ser bastante longo, o que compromete a qualidade do serviço (QoS – Quality of Service).
A utilização de índices é opcional para a seleção de dados, uma vez que são considerados estruturas redundantes. O SGBD pode decidir quais índices devem ser criados, embora nem sempre essa escolha automatizada resulte em benefícios no processamento.
Uma analogia que pode ajudar na compreensão desse recurso são os índices encontrados em livros ou revistas. Ao buscar um assunto específico, um leitor pode consultar o índice, que nada mais é do que uma lista ordenada que fornece as referências cruzadas de página e conteúdo. Desse modo, é mais fácil e rápido para o leitor localizar as informações em meio a tantas páginas, dados e informações. Esse processo se assemelha bastante ao uso de índices em bancos de dados.
O recurso de índice (INDEX, no MySQL) não era admitido até a versão SQL:1999. Posteriormente, os engenheiros buscaram um recurso para reduzir a taxa de processamento nas buscas nas tabelas e para impor restrições de integridade. Com isso, por meio da palavra reservada INDEX, devemos utilizar as seguintes sintaxes:
Para declarar um índice durante o desenvolvimento da tabela:
CREATE TABLE [nomeDaTabela] ( Campo1 tipo(tamanho), Campo2 tipo(tamanho), INDEX(Campo1) ); |
Para declarar um índice em uma tabela existente no BD:
CREATE TABLE [nomeDoIndice] ON [nomeDaTabela](Campo); |
A fim de facilitar a compreensão da sintaxe SQL para índices, criaremos um índice na chave primária RENAVAM (Registro Nacional de Veículos Automotores) da tabela veículo, a partir do exemplo utilizado nesta aula. Para isso, utilizaremos a sintaxe SQL apresentada a seguir:
CREATE INDEX idx_Renavam ON veiculo(RENAVAM); |
Embora o MySQL retorne a mensagem “Query OK, 0 rows affected”, para nos certificarmos de que os índices foram criados, é necessário utilizar a seguinte sintaxe:
| SHOW INDEX FROM [nomeDaTabela]; |
Ao efetuar a consulta no exemplo desenvolvido, podemos observar o resultado na Figura 4.
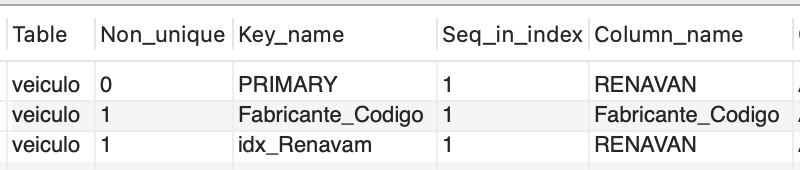
Você provavelmente notou que, na terceira linha, há uma chave denominada “idx_Renavam”. Assim como nas VIEWs, os nomes dos índices também devem seguir uma convenção de nomenclatura, que inclui um prefixo, visando a uma identificação clara. Embora o uso do prefixo nos nomes não seja obrigatório, é uma prática recomendada no cotidiano, pois ajuda a evitar confusões entre os recursos desenvolvidos. Para empregar um índice, a sintaxe necessária é a seguinte:
SELECT [coluna] FROM [nomeDaTabela] USE INDEX (nomeDoIndice) WHERE [condições]; |
No exemplo fornecido, teríamos:
SELECT nome AS “Veiculo”, cor AS “Cor”, preco AS “Valor” FROM veiculo USE INDEX(idx_Renavam) WHERE preco <= 50000; |
O resultado desse comando está representado na Figura 5.
