Processos e Threads
Aula 1
Processos, Conceito e Gerenciamento
Processos, conceito e gerenciamento
Estudante, esta videoaula foi preparada especialmente para você. Nela, você irá aprender conteúdos importantes para a sua formação profissional. Vamos assisti-la?
Ponto de Partida
Olá, estudante! Os processos são programas ou tarefas em execução e o sistema operacional é o responsável por administrá-los, por meio do gerenciador de processos. Existem os processos iniciados pelo usuário, como executar um editor de textos, abrir uma página na internet, abrir o aplicativo de músicas, entre outros.
Há, também, os processos iniciados por outros processos, por exemplo, uma página da internet solicitando a ajuda de outro processo para fazer o carregamento dos seus elementos. Nesta aula conheceremos o conceito, as características, a hierarquia e os estados dos processos e threads e como se dá a criação e o término de processos.
Para aprimorar seus estudos vamos analisar o seguinte caso: Um chamado foi aberto para tratar o erro do Adobe Reader, pois o programa travou e fechou inesperadamente. Lucas, durante o atendimento, reiniciou o computador para ver se resolveria o problema, porém não resolveu. Assim, o usuário questionou: por que esse erro aconteceu e por que a reinicialização do computador não resolveu o problema, mesmo tendo “matado” o processo?
Bons estudos!
Vamos Começar!
Um dos conceitos principais em sistemas operacionais gira em torno de processos. Um processo pode ser definido como um programa em execução, porém o seu conceito vai além desta definição (MACHADO; MAIA, 2007).
Nos computadores atuais, o processador funciona como uma linha de produção executando vários programas ao mesmo tempo de forma sequencial, como ler um livro on-line, baixar um arquivo e navegar na internet. A CPU é responsável por alternar os programas, executando-os por dezenas ou centenas de milissegundos, para que cada um tenha acesso ao processamento, dando a ilusão ao usuário de paralelismo ou pseudoparalelismo (TANENBAUM, 2003).
O pseudoparalelismo é a falsa impressão de que todos os programas estão sendo executados ao mesmo tempo, mas na verdade o que acontece é que um processo em execução é suspenso temporariamente para dar lugar ao processamento de outro, e assim sucessivamente.
Segundo Tanenbaum (2003), para tratar o paralelismo de forma mais fácil, foi desenvolvido um modelo responsável por organizar os programas executáveis em processos sequenciais. Um processo pode ser definido como um programa em execução incluindo os valores do contador de programa atual, registradores e variáveis. A CPU alterna de um processo para outro a cada momento, essa alternância é conhecida como multiprogramação.
A diferença entre processos e programa é importante para que o modelo seja entendido. A Para entender a diferença entre processo e programa, imaginemos o processo de fazer um bolo. Para fazer um bolo, é necessário todos os ingredientes e a receita. A receita pode ser considerada como o programa, os ingredientes são os dados de entrada e a pessoa que prepara o bolo é o processador. Os processos são as atividades que a pessoa faz durante a preparação do bolo: ler a receita, buscar os ingredientes, misturar a massa e colocar o bolo para assar, que é o processo final desse programa “receita de bolo”.
Ainda neste exemplo, imagine que o filho da pessoa que está fazendo o bolo tenha se machucado. A pessoa memoriza em que parte do processamento parou e vai socorrer o filho. Ela pega o kit de primeiros socorros e lê o procedimento para tratar do machucado do filho. Neste momento, vemos o processador (a pessoa) alternando de um processo (fazer o bolo) para outro processo com prioridade maior (socorrer o filho), cada um com seu programa – receita versus procedimento de tratamento do machucado. Assim que o filho estiver medicado, então a pessoa retornará a fazer o bolo do ponto em que parou.
Podemos considerar então que um processo é uma atividade que contém um programa, uma entrada, uma saída e um estado. Veremos a seguir a criação de processo e os estados dos processos.
Criação de processos
Os sistemas operacionais devem oferecer formas para que processos sejam criados. Segundo Tanenbaum (2003), existem quatro eventos que fazem com que um processo seja criado:
- Início do sistema: quando o sistema operacional é inicializado, são criados vários processos. Existem os de primeiro plano, que interagem com os usuários e suas aplicações, e os de segundo plano, que possuem uma função específica, como um processo para atualizar e-mails quando alguma mensagem é recebida na caixa de entrada. Para visualizar os processos em execução no Windows, pressione as teclas CTRL+ALT+DEL e no Linux utilize o comando ps.
- Execução de uma chamada ao sistema de criação por um processo em execução: por exemplo, quando um processo está fazendo download, ele aciona um outro processo para ajudá-lo. Enquanto um faz o download, o outro está armazenando os dados em disco.
- Uma requisição do usuário para criar um novo processo: quando o usuário digita um comando ou solicita a abertura de um ícone para a abertura de um aplicativo.
- Início de um job em lote: esses processos são criados em computadores de grande porte, os mainframes.
Término de processos
Após a criação, os processos podem ser finalizados nas seguintes condições, (TANENBAUM, 2003):
- Saída normal (voluntária): acontece quando o processo acaba de executar por ter concluído seu trabalho.
- Saída por erro (voluntária): acontece quando o processo tenta acessar um arquivo que não existe e é emitida uma chamada de saída do sistema. Em alguns casos, uma caixa de diálogo é aberta perguntando ao usuário se ele quer tentar novamente.
- Erro fatal (involuntário): acontece quando ocorre um erro de programa, como a execução ilegal de uma instrução ou a divisão de um número por zero. Neste caso, existe um processo com prioridade máxima que supervisiona os demais processos e impede a continuação do processo em situação ilegal.
- Cancelamento por um outro processo: acontece quando um processo que possui permissão emite uma chamada ao sistema para cancelar outro processo.
Hierarquia de processos
Segundo Tanenbaum (2003), em alguns sistemas, quando um processo cria outro, o processo-pai e o processo-filho ficam associados. O filho pode gerar outros processos, criando, assim, uma hierarquia de processos.
No Unix, um processo-pai, seus filhos e descendentes formam um grupo de processos. Por exemplo, quando um usuário envia um sinal do teclado (como CTRL + ALT + DEL), este sinal é entregue para todos os processos que compõem o grupo de processos do teclado. Quando um processo-pai é “morto”, todos os filhos vinculados a ele são “mortos” também.
O Windows não possui uma hierarquia de processos. Cada um possui um identificador próprio e quando um processo cria outro, existe uma ligação entre eles, mas ela é quebrada quando o processo- pai passa seu identificador para outro processo. Quando um processo- pai é “morto”, os processos vinculados a ele não são mortos.
Estados do Processo
Os processos podem passar por diferentes estados ao longo do processamento. Um processo ativo pode estar em três estados (MACHADO; MAIA, 2007):
- Em execução: um processo está em execução quando está sendo processado pela CPU. Os processos são alternados para a utilização do processador.
- Pronto: um processo está no estado de pronto quando possui todas as condições necessárias para executar e está aguardando. O sistema operacional é quem define a ordem e os critérios para execução dos processos.
- Espera ou bloqueado: um processo está no estado de espera quando aguarda por um evento externo (um comando do usuário, por exemplo) ou por um recurso (uma informação de um dispositivo de entrada/saída, por exemplo) para executar.
Quatro mudanças podem acontecer entre os estados, representadas na Figura 1.
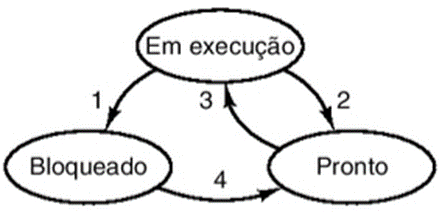
Conforme apresentado na Figura 1, a mudança 1 (“Em execução” para “Bloqueado”) acontece quando um processo aguarda um evento externo ou uma operação de entrada/saída e não consegue continuar o processamento.
As mudanças 2 (“Em execução” para “Pronto”) e 3 (“Pronto” para “Em Execução”) são realizadas pelo escalonador sem que o processo saiba. O escalonador de processos é o responsável por decidir em qual momento cada processo será executado. A mudança 2 acontece quando o escalonador decide que o processo já teve tempo suficiente em execução e escolhe outro processo para executar. A mudança 3 ocorre quando os demais processos já utilizaram o seu tempo de CPU e o escalonador permite a execução do processo que estava aguardando.
A mudança 4 (“Bloqueado” para “Pronto”) ocorre quando a operação de entrada/saída ou o evento externo que o processo estava esperando ocorre. Assim, o processo retorna para a fila de processamento e aguarda novamente a sua vez de executar.
