MANIPULAÇÃO DE DADOS E ESTRUTURAS
Aula 1
Comandos DML para manipulação de bancos de dados
Comandos DML para manipulação de bancos de dados
Olá, estudante! Nesta empolgante videoaula, você explorará os fundamentos da manipulação de dados em bancos de dados e aprenderá sobre a inserção de dados (INSERT), a atualização de informações (UPDATE) e a exclusão de registros (DELETE).
Esses conceitos são essenciais para aprimorar sua prática profissional, garantindo a eficiência na gestão de dados. Esteja preparado para uma jornada de aprendizado e aprimoramento.
Vamos lá!
Ponto de Partida
Dando prosseguimento ao desenvolvimento do guia turístico para a multinacional em que trabalha, você está, agora, na fase de manipulação de banco de dados. Até o momento, é provável que você já tenha criado o seu banco de dados e estabelecido uma estrutura inicial com diversas tabelas e suas propriedades correspondentes, ou seja, a definição dos campos e tipos de dados para armazenamento. Após essa criação, é necessário testar a estrutura, o que envolve o conhecimento de instruções para manipulação de banco de dados. Esses testes incluem a inserção de dados nas tabelas, seguida da verificação de seu conteúdo para assegurar que as informações cruciais para o guia turístico estejam sendo armazenadas de forma adequada, nos formatos corretos e nas posições apropriadas. Como parte desses testes, é imprescindível utilizar comandos de atualização para modificar os dados inseridos, a fim de garantir que as ações tenham os efeitos desejados.
Os dados a serem inseridos são:
- Países (com respectivos continentes): Brasil, Índia, China e Japão.
- Estados (com respectivas siglas): Maranhão, São Paulo, Santa Catarina, Rio de Janeiro.
- Cidades (com respectivas populações aproximadas): Sorocaba, Déli, Xangaim, Tóquio.
- Pontos turísticos (com sua especificação): Quinzinho de Barros (instituição), Parque Estadual do Jalapão (atrativo), Torre Eiffel (atrativo), Fogo de Chão (restaurante).
Já os dados a serem alterados, são:
- Alterar para “atrativo” o primeiro ponto turístico da lista.
- Alterar o segundo país (Índia) para ter o código “IND”.
- Por fim, você deverá deletar a primeira cidade da lista.
Em todos esses casos, é fundamental verificar, por meio do comando SELECT, se as inserções e alterações foram efetuadas corretamente. Esses testes têm como propósito avaliar a integridade da estrutura do banco de dados, bem como a precisão das informações armazenadas.
Nesta aula, você terá acesso a um subconjunto de instruções SQL relacionadas à linguagem de manipulação de dados (DML), incluindo as instruções de inserção (INSERT). Após o armazenamento dos dados, serão discutidas duas ações possíveis: uma, que envolve a atualização dos dados (UPDATE), e outra, que trata da exclusão de dados (DELETE).
Bons estudos!
Vamos Começar!
Inserção de dados (INSERT)
A partir deste momento, você utilizará a linguagem de manipulação de dados (DML). Nesse contexto, é importante saber que as operações e os comandos contidos nesse subconjunto consistem em instruções para inserir, atualizar, modificar e excluir dados em tabelas.
A instrução INSERT possibilita a adição de novas linhas ou registros em uma tabela já existente. Sua estrutura é a seguinte:
INSERT [INTO] nome_tabela [(nome_coluna [, nome_coluna] ...)] {VALUES | VALUE} (lista_valores) [, (lista_ valores)] … |
Ao utilizar a declaração VALUES, são especificados os valores explícitos a serem inseridos. Se a instrução for utilizada sem parâmetros, a sintaxe é como a que se apresenta a seguir:
| INSERT INTO nome_tabela () VALUES(); |
Se tanto a lista de colunas quanto a lista de VALUES estiverem vazias, o MySQL criará uma linha com cada coluna configurada com seus valores-padrão.
Uma expressão pode se referir a qualquer coluna definida anteriormente na lista de valores, por exemplo: é possível utilizar a instrução a seguir, na qual o valor para col2 refere-se a col1, atribuído anteriormente:
| INSERT INTO nome_tabela (col1, col2) VALUES(15, col1*2); |
Essa instrução, que é correta, será interpretada normalmente pelo MySQL. Entretanto, se se inverter a ordem e atribuir-se o valor de col1 para col2, como demonstrado adiante, a sintaxe estará incorreta e a execução não será bem-sucedida. Isso ocorrerá porque, no momento da atribuição do valor à col1, col2 ainda não terá sido atribuído, já que é o segundo parâmetro da inserção:
| INSERT INTO nome_tabela (col1, col2) VALUES(col2*2, 15); |
A instrução VALUES também permite a inserção de múltiplas linhas, incluindo várias listas de valores de coluna separadas por vírgula, dentro de parênteses e também separadas por vírgulas, como exemplificado a seguir:
INSERT INTO nome_tabela (a, b, c) VALUES(1,2,3), (4,5,6), (7,8,9); |
Cada lista de valores deve conter precisamente a quantidade de valores a serem inseridos por linha, como ilustrado no exemplo anterior, em que são fornecidos três valores por linha. Caso se tente inserir o número total de valores (9) em vez de três listas, cada uma com três valores, a sintaxe será inválida.
Para exemplificar algumas instruções, considere uma tabela criada com a seguinte declaração:
CREATE TABLE IF NOT EXISTS convidado ( id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(50) NOT NULL DEFAULT '', nascimento DATE, estudante ENUM('Não', 'Sim') NOT NULL DEFAULT ‘Não’ ); |
Ao utilizar a instrução a seguir, uma linha será adicionada à tabela "convidado", preenchendo as colunas "nome", "nascimento" e "estudante" com os valores correspondentes da cláusula VALUES. Não é necessário seguir a ordem de criação das colunas na instrução.