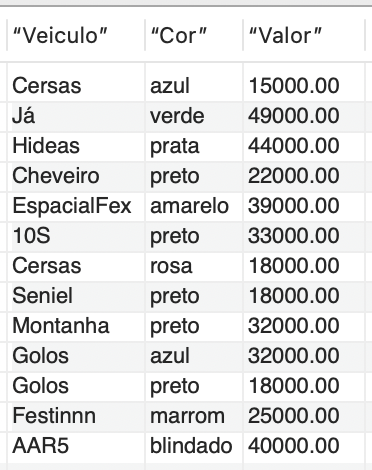
Quando empregados em um SELECT, os índices podem incorporar uma série de recursos, incluindo junções, funções agregadas, subconsultas e quaisquer outras técnicas do SQL que se mostrem necessárias. Isso se deve ao fato de que o propósito de criar um índice é aprimorar a eficiência das consultas, permitindo, assim, a utilização de uma ampla gama de recursos para a consulta.
Para excluir um índice, a sintaxe utilizada é a seguinte:
| DROP INDEX (nomeDoIndice); |
FULLTEXT em banco de dados relacional
Outro recurso que desempenha uma função semelhante à do índice é o FULLTEXT, que tem a capacidade de buscar trechos dentro de várias strings e de funcionar de maneira semelhante à função "localizar" de navegadores de internet, editores de texto, entre outros. Para habilitar esse recurso, utiliza-se a seguinte sintaxe:
| ALTER TABLE [nome_tabela] ADD FULLTEXT (nome_da_coluna); |
Ao especificar uma coluna como FULLTEXT com esse comando, o sistema passa a monitorar as strings dentro do texto dessa coluna.
A fim de utilizar esse recurso, emprega-se a seguinte sintaxe:
SELECT [coluna] FROM nome_da_tabela WHERE MATCH(coluna) AGAINST('palavra_desejada'); |
Isso possibilita a busca por palavras dentro de textos extensos, nos quais:
`MATCH(coluna)`: informa ao sistema de gerenciamento de banco de dados a coluna que deve ser usada na consulta FULLTEXT.
`AGAINST('palavra_desejada')`: especifica ao sistema de gerenciamento de banco de dados a palavra-chave a ser buscada no FULLTEXT.
Para exemplificar o uso do FULLTEXT nesse banco de dados, podemos criar um índice na coluna `Nome` da tabela Veículo para permitir buscas eficientes por modelos de veículos.
O comando para adicionar um índice FULLTEXT seria:
| ALTER TABLE Veiculo ADD FULLTEXT (Nome); |
Depois de criar o índice FULLTEXT, podemos fazer uma consulta para encontrar todos os veículos cujo nome contenha a palavra "Jatus", por exemplo. Podemos fazer isso da seguinte maneira:
| SELECT * FROM Veiculo WHERE MATCH(Nome) AGAINST('Jatus'); |
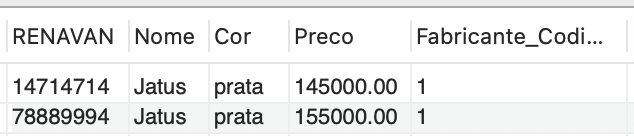
Essa consulta retornará todos os veículos cujo nome contenha a palavra "Jatus", conforme aparece na Figura 6. Essa abordagem é útil quando queremos realizar buscas em campos de texto extensos de forma eficiente e rápida, especialmente em casos nos quais precisamos encontrar correspondências parciais ou semelhantes em uma grande quantidade de dados.
Vamos Exercitar?
Como funcionário do departamento de TI de uma loja de jogos, você ficou encarregado de todas as questões relacionadas aos bancos de dados dela. Recentemente, os atendentes de vendas relataram lentidão no sistema ao consultar detalhes dos jogos disponíveis. Esses relatos foram encaminhados ao seu departamento, e agora você precisa encontrar uma solução para melhorar a performance do sistema.