Implementação de processos
Para implementar o modelo de processos, o sistema operacional mantém um quadro de processos contendo informações sobre o estado do processo, seu contador de programa, o ponteiro da pilha, a alocação de memória, o status dos arquivos abertos, entre outros, que permitem que o processo reinicie do ponto em que parou (TANENBAUM, 2003).
Siga em Frente...
Threads
Segundo Machado e Maia (2007), o conceito de thread foi introduzido para reduzir o tempo gasto na criação, eliminação e troca de contexto de processos nas aplicações concorrentes, assim economizando recursos do sistema como um todo.
Thread é um fluxo de controle (execução) dentro do processo, chamado também de processos leves. Um processo pode conter um ou vários threads que compartilham os recursos do processo.
A principal razão para o uso de thread é que as aplicações da atualidade rodam muitas atividades ao mesmo tempo e quando são compostas por threads, podem ser executadas em paralelo.
Outro motivo para a sua criação é que são mais fáceis de criar e destruir, por não terem recursos vinculados a eles. Em relação ao desempenho, quando uma aplicação processa muitas informações de entrada/saída, o uso de threads acelera a execução da aplicação.
Para entender melhor o exemplo do uso de thread é em um navegador web, enquanto um thread carrega imagens ou textos de uma página e outro recupera dados de uma rede.
Implementação de Threads
A implementação de threads pode ocorrer no espaço do usuário, no núcleo do sistema operacional e em uma implementação híbrida (no espaço do usuário e do núcleo).
- Thread de usuário: são implementados pela aplicação do usuário e o sistema operacional não sabe de sua existência. A vantagem é que não é necessária nenhuma mudança entre os modos de usuário e núcleo, tornando-se rápido e eficiente.
- Thread do núcleo: são implementados e gerenciados pelo núcleo do sistema operacional. A desvantagem desta implementação é que todo o gerenciamento dos threads é feito por chamadas ao sistema, o que compromete a performance do sistema.
- Threads híbridos: são implementados tanto no espaço do usuário, quanto no núcleo do sistema operacional. O sistema operacional sabe dos threads do usuário e faz o seu gerenciamento. A vantagem desta implementação é a flexibilidade em função das duas implementações.
Vamos Exercitar?
Erro fatal ao abrir um software
Vamos retomar agora o caso apresentado no início da aula: um chamado foi aberto para tratar o erro do Adobe Reader, pois o programa travou e fechou inesperadamente. Lucas, durante o atendimento, reiniciou o computador para ver se resolveria o problema, porém não resolveu. Assim, o usuário questionou: por que esse erro aconteceu e por que a reinicialização do computador não resolveu o problema, mesmo tendo “matado” o processo?
Vamos à resolução?
O travamento e o fechamento inesperado de softwares podem acontecer por vários motivos, como conflito de hardware e software e dados corrompidos em arquivos. Nem sempre reiniciar o computador resolverá o problema.
No caso relatado pelo usuário em relação ao travamento e ao fechamento inesperado do Adobe Reader, alguns processos de segundo plano, quando executados juntamente com ele, podem causar erros. É necessário fechar esses processos de segundo plano e reiniciar o computador para que o programa seja executado.
Para isso, vá ao Gerenciador de Tarefas, clique na aba Processos, selecione o processo e clique em Finalizar processo. Após essa ação, reinicie o computador e abra novamente o Adobe Reader.
Saiba Mais
Algumas linguagens de programação da atualidade, como Java, possuem recursos para a implantação de threads, chamados programação concorrente. Para saber mais sobre esse assunto, leia o artigo: Trabalhando com Threads em Java.
Referências Bibliográficas
LANHELLAS, R. Trabalhando com Threads em Java. DEVMEDIA, [s.l.], 2013. Disponível em: https://www.devmedia.com.br/trabalhando-com-threads-em-java/28780. Acesso em: 23 out. 2018.
MACHADO, F. B.; MAIA, L. P. Arquitetura de Sistemas Operacionais. 4. ed. Rio de Janeiro: LTC, 2007.
TANENBAUM, A. S. Sistemas Operacionais Modernos, 2. ed. São Paulo: Pearson, 2003.
Aula 2
Comunicação entre Processos, Mecanismos e Sincronização
Comunicação entre processos, mecanismos e sincronização
Estudante, esta videoaula foi preparada especialmente para você. Nela, você irá aprender conteúdos importantes para a sua formação profissional. Vamos assisti-la?
Ponto de Partida
Olá, estudante! Em um sistema operacional, os processos e threads trocam informações entre si ou solicitam a utilização de recursos simultaneamente, como arquivos, dispositivos de entrada/saída e memória.
Um exemplo de comunicação interprocessos é a transferência de dados entre processos. Se um processo deseja imprimir um arquivo, ele o insere em um diretório de impressão com um nome para identificá-lo e outro processo é responsável por verificar periodicamente se existem arquivos a serem impressos.
Nesta aula, entenderemos como é feita a comunicação entre processos e threads. Veremos alguns pontos sobre essa comunicação, como condições de disputa, regiões críticas e exclusão mútua com espera ociosa.
Além disso, estudaremos os mecanismos de sincronização que resolvem a exclusão mútua: dormir e acordar, semáforos, monitores e troca de mensagens.
Conheceremos mais sobre comunicação entre processos, mecanismos e sincronização.
Para aprimorar sua aprendizagem vamos analisar o seguinte caso: um estagiário que trabalha na área de Tecnologia da Informação da empresa prestadora de serviços hospitalares comentou com Lucas que um de seus colegas é o responsável pelo monitoramento do sistema de vendas de ingressos para a Copa do Mundo de 2018. O estagiário comentou sobre a falha no sistema que ocasionou a venda duplicada de ingresso, problema que ocorreu em um ponto de venda de ingressos no Rio de Janeiro e em outro em Nova York (EUA). Tanto o vendedor do Rio de Janeiro quanto o de Nova York viram que o último ingresso para a partida entre Brasil e Estados Unidos estava disponível para a venda, então, ambos venderam o ingresso aos torcedores. Diante da situação relatada pelo colega do estagiário, o SAC do sistema de vendas de ingressos foi acionado e a falha foi reportada à empresa desenvolvedora do software. O estagiário fez as seguintes perguntas para Lucas: por que ocorreu a condição de disputa, uma vez que os vendedores são de países diferentes? Como garantir que essa condição não aconteça?
Bons estudos!
Vamos Começar!
Em uma aplicação concorrente (execução cooperativa de processos e threads), os processos precisam se comunicar entre eles, então solicitam o uso de recursos como memória, arquivos, dispositivos de entrada/saída e registros. Por exemplo, uma região de memória é compartilhada entre vários processos. O sistema operacional deve garantir que esta comunicação seja sincronizada para manter o bom funcionamento do sistema e a execução correta das aplicações.
Segundo Tanenbaum (2003), é necessário levar em consideração três tópicos:
- Como um processo passa a informação para outro processo.
- Garantir que dois ou mais processos não invadam uns aos outros quando estão em regiões críticas (será detalhada no decorrer da seção). Quando um processo estiver usando uma região de memória, o outro processo deve aguardar a sua vez.
- É necessário existir uma hierarquia quando houver dependências. Se o processo A produz dados e o processo B os imprime, B deve esperar até que A produza dados para serem impressos.
Condições de disputa ou condições de corrida
Condições de disputa ou condições de corrida acontecem quando dois ou mais processos estão compartilhando alguma região da memória (lendo ou escrevendo dados) e o resultado final depende das informações de quem executa e quando.
Como exemplo, podemos citar o problema da Conta_Corrente relatado por Machado e Maia (2007). Nesta situação, o saldo bancário de um cliente é atualizado por meio de um programa após o lançamento de um débito ou crédito no arquivo de contas correntes (neste arquivo são armazenadas informações sobre o saldo dos correntistas do banco). O registro do cliente e o valor depositado ou sacado são lidos por um programa e o saldo do cliente é atualizado. Suponha que dois funcionários do banco atualizem o saldo do mesmo cliente simultaneamente. O processo do primeiro funcionário lê o registro do cliente e soma ao saldo o valor sacado pelo cliente. Porém, antes de gravar o novo saldo no arquivo, o segundo funcionário lê o registro do mesmo cliente que está sendo atualizado e lança um crédito a ser somado ao saldo. Independentemente do processo que atualizar primeiro, o dado gravado no arquivo referente ao saldo está inconsistente.
Regiões críticas
Para impedir as condições de disputa, é necessário definir maneiras que impeçam que mais de um processo leia e escreva ao mesmo tempo na memória compartilhada. Esses métodos são chamados de exclusão mútua, ou seja, quando um processo estiver lendo ou gravando dados, sua região crítica ou processo deve esperar.
A parte do programa em que o processo acessa a memória compartilhada é chamada de região crítica ou seção crítica.
Segundo Tanenbaum (2003), para termos uma boa solução, é necessário satisfazer quatro itens:
- Dois ou mais processos jamais estarão ao mesmo tempo em suas regiões críticas.
- Não se pode afirmar nada sobre o número e a velocidade de CPUs.
- Nenhum processo que esteja executando fora de sua região crítica pode bloquear outros processos.
- Nenhum processo deve esperar sem ter uma previsão para entrar em sua região crítica.
A seguir veremos as soluções propostas para realizar a exclusão mútua: exclusão mútua com espera ociosa, dormir e acordar, semáforos, monitores e troca de mensagens.
Exclusão mútua com espera ociosa
Segundo Tanenbaum (2003), existem alguns métodos que impedem que um processo invada outro quando um deles está em sua região crítica. São eles:
Desabilitando interrupções
Nesta solução, as interrupções são desabilitadas por cada processo (qualquer parada que pode ocorrer por um evento) assim que entra em sua região crítica e ativadas novamente antes de sair dela. Desta forma, a CPU não será disponibilizada para outro processo.
Esta solução não é prudente, uma vez que, ao dar autonomia para processos, a multiprogramação fica comprometida. Se um processo, ao entrar em sua região crítica, desabilitasse as interrupções e se esquecesse de habilitá-las novamente ao sair, o sistema estaria comprometido.
Em sistemas com múltiplos processadores, a interrupção acontece em apenas um processador e os outros acessariam normalmente a memória compartilhada, comprometendo essa solução.
Variáveis de impedimento
Essa solução contém uma variável chamada lock, inicializada com o valor 0. Tanenbaum (2003) afirma que o processo testa e verifica o valor dessa variável antes de entrar na região crítica e, caso o valor seja 0, o processo o altera para 1 e entra na região crítica. Caso o valor da variável seja 1, o processo deve aguardar até que seja alterado para 0.
Variáveis de impedimento não resolvem o problema de exclusão mútua e ainda mantêm a condição de disputa. Quando o processo 1 vê o valor da variável 0 e vai para alterar o valor para entrar na região crítica, chega o processo 2 e altera o valor da variável para 1, antes de o processo 1 ter alterado. Logo, os dois processos entram, ao mesmo tempo, na região crítica.
Alternância obrigatória
Segundo Tanenbaum (2003), essa solução utiliza uma variável turn compartilhada que informa qual processo poderá entrar na região crítica (ordem). Essa variável deve ser alterada para o processo seguinte, antes de deixar a região crítica.
Suponha que dois processos desejam entrar em sua região crítica. O processo A verifica a variável turn que contém o valor 0 e entra em sua região crítica. O processo B também encontra a variável turn com o valor 0 e fica testando continuamente para verificar quando ela terá o valor 1.
O teste contínuo é chamado de espera ociosa, ou seja, quando um processo deseja entrar em sua região crítica, ele examina se sua entrada é permitida e, caso não seja, o processo fica esperando até que consiga entrar. Isso ocasiona um grande consumo de CPU, podendo impactar na performance do sistema.
Ainda, de acordo com Tanenbaum (2003), assim que o processo A deixa sua região crítica, a variável turn é atualizada para 1 e permite que o processo B entre em sua região crítica.
Suponhamos que o Processo B é mais ágil e deixa a região crítica. Os processos A e B estão fora da região crítica e turn possui o valor 0. O processo A finaliza antes de ser executado em sua região não crítica. Como o valor de turn é 0, o processo A entra de novo na região crítica, e o processo B ainda permanece na região não crítica. Ao deixar a região crítica, o processo A atualiza a variável turn com o valor 1 e entra em sua região não crítica.
Os processos A e B estão executando na região não crítica e o valor da variável turn é 1. Se o processo A tentar entrar de novo na região crítica, não conseguirá, pois o valor de turn é 1. Desta forma, o processo A fica impedido pelo processo B, que NÃO está na sua região crítica. Esta situação viola a seguinte condição: nenhum processo que esteja executando fora de sua região crítica pode bloquear outros processos.
Solução de Peterson
Segundo Tanenbaum (2003), essa solução foi implementada por meio de um algoritmo que consiste em dois procedimentos escritos em C, baseado na definição de duas primitivas (enter_region e leave_region) utilizadas pelos processos que desejam utilizar sua região crítica.
Antes de entrar na região crítica, todo processo chama enter_region com os valores 0 ou 1. Esse apontamento faz com que o processo aguarde até que seja seguro entrar. Depois de finalizar a utilização da região crítica, o processo chama leave_region e permiti que outro entre. Como a solução de Alternância Obrigatória, a Solução de Peterson precisa da espera ociosa.
Instrução TSL
Tanenbaum (2003) diz que a instrução TSL (test and set lock, ou seja, teste e atualize a variável de impedimento) conta com a ajuda do hardware.
A instrução TSL RX, LOCK faz uma cópia do valor do registrador RX para LOCK. Um processo somente pode entrar em sua região crítica se o valor de LOCK for 0. A verificação do valor de LOCK e sua alteração para 0 são realizadas por instruções ordinárias.
A solução de Alternância Obrigatória, a Solução de Peterson e a instrução TSL utilizam a espera ociosa.
Siga em Frente...
Dormir e acordar
As soluções apresentadas até aqui utilizam a espera ociosa (os processos ficam em um laço ocioso até que possam entrar na região crítica). Para resolver este problema, são realizadas chamadas sleep (dormir) e wakeup (acordar) ao sistema, que bloqueiam/desbloqueiam o processo, ao invés de gastar tempo de CPU com a espera ociosa.
A chamada sleep faz com que o processo que a chamou durma até que outro processo o desperte, e a chamada wakeup acorda um processo.
Semáforos
Segundo Machado e Maia (2007), a utilização de semáforos é um dos mecanismos utilizados em projetos de sistemas operacionais e em aplicações concorrentes. Hoje, grande parte das linguagens de programação disponibiliza procedimentos para que semáforos sejam utilizados.
Um semáforo é uma variável inteira que realiza duas operações: DOWN (decrementa uma unidade ao valor do semáforo) e UP (incrementa uma unidade ao valor do semáforo). As rotinas DOWN e UP são indivisíveis e executadas no processador. Um semáforo com o valor 0 indica que nenhum sinal de acordar foi salvo e um valor maior que 0 indica que um ou mais sinais de acordar estão pendentes (TANENBAUM, 2003).
De acordo com Machado e Maia (2007), os semáforos são classificados como:
- Binários, também conhecidos como mutexes (mutual exclusion semaphores), que recebem os valores 0 ou 1.
- Contadores, que recebem qualquer valor inteiro positivo, além do 0.
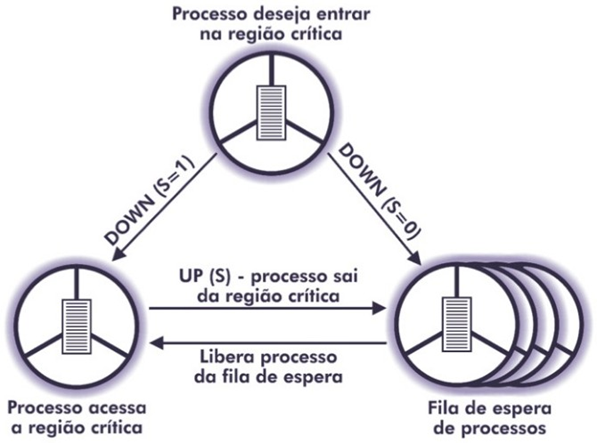
Para compreendermos melhor o uso de semáforos, utilizaremos um exemplo de semáforos binários. Machado e Maia (2007) dizem que o semáforo com o valor igual a 1 significa que nenhum recurso está utilizando o processo e valor igual a 0 significa que o recurso está em uso.
A Figura 1 apresenta o uso do semáforo binário na exclusão mútua. Quando um processo deseja entrar em sua região crítica, é executada a instrução DOWN. Caso o valor do semáforo seja igual a 1, o valor é decrementado e o processo pode entrar em sua região crítica. Caso o valor seja 0 e a operação DOWN seja executada, o processo é impedido de entrar em sua região crítica, permanecendo em fila no estado de espera.
O processo que utiliza o recurso executa a instrução UP ao deixar a região crítica incrementa o valor do semáforo e libera o acesso ao recurso. Caso existam processos aguardando na fila para serem executados, o sistema selecionará um e alterará o seu estado para pronto.
O problema do produtor/consumidor (perda de sinal de acordar) apresentado acima pode ser resolvido através de semáforos.