Ao examinar os scripts do sistema, você descobriu que atualmente as consultas nos tokens são realizadas através do seguinte comando:
SELECT localizacao.secao, localizacao.prateleira, jogo.nome, jogo.valor FROM localizacao LEFT JOIN jogo ON localizacao.Id = jogo.localizacao_Id ORDER BY jogo.nome ASC; |
Para solucionar o problema de lentidão, você pode optar pelo uso de VIEWS, criando uma visão (VIEW) com todos os dados dos jogos, conforme o código a seguir:
CREATE VIEW v_consultaJogos AS SELECT localizacao.secao, localizacao.prateleira, jogo.nome, jogo.valor FROM localizacao LEFT JOIN jogo ON localizacao.Id = jogo.localizacao_Id ORDER BY jogo.nome ASC; |
Dessa forma, pode utilizar a VIEW desenvolvida por meio do comando SQL representado a seguir:
| SELECT * FROM v_ consultaJogos; |
Essa sintaxe gerará a saída representada na Figura 7.

Observe que a Figura 7 apresenta uma captura de tela do LOG do MySQL Workbench, no qual se pode verificar o tempo de execução de cada comando na coluna Duration / Fetch Time. Ao empregar o comando SELECT (linha 1), o tempo de resposta foi de 0.0021 segundos. Por outro lado, ao utilizar a VIEW, o tempo de resposta foi reduzido para 0,0013 segundos. Com isso, o objetivo de diminuir o tempo de resposta e a carga de processamento na geração do relatório, conforme apontado na reclamação do departamento de vendas, foi alcançado.
Saiba Mais
Para complementar o estudo de visões, leia o capítulo 4 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. iE-book. cap. 4, p. 74-77.
Recomendamos também uma visita ao seguinte site, que apresentam, de forma bem intuitiva, um complemento ao estudo sobre índices. Ele oferece mais exemplos para enriquecer o seu entendimento.
WAGNER. Entendendo e usando índices. DevMedia, Rio de Janeiro, 2007.
Já a página a seguir, do mesmo site, explica detalhadamente o uso de índices FULLTEXT.
REINALDO. Índices FULLTEXT no MySQL. DevMedia, Rio de Janeiro, 2008.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
REINALDO. Índices FULLTEXT no MySQL. DevMedia, Rio de Janeiro, 2008. Disponível em: https://www.devmedia.com.br/indices-fulltext-no-mysql/7631. Acesso em: 13 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
WAGNER. Entendendo e usando índices. DevMedia, Rio de Janeiro, 2007. Disponível em: https://www.devmedia.com.br/entendendo-e-usando-indices/6567. Acesso em: 13 fev. 2024.
Encerramento da Unidade
CONSULTAS AVANÇADAS COM SQL
Videoaula de Encerramento
Olá, estudante! Nesta videoaula, você explorará consultas avançadas com SQL, logo descobrirá como realizar junções entre tabelas, aplicar funções de agregação, criar subconsultas aninhadas e utilizar visões e índices para otimizar suas consultas.
Esses conteúdos são essenciais para a sua prática profissional, pois permitem extrair informações complexas de bancos de dados de forma eficiente e organizada. Prepare-se para aprofundar seus conhecimentos e elevar sua habilidade em SQL!
Vamos lá!
Ponto de Chegada
Olá, estudante! Para desenvolver a competência desta unidade, que é conhecer recursos de consultas avançadas realizadas em um banco de dados, você, primeiramente, teve de estudar os conceitos fundamentais relacionados a junções, funções de agregação, subconsultas aninhadas, visões e índices.
Ao longo desse percurso, aprendeu que as junções em banco de dados são essenciais para combinar dados de múltiplas fontes, permitindo-lhe obter informações detalhadas a partir de diferentes tabelas. Além disso, compreendeu como utilizar junções de forma eficaz é fundamental para realizar consultas avançadas que envolvem dados distribuídos em várias tabelas.
Já com relação às funções de agregação, você aprendeu que são muito utilizadas para calcular as estatísticas dos dados, como médias, somas, mínimos e máximos. Elas permitem resumir grandes conjuntos de dados e extrair informações úteis para análises estatísticas mais detalhadas.