Monitores
Um monitor é uma coleção de rotinas, estrutura de dados e variáveis que ficam juntos em um módulo ou pacote. Também pode ser definido como uma unidade de sincronização de processos de alto nível (TANENBAUM, 2003).
Um processo, ao chamar uma rotina de um monitor, verifica se existe outro processo ativo. Caso esteja, o processo que chamou é bloqueado até que o outro deixe o monitor, senão, o processo que o chamou poderá entrar.
A utilização de monitores garante a exclusão mútua, uma vez que só um processo pode estar ativo no monitor em um determinado momento e os demais processos ficam suspensos até poderem estar ativos. O compilador é o responsável por definir a exclusão mútua nas entradas do monitor.
É preciso definir métodos para suspenderem os processos caso não possam prosseguir, mesmo que a implementação da exclusão mútua em monitores seja fácil.
Assim, é necessário introduzir variáveis condicionais, com duas operações: wait e signal. Se um método do monitor verifica que não pode prosseguir, um sinal wait é emitido (bloqueando o processo), permitindo que outro processo que estava bloqueado acesse o monitor. A linguagem de programação Java suporta monitores.
Troca de Mensagens
Segundo Tanenbaum (2003), esse método utiliza duas chamadas ao sistema:
- send (destination, &message) - envia uma mensagem para um determinado destino.
- receive (source, &message) - recebe uma mensagem de uma determinada origem.
Caso nenhuma mensagem esteja disponível, o receptor poderá ficar suspenso até chegar alguma.
A troca de mensagens possui problemas como sua perda pela rede. Para evitá-lo, assim que uma mensagem é recebida, o receptor enviará uma mensagem de confirmação de recebimento. Caso o receptor receba e não confirme o recebimento, não será problema, uma vez que as mensagens originais são numeradas de forma sequencial.
Uma questão importante refere-se à autenticação, pois é necessário saber se a fonte é real. Além disso, as mensagens enviadas e recebidas não podem ser ambíguas.
Quanto ao desempenho, copiar mensagens é um procedimento mais lento do que realizar operações sobre semáforos ou monitores. Uma solução seria realizar a troca de mensagens através de registradores.
Vamos Exercitar?
Condições de Disputa – venda de ingressos para a Copa do Mundo 2018
Vamos retomar o casa apresentado no início da aula: um estagiário que trabalha na área de Tecnologia da Informação da empresa prestadora de serviços hospitalares comentou com Lucas que um de seus colegas é o responsável pelo monitoramento do sistema de vendas de ingressos para a Copa do Mundo de 2018. O estagiário comentou sobre a falha no sistema que ocasionou a venda duplicada de ingresso, problema que ocorreu em um ponto de venda de ingressos no Rio de Janeiro e em outro em Nova York (EUA). Tanto o vendedor do Rio de Janeiro quanto o de Nova York viram que o último ingresso para a partida entre Brasil e Estados Unidos estava disponível para a venda, então, ambos venderam o ingresso aos torcedores.
Diante da situação relatada pelo colega do estagiário, o SAC do sistema de vendas de ingressos foi acionado e a falha foi reportada à empresa desenvolvedora do software. O estagiário fez as seguintes perguntas para Lucas: por que ocorreu a condição de disputa, uma vez que os vendedores são de países diferentes? Como garantir que essa condição não aconteça?
Vamos à resolução?
Em um sistema unificado de vendas, normalmente a aplicação desenvolvida deve garantir que não ocorram erros. Mesmo estando em países diferentes, a aplicação deve ser íntegra, não permitindo que problemas como a condição de disputa aconteça.
É possível que tenha ocorrido uma falta de sincronismo, ocasionando essa condição, uma vez que os pontos de venda dependem da internet. Para garantir que isso não aconteça, é necessário verificar se a solução de exclusão mútua (que garante que um processo não terá acesso a uma região crítica enquanto outro estiver utilizando essa região) foi corretamente implementada através do método escolhido pelo desenvolvedor da aplicação. Logo, é preciso ver com a empresa que desenvolveu o sistema para reportar o erro.
Saiba Mais
Para saber mais sobre o funcionamento de semáforos, veja o vídeo Me Salva Sistemas Operacionais: O que é Semáforo.
Referências Bibliográficas
MACHADO, F. B.; MAIA, L. P. Arquitetura de Sistemas Operacionais, 5. ed. São Paulo: LTC. Grupo GEN, 2007.
TANENBAUM, A. S.; WOODHULL, A. S. Sistemas operacionais. Porto Alegre: Grupo A, 2003.
Aula 3
Escalonamento de Processos e Threads: Algoritmos e Políticas
Escalonamento de processos e threads: algoritmos e políticas
Estudante, esta videoaula foi preparada especialmente para você. Nela, você irá aprender conteúdos importantes para a sua formação profissional. Vamos assisti-la?
Ponto de Partida
Olá, estudante! Em um sistema operacional, vários processos compartilham recursos ao mesmo tempo, e quem faz a escolha de qual processo deve ser executado é o escalonador, feita por meio de um algoritmo (algoritmo de escalonamento), sendo necessário seguir as seguintes premissas: dar a cada processo o tempo necessário de uso da CPU, verificar se a política estabelecida é cumprida e manter ocupadas todas as partes do sistema.
Assim, quando um processo termina sua execução, outro processo deve ser escolhido entre os que estão no estado “pronto para executar”. Nesta seção, veremos os tipos de escalonamento e seus principais algoritmos.
Conheceremos mais sobre escalonamento de processos e threads, para conseguirmos implementar um algoritmo de escalonamento de processos através de semáforos.
Para aprimorar seu aprendizado vamos analisar o caso: a empresa Souza, prestadora de serviços de TI como suporte via Service Desk e desenvolvimento de websites para pequenas e médias empresas de todos os ramos, possui filiais em Brasília, São Paulo, Rio de Janeiro e Belo Horizonte. Diariamente, ocorrem videoconferências para alinhamento de procedimentos técnicos e para tratar de assuntos específicos dos projetos de TI das empresas para as quais a Souza presta serviços. As videoconferências são realizadas por um notebook que fica na sala de reuniões. José é o técnico de TI responsável pela videoconferência da sede da Souza e observou que o tempo de resposta da videoconferência da sua filial estava muito lento. José entrou no gerenciador de tarefas do computador e identificou que o processo responsável pela videoconferência não estava executando com a prioridade correta. Observou, também, que o processo de atualização de e-mails tinha uma prioridade superior ao da videoconferência. Diante do exposto, como fazer para alterar a prioridade dos processos em execução?
Bons estudos!
Vamos Começar!
Escalonamento de Processos e os seus tipos
Segundo Tanenbaum (2003), nos computadores existem vários processos que competem pela CPU e é necessário que o sistema operacional escolha, de forma eficiente, os que estejam aptos a executar. O responsável por isso é o escalonador de processos, por meio da aplicação de algoritmos ou políticas de escalonamento para otimizar a utilização do processador, definindo o processo que ocupará a CPU.
Segundo Machado e Maia (2007), além de escolher o processo a ser executado, o escalonador deve prezar pelos critérios e pelos objetivos.
Vejamos alguns critérios:
- Utilização do processador: eficiência do uso da CPU mantendo o processador ocupado na maior parte do tempo.
- Throughput: maximizar a produtividade (throughput), executando o maior número de processos em função do tempo.
- Tempo de processador: tempo de execução do processo.
- Tempo de espera: reduzir o tempo total que um processo aguarda na fila para ser executado.
- Tempo de turnaround: minimizar o tempo que um processo leva desde sua criação até seu término, considerando a alocação de memória, tempo de espera e tempo do processador e aguardando as operações de entrada/saída.
- Tempo de resposta: reduzir o tempo de resposta para as aplicações interativas dos usuários.
Alguns dos objetivos são:
- Dar privilégios para aplicações críticas.
- Balancear o uso da CPU entre processos.
- Ser justo com todos os processos, pois todos devem poder usar o processador.
- Maximizar a produtividade (throughput).
- Proporcionar menores tempos de resposta para usuários interativos.
Diferentes sistemas operacionais apresentam características de escalonamento distintas. Podemos citar como exemplos o sistema operacional em tempo real e o de tempo compartilhado. O primeiro prioriza as aplicações críticas, enquanto o segundo aloca todos os processos com tempo igual para acesso à CPU, a fim de que os processos não esperem muito tempo para ter acesso ao processamento.
Segundo Tanenbaum (2003), alternar processos é oneroso, uma vez que é necessário alternar do modo usuário para o modo núcleo para iniciar a execução. Nessa execução, o estado do processo e o mapa de memória devem ser salvos, armazenando os dados dos registradores na tabela de processos e, a cada troca de processos, a memória cache (memória de acesso rápido) é invalidada.
As principais situações que levam ao escalonamento, segundo Tanenbaum (2003), são:
- A criação de um novo processo: é necessário escolher entre executar o processo pai ou o filho.
- O término de um processo: quando um processo é finalizado, é necessário escolher outro para ser executado.
- Bloqueio do processo: quando um processo é bloqueado e está aguardando uma entrada/saída, é necessário escolher outro processo.
- Interrupção de entrada/saída: se a interrupção for gerada por um dispositivo que finalizou a execução, o processo passará de “bloqueado” para “pronto” e o escalonador deve escolher entre continuar executando o processo atual ou o que acabou de ficar pronto.
- Interrupções de relógio: a cada interrupção do hardware de relógio pode haver um escalonamento de processos.
Em relação ao tratamento das interrupções de relógio, os algoritmos ou políticas de escalonamento são classificados em não-preemptivo e preemptivo (MACHADO; MAIA, 2007). No não-preemptivo um processo executa até finalizar, independentemente do tempo de uso da CPU, ou até que seja bloqueado aguardando entrada/saída de outro processo.
Esse escalonamento foi implementado no processamento batch. Já no escalonamento preemptivo, um processo é executado por um tempo pré-determinado e quando o tempo de execução dado ao processo finaliza, a CPU é alocada para outro processo.
No escalonamento preemptivo é possível priorizar aplicações em tempo real em função dos tempos dados aos processos. Os algoritmos de escalonamento preemptivo são complexos, porém permitem a implantação de vários critérios de escalonamento.
Segundo Tanenbaum (2003), existem três ambientes diferentes de escalonamento: lote, interativo e tempo real.
- No Lote, como não existem usuários aguardando uma resposta, tanto algoritmos preemptivos como não-preemptivos são aceitáveis para esse sistema. Os algoritmos de escalonamento aplicados para ele são:
- FIFO (First in first out): primeiro a chegar, primeiro a sair. Neste algoritmo, os processos são inseridos em uma fila à medida que são criados, e o primeiro a chegar é o primeiro a ser executado. Quando um processo bloqueia e volta ao estado de pronto, ele é colocado no final da fila e o próximo processo da fila é executado. O FIFO é um algoritmo não- preemptivo, simples e de fácil implementação.
- Job mais curto primeiro (SJF – shortest job first): é um algoritmo de escalonamento não-preemptivo, em que são conhecidos todos os tempos de execução dos jobs. O algoritmo seleciona primeiro os jobs mais curtos para serem executados. Este algoritmo é recomendado quando todos os jobs estão disponíveis ao mesmo tempo na fila de execução.
A Figura 1 (a) apresenta quatro jobs (A, B, C e D) aguardando numa fila, com os respectivos tempos de execução em minutos (8, 4, 4 e 4). Se eles forem executados nesta ordem, teremos uma média de espera de execução de 14 minutos (o retorno do job A é de 8 minutos, o retorno do B é de 12 minutos (8 + 4), o retorno do C é de 16 minutos (12 + 4) e o retorno do D é de 20 minutos (16 + 4). Logo, (8+12+16+20) / 4 = 14 minutos.
Se os jobs forem executados selecionando primeiramente o mais curto, conforme apresentado na Figura 1 (b), teremos uma média de espera de execução de 11 minutos (o retorno do B é de 4 minutos, do C é de 8 minutos (4 + 4), do D é de 12 minutos (8 + 4) e do A é de 20 minutos (12 + 8)). Logo, (4+8+12+20) / 4 = 11 minutos.

Uma versão preemptiva para o algoritmo job mais curto é, primeiro, o algoritmo próximo de menor tempo restante. O escalonador conhece os tempos de execução e escolhe sempre o job cujo tempo restante ao seu término seja o menor. Quando um novo job chega na fila para execução, seu tempo total é comparado ao tempo restante do processo que está utilizando a CPU.
Nos sistemas interativos, por sua vez, a preempção se faz necessária para que outros processos tenham acesso à CPU. Os algoritmos de escalonamento aplicados a eles e que podem também ser aplicados a sistema em lote são:
- Escalonamento Round Robin: é um algoritmo antigo, simples, justo e muito usado. Também é conhecido como algoritmo de escalonamento circular. Nele os processos são organizados em uma fila e cada um recebe um intervalo de tempo máximo (quantum) que pode executar. Se ao final de seu quantum o processo ainda estiver executando, a CPU é liberada para outro processo.
A Figura 2 (a) mostra a lista de processos que são executáveis mantida pelo escalonador. Quando um processo finaliza o seu quantum, é colocado no final da fila, conforme apresentado na Figura 2 (b).

Segundo Machado e Maia (2007), o quantum varia de acordo com a arquitetura do sistema operacional e a escolha desse valor é fundamental, uma vez que afeta a política do escalonamento circular. Os valores variam entre 10 e 100 milissegundos. O escalonamento circular é vantajoso porque não permite que um processo monopolize a CPU.
- Escalonamento por prioridades: o algoritmo por prioridades considera todos os processos importantes, sendo associados a ele uma prioridade e um tempo máximo de execução. Por exemplo, um processo que carrega os dados em uma página web deve ter uma prioridade maior do que um processo que atualiza em segundo plano as mensagens de correio eletrônico. Quando os processos estiverem disponíveis para execução, o que tiver a maior prioridade é selecionado para executar. Para que os processos com prioridades altas não sejam executados infinitamente, a cada interrupção de relógio o escalonador pode reduzir a prioridade do processo.
Machado e Maia (2007) dizem que as prioridades de execução podem ser classificadas em estática ou dinâmicas.
A prioridade estática não altera o valor enquanto o processo existir. Já a dinâmica ajusta-se de acordo com os critérios do sistema operacional, que podem ser:
- Escalonamento garantido: se existirem vários usuários (n) logados em uma máquina, cada um deles receberá 1/n do tempo total da CPU. O sistema gerencia a quantidade de tempo de CPU de cada processo desde sua criação.
- Escalonamento por loteria: o escalonamento por loteria é baseado em distribuir bilhetes aos processos e os prêmios recebidos por eles são recursos de sistema, incluindo tempo de CPU. Cada bilhete pode representar o direito a um quantum de CPU e cada processo pode receber diferentes números de bilhetes, com opções de escolha distintas. Também existem as ações como compra, venda, empréstimo e troca de bilhetes.
- Escalonamento fração justa (fair-share): nesse caso, cada usuário recebe uma fração da CPU. Por exemplo, se existem dois usuários conectados em uma máquina e um deles tiver nove processos e o outro tiver apenas um, não é justo que o usuário com o maior número de processos ganhe 90% do tempo da CPU. Logo, o escalonador é o responsável por escolher os processos que garantam a fração justa.
No sistema de tempo real, o tempo é um fator importantíssimo e os processos, ao utilizarem a CPU, fazem seu trabalho rapidamente e são bloqueados, dando oportunidade para outros processos executarem.
Machado e Maia (2007) apontam que o escalonamento por prioridades seria o mais adequado em sistemas de tempo real, uma vez que uma prioridade é vinculada ao processo e, assim, a importância das tarefas na aplicação são consideradas.
No escalonamento de tempo real, a prioridade deve ser estática, além de não existir fatia de tempo para cada processo executar.
O escalonamento de processos desempenha um papel crucial na eficiência e no desempenho de sistemas operacionais, garantindo que a CPU seja utilizada de forma eficaz, os processos sejam tratados de maneira justa e as respostas aos usuários sejam rápidas.
Cada tipo de escalonamento tem suas próprias vantagens e desvantagens, e a escolha do tipo de escalonamento depende dos requisitos do sistema e das necessidades específicas de execução de processos. Sistemas operacionais podem implementar várias políticas de escalonamento e escolher a mais apropriada com base nas circunstâncias.
Siga em Frente...
Escalonamento de Threads
O escalonamento de threads é um aspecto importante em sistemas operacionais multitarefa e multiprocessadores, pois envolve a alocação de tempo de CPU para os vários threads em execução.
Da mesma forma que processos são escalonados, threads também são. O escalonamento de threads depende se estas estão no espaço do usuário ou do núcleo. Se forem threads de usuário, o núcleo não sabe de sua existência e o sistema operacional escolhe um processo A para executar, dando a ele o controle de seu quantum. O escalonador do thread A escolhe qual deve executar, através dos algoritmos de escalonamento descritos anteriormente. Se forem threads do núcleo, o sistema operacional escolhe um thread para executar até um quantum máximo e, caso o quantum seja excedido, o thread será suspenso (TANENBAUM, 2003).