Você viu ainda que as subconsultas aninhadas são úteis para refinar consultas complexas, permitindo filtrar e selecionar dados de maneira mais detalhada. Com subconsultas aninhadas, você pode realizar consultas dentro de outras consultas, o que facilita a obtenção de resultados específicos e personalizados.
Por fim, você estudou que as visões e índices são recursos importantes para facilitar o acesso aos dados e otimizar o desempenho das consultas. As visões permitem criar consultas predefinidas que podem ser acessadas como se fossem tabelas, enquanto os índices ajudam a acelerar a recuperação de dados ao criar estruturas de pesquisa otimizadas.
É Hora de Praticar!
Considere o banco de dados de uma loja de eletrônicos que contém as seguintes tabelas:
Produtos: contém informações sobre os produtos disponíveis na loja, incluindo ID, nome, categoria e preço do produto.
Vendas: registra as vendas realizadas, incluindo ID da venda, ID do produto vendido, quantidade vendida e data da venda.
O Script SQL para gerar essas tabelas é o seguinte:
CREATE TABLE Produtos ( id_produto INT AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(100), categoria VARCHAR(50), preco DECIMAL(10, 2) );
CREATE TABLE Vendas ( id_venda INT AUTO_INCREMENT PRIMARY KEY, id_produto INT, quantidade INT, data_venda DATE, FOREIGN KEY (id_produto) REFERENCES Produtos(id_produto) ); |
A loja deseja realizar uma análise abrangente das vendas e do estoque, incluindo o total de vendas realizadas, o valor total delas, o produto mais vendido e a quantidade atual em estoque de cada produto.
Para isso, você foi contratado para escrever consultas SQL que retornem as seguintes informações:
- O total de vendas realizadas.
- O valor total das vendas.
- O produto mais vendido (nome e quantidade vendida).
- A quantidade atual em estoque de cada produto.
Como resolver este caso?
*Se preferir, insira dados fictícios, a seu critério, a fim de ajudar nos testes para resolver esta questão.
Reflita
- Como as junções podem ser utilizadas para combinar dados de diferentes tabelas em um banco de dados?
- Qual a importância das funções de agregação na análise de conjuntos de dados grandes?
- Quando um desenvolvedor ou administrador de banco de dados deve utilizar um índice em uma tabela?
Resolução do estudo de caso
A fim de identificar o total de vendas realizadas, utilizamos a função de agregação COUNT(*), que conta o número total de registros na tabela de vendas.
SELECT COUNT(*) AS Total_de_Vendas FROM Vendas; |
Para verificar o valor total de vendas, multiplicamos a quantidade de cada produto pelo seu preço e depois somamos todos os valores utilizando a função de agregação SUM.
SELECT SUM(quantidade * preco) AS Valor_Total_das_Vendas FROM Vendas JOIN Produtos ON Vendas.id_produto = Produtos.id_produto; |
Agora, para identificar o produto mais vendido, utilizamos uma subconsulta aninhada, que nos ajudou a encontrar a quantidade máxima vendida. Em seguida, juntamos essa quantidade com o produto correspondente na tabela de produtos.
SELECT p.nome AS Produto, v.quantidade AS Quantidade_Vendida FROM Vendas v JOIN Produtos p ON v.id_produto = p.id_produto WHERE v.quantidade = (SELECT MAX(quantidade) FROM Vendas); |
Por fim, para verificarmos a quantidade atual em estoque de cada produto, simplesmente selecionamos o nome e a quantidade em estoque de cada produto da tabela de produtos.
SELECT p.nome AS Produto, p.estoque AS Quantidade_em_Estoque FROM Produtos p; |
Essa consulta fornece uma visão abrangente das vendas e do estoque da loja de eletrônicos, permitindo uma análise eficaz do desempenho do negócio.
Dê o play!
Assimile
O infográfico a seguir relaciona os conteúdos abordados nesta unidade:

Referências
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.