Uma das diferenças entre threads do usuário e do núcleo é o desempenho, uma vez que a alternância entre eles consome poucas instruções do computador. Além disso, os threads do usuário podem utilizar um escalonador específico para uma aplicação (TANENBAUM, 2003).
Segundo Deitel, Deitel e Choffnes (2005), na implementação de threads em Java, cada thread recebe uma prioridade. O escalonador em Java garante que o thread com prioridade maior execute o tempo todo. Caso exista mais de um thread com prioridade alta, eles serão executados através de alternância circular.
Seguem algumas considerações sobre o escalonamento de threads:
- Escalonamento de threads em nível de kernel: o escalonamento de threads pode ocorrer no nível do kernel do sistema operacional, em que o kernel é responsável por alocar tempo de CPU para asthreads. O kernel decide qual thread será executada em seguida com base em políticas de escalonamento.
- Políticas de escalonamento: as políticas de escalonamento determinam como as threads são selecionadas para execução. Alguns tipos comuns de políticas de escalonamento de threads incluem:
- Escalonamento por prioridade: cada thread tem atribuída uma prioridade e a prioridade mais alta é selecionada para execução.
- Escalonamento por round robin: os threads recebem um quantum de tempo fixo e são executadas em um ciclo circular. Isso evita que um thread monopolize a CPU.
- Mudanças de contexto: quando o escalonador seleciona uma nova thread para execução, ocorre uma troca de contexto, que envolve a interrupção dele em execução e a carga de contexto do próximo thread. Isso inclui salvar e restaurar registros de CPU, apontadores de pilha e outros contextos de thread.
- Preempção: em sistemas de tempo compartilhado, a preempção ocorre quando um thread é interrompido antes que seu tempo de execução termine. Isso garante que os de alta prioridade não sejam bloqueadas por os de baixa prioridade.
- Afinidade de threads: em sistemas multiprocessadores, pode haver considerações de afinidade de threads, em que um é executado em um núcleo específico para tirar proveito da arquitetura multi-core.
- Contenção de recursos: problemas de contenção de recursos, como semáforos ou mutex, podem afetar o escalonamento de threads. Eles podem ser bloqueadoss esperando por recursos compartilhados, o que pode resultar em ineficiência.
- Escalonamento de threads em nível de usuário: algumas linguagens de programação e bibliotecas fornecem seus próprios mecanismos de escalonamento de threads em nível de usuário. Isso permite que os aplicativos controlem o escalonamento de threads, mas geralmente é limitado em termos de paralelismo real em sistemas multiprocessadores.
O escalonamento de threads é uma parte crítica da eficiência de sistemas operacionais multitarefa, garantindo que sejam tratados de maneira justa e eficiente, evitando bloqueios e garantindo que as threads de alta prioridade recebam a atenção necessária.
Vamos Exercitar?
Escalonamento por prioridades
Vamos retomar o caso apresentado no início da aula: a empresa Souza, prestadora de serviços de TI como suporte via Service Desk e desenvolvimento de websites para pequenas e médias empresas de todos os ramos, possui filiais em Brasília, São Paulo, Rio de Janeiro e Belo Horizonte. Diariamente, ocorrem videoconferências para alinhamento de procedimentos técnicos e para tratar de assuntos específicos dos projetos de TI das empresas para as quais a Souza presta serviços. As videoconferências são realizadas por um notebook que fica na sala de reuniões. José é o técnico de TI responsável pela videoconferência da sede da Souza e observou que o tempo de resposta da videoconferência da sua filial estava muito lento.
José entrou no gerenciador de tarefas do computador e identificou que o processo responsável pela videoconferência não estava executando com a prioridade correta. Observou, também, que o processo de atualização de e-mails tinha uma prioridade superior ao da videoconferência. Diante do exposto, como fazer para alterar a prioridade dos processos em execução?
Vamos à resolução?
Um sistema de videoconferência trabalha em tempo real, sendo o tempo um fator importantíssimo. Em um computador, as prioridades são definidas pelo sistema operacional ou podem ser mudadas pelos usuários. Como relatado por José, as videoconferências são realizadas por um notebook que fica na sala de reuniões. Logo, alguém por interesse próprio alterou a prioridade da videoconferência e priorizou o processo de atualização de e-mails.
Mesmo que a videoconferência tenha prioridade sobre o processo de atualização de e-mails, se o usuário fizer a alteração de prioridade, o sistema operacional vai obedecer a ordem de prioridades definida. Para alterar a prioridade dos processos, basta seguir os seguintes passos:
No Windows: abra o Gerenciador de Tarefas e selecione o processo do qual deseja alterar a prioridade. Clique com o botão direito do mouse, selecione a opção “Definir prioridade” e clique na prioridade desejada.
Saiba Mais
O algoritmo de escalonamento FIFO (First-In, First-Out) é um dos algoritmos mais simples e diretos para a gestão de processos em um sistema operacional. Para saber mais sobre este scheduler, acesse o vídeo: SO 3: FIFO (Algoritmos de Escalonamento).
Referências Bibliográficas
DEITEL, H. M.; DEITEL, P. J.; CHOFFNES, D. R. Sistemas Operacionais. 3. ed. São Paulo: Prentice Hall, 2005.
MACHADO, F. B.; MAIA, L. P. Arquitetura de Sistemas Operacionais, 5. ed. São Paulo: LTC. Grupo GEN, 2007.
TANENBAUM, A. S.; WOODHULL, A. S. Sistemas operacionais. Porto Alegre: Grupo A, 2003.
Aula 4
Threads: Conceito e Vantagens
Threads: conceito e vantagens
Estudante, esta videoaula foi preparada especialmente para você. Nela, você irá aprender conteúdos importantes para a sua formação profissional. Vamos assisti-la?
Ponto de Partida
Olá, estudante! um thread, também conhecido como processo leve, é uma unidade menor de execução que opera dentro de um processo maior. Diferentemente dos processos, os threads compartilham o mesmo espaço de endereço de memória e recursos do processo pai. Isso os tornam mais leves em termos de recursos e permite uma comunicação direta entre eles.
Nesta aula, veremos o conceito sobre Threads, os seus modelos e a relação entre Threads e Processos.
Para aprimorar seu aprendizado vamos analisar um caso: imagine que você está encarregado de desenvolver um servidor web multithread para atender às necessidades de uma empresa que deseja hospedar vários sites e serviços on-line. Você precisa decidir qual modelo de threads é mais adequado para esse servidor.
Requisitos e considerações:
- Alta concorrência: o servidor web deve ser capaz de lidar com uma alta concorrência de solicitações de clientes simultâneas, pois muitos usuários acessarão os sites e serviços ao mesmo tempo.
- Eficiência de recursos: o servidor deve ser eficiente em termos de recursos, pois a empresa deseja otimizar o uso de CPU e memória para reduzir os custos de infraestrutura.
- Escalabilidade: como a empresa planeja expandir seus serviços, o servidor deve ser escalável para acomodar um aumento no número de clientes e solicitações.
Você deve escolher entre vários modelos de threads para implementar o servidor web. Os modelos mais comuns são many-to-one (muitos-para-um), one-to-one (um-para-um), many-to-many (muitos-para-muitos) e modelos híbridos.
Bons estudos!
Vamos Começar!
Thread é a unidade básica de execução de um programa. É um processo leve que pode ser considerado como um "subprocesso" dentro de um processo maior. Os threads permitem que um programa execute várias tarefas de forma concorrente, tornando-o mais eficiente e responsivo.
Os principais aspectos relacionados ao conceito de threads são:
- Execução concorrente: eles permitem que partes diferentes de um programa sejam executadas concorrentemente, o que pode melhorar o desempenho e a capacidade de resposta do programa. Cada thread possui seu próprio fluxo de controle e pode executar código de forma independente.
- Compartilhamento de recursos: Em um mesmo processo, eles compartilham o mesmo espaço de memória, o que facilita o compartilhamento de dados e recursos entre si. Isso também pode levar a problemas de concorrência, como condições de corrida, que precisam ser gerenciadas adequadamente.
- Criação de threads: Os sistemas operacionais e as linguagens de programação geralmente fornecem mecanismos para criar e gerenciar threads. Eles podem ser criados em um processo para realizar tarefas específicas.
- Threads e programação paralela: A programação com threads é uma forma de programação paralela, que envolve a execução de várias tarefas simultaneamente para aproveitar melhor o poder de processamento de sistemas com múltiplos núcleos de CPU.
- Tipos de threads: existem geralmente dois tipos de threads: de usuário e do kernel. Threads de usuário são criados e gerenciados pela biblioteca de threads da linguagem de programação ou pela aplicação em si, enquanto threads do kernel são criadas e gerenciadas pelo sistema operacional.
- Concorrência e sincronização: ao usar threads, é importante lidar com questões de concorrência, como a sincronização de acesso a recursos compartilhados. Mecanismos como semáforos, mutexes e semáforos binários são usados para garantir a exclusão mútua e evitar condições de corrida.
- Escalonamento de threads: O sistema operacional é responsável pelo escalonamento dos threads, decidindo quais devem ser executadas e em que ordem. Diferentes algoritmos de escalonamento podem ser usados para tomar essas decisões.
Os threads são uma ferramenta importante na programação e na criação de aplicativos que podem se beneficiar da execução concorrente de tarefas. No entanto, é fundamental ter cuidado ao usar threads, pois problemas de concorrência mal gerenciados podem levar a resultados inesperados e difíceis de depurar.
Modelos de Threads
Em sistemas operacionais, os modelos de threads referem-se às diferentes abordagens usadas para criar, gerenciar e coordenar threads (ou processos leves) dentro de um processo maior. Cada modelo tem suas próprias características e trade-offs, e a escolha do modelo apropriado depende dos requisitos específicos do sistema e do aplicativo. Alguns dos modelos de threads comuns em sistemas operacionais:
- Many-to-One (Muitos-para-Um): vários threads de nível de usuário são mapeadas para uma único thread de nível de kernel. A implementação deles, de nível de usuário, é feita inteiramente no espaço do processo do usuário, e o sistema operacional não tem conhecimento dos threads de nível de usuário. Isso torna a implementação eficiente em termos de recursos, mas limita a escalabilidade em sistemas multiprocessadores.
- One-to-One (Um-para-Um): cada thread de nível de usuário é mapeado para um único de nível de kernel. Cada thread de nível de usuário é tratado como um processo separado pelo sistema operacional. Isso permite uma paralelização mais eficiente em sistemas multiprocessadores, pois os de nível de kernel podem ser distribuídas entre os núcleos da CPU.
- Many-to-Many (Muitos-para-Muitos): vários threads de nível de usuário são mapeados para um número menor de threads de nível de kernel. A correspondência entre os de nível de usuário e os de nível de kernel é flexível. Esse modelo visa equilibrar a eficiência de recursos e a escalabilidade, permitindo que o sistema ajuste a alocação de threads de nível de kernel conforme necessário.
- Two-Level (Dois Níveis): combina aspectos dos modelos many-to-one e one-to-one. Os threads de nível de usuário são mapeados para threads de nível de kernel, mas de forma mais flexível do que a correspondência um-para-um. Isso oferece algum equilíbrio entre eficiência de recursos e escalabilidade.
- Hybrid (Híbrido): são uma mistura de várias abordagens, muitas vezes personalizadas para atender às necessidades específicas do sistema e do aplicativo. Eles podem ser projetados para combinar as vantagens de diferentes modelos, adaptando-se a diferentes situações.
A escolha do modelo de threads depende dos requisitos de desempenho, da natureza do aplicativo e das características do sistema. Modelos que são eficientes em termos de recursos podem ser adequados para sistemas embarcados, enquanto modelos que buscam alta escalabilidade podem ser preferidos em sistemas multiprocessadores. Cada modelo tem suas próprias complexidades de programação e requer sincronização adequada para evitar problemas de concorrência.
Siga em Frente...
Relação entre Threads e Processos
Threads e processos são conceitos relacionados à execução de programas em um sistema operacional, mas diferem em vários aspectos. Segue uma relação entre threads e processos:
Processos Contêm Threads:
- Um processo é uma unidade independente de execução em um sistema operacional que contém seu próprio espaço de endereço de memória, registradores e contexto de execução. Um processo pode ser visto como um programa em execução.
- Dentro de um processo, pode haver um ou mais threads. Os threads são unidades de execução menores que compartilham o mesmo espaço de endereço de memória do processo pai.
Isolamento vs. compartilhamento:
- Os processos são isolados uns dos outros, o que significa que eles não compartilham memória ou recursos diretamente. Cada processo tem seu próprio espaço de endereço de memória.
- Os threads em um processo compartilham o mesmo espaço de memória e recursos, o que as torna mais leves em termos de recursos e permite uma comunicação direta entre elas.
Criação e terminação:
- Os processos são criados e terminados de forma independente. O processo pai pode criar processos filhos que executam programas separados.
- Os threads são criados e terminados dentro de um processo existente. Um thread é geralmente uma subdivisão de um processo maior.
Sincronização e comunicação:
- A comunicação e a sincronização entre processos geralmente são mais complexas, envolvendo mecanismos como pipes, sockets ou memória compartilhada. Os processos são menos propensos a problemas de concorrência, mas a comunicação requer mais esforço.
- Os threads podem se comunicar e sincronizar mais facilmente, pois compartilham memória. Isso pode levar a problemas de concorrência, como condições de corrida, que precisam ser gerenciadas com cuidado.
Overhead:
- Criar e gerenciar processos geralmente tem um overhead mais alto em termos de consumo de recursos (CPU e memória) em comparação com threads.
- Os threads são mais leves em termos de recursos, pois compartilham recursos comuns dentro de um processo.
Escalonamento:
- Processos são escalonados pelo sistema operacional, o que pode ser mais pesado e lento, pois envolve a troca de contexto completa.
- Threads dentro de um processo podem ser escalonadas com mais eficiência, já que compartilham o mesmo espaço de memória.
Os processos são unidades de isolamento e execução independentes, enquanto as threads são unidades de execução menores que compartilham recursos dentro de um processo.
Vamos Exercitar?
Desenvolvimento de Servidor Web Multithread
Vamos retomar o caso apresentado no início da aula: imagine que você está encarregado de desenvolver um servidor web multithread para atender às necessidades de uma empresa que deseja hospedar vários sites e serviços on-line. Você precisa decidir qual modelo de threads é mais adequado para esse servidor.
Requisitos e considerações:
- Alta concorrência: o servidor web deve ser capaz de lidar com uma alta concorrência de solicitações de clientes simultâneas, pois muitos usuários acessarão os sites e serviços ao mesmo tempo.
- Eficiência de recursos: o servidor deve ser eficiente em termos de recursos, pois a empresa deseja otimizar o uso de CPU e memória para reduzir os custos de infraestrutura.
- Escalabilidade: como a empresa planeja expandir seus serviços, o servidor deve ser escalável para acomodar um aumento no número de clientes e solicitações.
Você deve escolher entre vários modelos de threads para implementar o servidor web. Os modelos mais comuns são many-to-one (muitos-para-um), one-to-one (um-para-um), many-to-many (muitos-para-muitos) e modelos híbridos.
Vamos à resolução?
Com base nos requisitos e considerações acima, você decide implementar um modelo many-to-many (muitos-para-muitos) para o servidor web. Isso permite que vários threads de nível de usuário sejam mapeados para um número menor de threads de nível de kernel, proporcionando um equilíbrio entre eficiência de recursos e escalabilidade. Esse modelo oferece as seguintes vantagens:
- Permite a execução concorrente eficiente de solicitações de clientes em sistemas multiprocessadores, aproveitando os núcleos da CPU.
- Reduz a sobrecarga de recursos em comparação com um modelo one-to-one, uma vez que os threads de nível de usuário são mapeados de forma flexível para threads de nível de kernel.
- Oferece escalabilidade para lidar com um aumento no tráfego e no número de clientes sem adicionar uma sobrecarga significativa de recursos.
A escolha do modelo many-to-many para o servidor web é apropriada, pois atende aos requisitos de alta concorrência, eficiência de recursos e escalabilidade. Esse modelo permite que o servidor web forneça serviços de forma eficaz e econômica, garantindo a capacidade de atender a um número crescente de usuários e solicitações.
Saiba Mais
Thread (linha de execução) é uma sequência de instruções que faz parte de um processo principal. Um software é organizado em processos. Para saber mais acesse o artigo: O que são threads do processador e quais os benefícios do multithreading?
Referências Bibliográficas
TANEMBAUM, A. S. Sistemas operacionais modernos. 3. ed. São Paulo: Pearson Prentice Hall, 2003.
Encerramento da Unidade
Processos e Threads
Videoaula de Encerramento
Estudante, esta videoaula foi preparada especialmente para você. Nela, você irá aprender conteúdos importantes para a sua formação profissional. Vamos assisti-la?
Ponto de Chegada
Olá, estudante! Para desenvolver a competência desta unidade, que é conhecer os principais processos e threads relacionados aos sistemas operacionais, devemos entender os conceitos, funcionalidades e características essenciais desses componentes.
Compreensão de Processos:
- Definição de processo: um processo em um sistema operacional é uma instância em execução de um programa. Ele possui seu próprio espaço de endereçamento, recursos e estado.
- Estados de processo: Aprenda sobre os diferentes estados de um processo, como pronto, em execução e bloqueado. Compreenda como um processo transita entre esses estados.
- Gerenciamento de processos: Estude como o sistema operacional gerencia processos, incluindo criação, escalonamento, término e comunicação entre processos.
- Identificação de processos: Saiba como os processos são identificados e gerenciados por meio de identificadores exclusivos, como IDs de processo.
Compreensão de Threads:
Threads são unidades menores de execução dentro de um processo e compartilham recursos e espaço de endereçamento com outros threads do mesmo processo.
- Threads leves e pesados: Familiarize-se com a diferença entre threads leves (user-level threads) e threads pesados (kernel-level threads) e as vantagens e desvantagens de cada um.
- Paralelismo e concorrência: Aprenda como os threads permitem a execução paralela e a concorrência em um sistema. Explore os desafios e benefícios do uso de threads.
- Sincronização de threads: Compreenda a importância da sincronização de threads para evitar condições de corrida e garantir o acesso seguro a recursos compartilhados.
Escalonamento de Processos e Threads:
- Escalonamento de CPU: Estude os algoritmos de escalonamento usados pelos sistemas operacionais para decidir quais processos ou threads têm acesso à CPU e por quanto tempo.
- Prioridades: Entenda como as prioridades são usadas no escalonamento para dar preferência a determinados processos ou threads.
Comunicação e Sincronização:
- Mecanismos de comunicação: Explore os métodos e mecanismos usados para que processos e threads possam compartilhar informações e cooperar, como semáforos, mutexes e pipes.
- Semáforos e mutexes: Aprofunde-se nos conceitos de semáforos e mutexes para a sincronização de threads e resolução de problemas de concorrência.
Desenvolver competência em processos e threads em sistemas operacionais é fundamental para profissionais de TI, programadores e desenvolvedores, pois esses conceitos são amplamente usados na criação de aplicativos eficientes e responsivos. A prática, juntamente com a teoria, é essencial para adquirir e aprimorar essas habilidades.
É Hora de Praticar!
Concorrentemente Atualizando Dados de Conta Bancária
Descrição da situação-problema
Imagine que você está trabalhando em um sistema de banco on-line que permite que os clientes acessem e atualizem suas contas bancárias simultaneamente. Os clientes podem realizar transações, como depósitos e saques ao mesmo tempo, e o sistema precisa garantir que essas operações sejam executadas de maneira segura e precisa, evitando problemas como saldos negativos e conflitos de dados.
O desafio é garantir a integridade dos dados das contas bancárias enquanto permite que vários clientes acessem e atualizem suas contas concorrentemente.
Reflita
- Quais são os desafios de implementar processos e threads em sistemas operacionais multiprogramados?
- Qual é a principal diferença entre um processo e um thread?
- Por que a sincronização é importante em programação com threads?
Resolução do estudo de caso
Resolução da situação-problema
Para lidar com essa situação-problema, você pode implementar uma solução usando threads e mecanismos de sincronização.
- Utilização de threads: cada cliente que acessa sua conta bancária é representado por um thread separado. Isso permite que vários clientes acessem o sistema ao mesmo tempo.
- Mutex (Mutex Exclusivo): Para garantir que as operações de atualização da conta bancária sejam executadas de maneira segura e não haja conflitos, você pode usar mutexes (semaforos binários) para garantir a exclusividade da operação. Antes de realizar uma operação em uma conta, um thread deve adquirir um mutex associado a essa conta.
- Transações atômicas: as operações de depósito e saque devem ser implementadas de maneira atômica, garantindo que um thread não possa ser interrompido entre a leitura do saldo atual e a atualização do saldo. Isso evita que um cliente deposite dinheiro em uma conta que já está fazendo um saque no mesmo saldo.
- Tratamento de conflitos: caso uma transação resulte em um saldo negativo na conta, é necessário implementar uma lógica de tratamento de conflitos para reverter a operação ou notificar o cliente, dependendo dos requisitos do sistema.
- Testes e garantia de qualidade: é essencial realizar testes extensivos para garantir que a solução funcione corretamente sob condições de concorrência. Isso inclui testes de unidade e testes de estresse para verificar se o sistema é seguro e eficiente.
Essa solução usa threads e mutexes para garantir a sincronização e a segurança das operações bancárias em um ambiente de concorrência. Com a devida implementação e testes, o sistema deve ser capaz de lidar com as atualizações concorrentes das contas bancárias de forma eficaz e precisa.
Dê o play!
Assimile
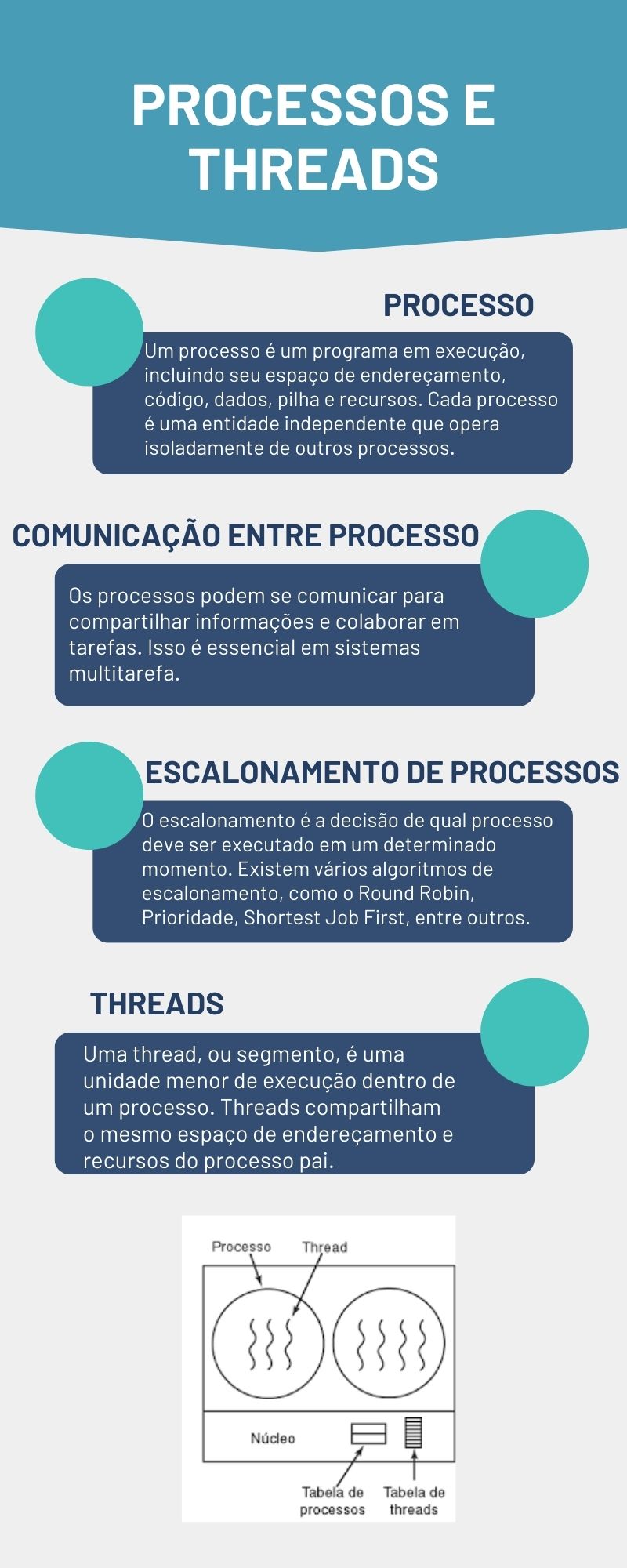
Um processo é um programa em execução que inclui seu próprio espaço de endereçamento, código, dados, pilha e recursos.
Um thread, ou segmento, é uma unidade menor de execução dentro de um processo. Elas compartilham o mesmo espaço de endereçamento e recursos do processo pai.
Na Figura a seguir, veremos os processos e o threads.
Referências
TANENBAUM, A. S.; WOODHULL, A. S. Sistemas operacionais. Porto Alegre: Grupo A, 2008.
JR., R. S. C.; LEDUR, C. L.; MORAIS, I. S. Sistemas operacionais. São Paulo: Editora ABDR, 2019.
TANEMBAUM, A. S. Sistemas operacionais modernos. 3. ed. São Paulo: Pearson Prentice Hall, 2003.