INSERT INTO CONVIDADO (nome, nascimento, estudante) VALUES ('Dani Moura', '1979-03-28', 'Sim'); |
Para verificar o resultado, utilize “SELECT * FROM convidado;”. O resultado será visualizado conforme apresentado na Figura 1.
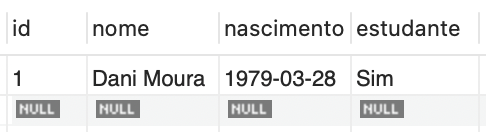
Quando a coluna não é especificada, nenhum valor é atribuído, e, ao realizar-se uma consulta nessa coluna, o resultado será exibido como NULL (nulo). Para atribuir explicitamente um valor nulo, é necessário utilizar a seguinte instrução:
INSERT INTO CONVIDADO (nome, nascimento, estudante)
| VALUES ('Rui Albuquerque', null , 'Sim'); |
Após a execução dessa instrução, o resultado aparecerá como o descrito na Figura 2:
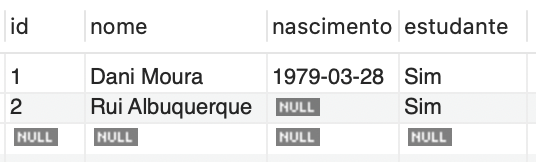
É importante observar que, caso a coluna "nascimento" seja definida com a opção NOT NULL, a execução da instrução será impedida, pois essa restrição obriga a inclusão de um valor para a referida coluna.
Siga em Frente...
Atualização de dados (UPDATE)
A instrução UPDATE pertence à sublinguagem DML e é utilizada para modificar ou atualizar linhas em uma tabela. Sua sintaxe é apresentada a seguir:
UPDATE tabela_referência SET lista_atribuição [WHERE condição] [ORDER BY ...] [LIMIT quantidade_linhas] |
O valor, após a clausula SET, pode ser uma expressão ou a palavra-chave DEFAULT para designar explicitamente a coluna como seu valor padrão. Um exemplo do comando UPDATE é:
UPDATE convidado SET estudante = ‘Sim’ WHERE nome = 'Lebrencio Grulher' AND nascimento = '08-Jul-1990'; |
Essa instrução atualiza para “Sim” a condição de estudante para todos os convidados com o nome Lebrencio Grulher que nasceram em 8 de julho de 1990. Homônimos de Lebrencio Grulher nascidos em datas diferentes ou outros convidados que não possuam o mesmo nome, mas nasceram em 8 de julho de 1990, não serão afetados.
A cláusula WHERE, quando fornecida, especifica as condições que identificam quais linhas devem ser atualizadas. Importante notar que, caso não haja uma cláusula WHERE, todas as linhas serão atualizadas. Por exemplo:
UPDATE convidado SET estudante = 'Não';
Se a cláusula ORDER BY for utilizada, as linhas serão atualizadas na ordem especificada, e a cláusula LIMIT imporá um limite no número de linhas que podem ser atualizadas.
UPDATE convidado SET estudante = ‘Sim’ WHERE nascimento < ‘08-Jul-1990’ ORDER BY nome; |
No exemplo anterior, todos os registros de nascidos antes de 8 de julho de 1990 terão a condição de estudante atualizada.
Ao adicionar um limite com a cláusula LIMIT, as atualizações ficarão restritas. No exemplo a seguir, apenas os primeiros 10 nomes (em ordem alfabética) terão a condição de estudante atualizada:
UPDATE convidado SET estudante = ‘Sim’ WHERE nascimento < ‘08-Jul-1990’ LIMIT 10 ORDER BY nome; |
Se uma coluna da tabela for referenciada em uma expressão durante a atualização, o UPDATE usará o valor atual da coluna. Por exemplo:
| UPDATE tabela_ref SET col1 = col1 + 1; |
Se uma coluna for definida com o valor que já possui, o MySQL reconhecerá isso e não realizará a atualização.
Operações UPDATE também podem abranger várias tabelas, mas não é possível utilizar ORDER BY ou LIMIT em um UPDATE de múltiplas tabelas. Um exemplo utilizando duas tabelas é o seguinte:
UPDATE lista, produto SET lista.preco = produto.preco WHERE lista.id = produto.id; |
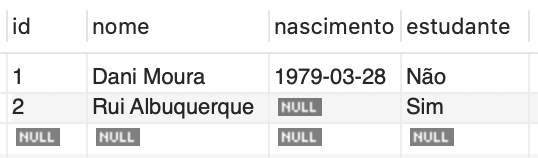
Na tabela "convidado", a instrução a seguir atualiza a condição de estudante para 'Não' onde o ID é igual a 1:
UPDATE convidado SET estudante = 'Não' WHERE id = 1;
Após a execução dessa instrução, o resultado aparecerá como na Figura 3.
Exclusão de dados (DELETE)
A instrução DELETE é uma operação DML que remove registros de uma tabela. Sua estrutura geral é a seguinte:
DELETE FROM nome_tabela [WHERE condição] [ORDER BY ...] [LIMIT quantidade_linhas] |
Semelhante à instrução UPDATE discutida anteriormente, as condições na cláusula WHERE determinam quais linhas serão excluídas. Se a cláusula WHERE não for utilizada, todas as linhas serão removidas. Ao ser declarada, a condição é avaliada para cada linha, e, se for verdadeira, a linha é excluída. Por exemplo:
DELETE FROM convidados WHERE estudante = ‘Sim’ ORDER BY nome LIMIT 10; |
Nesse comando, os dez primeiros estudantes (ordenados alfabeticamente por nome) marcados como estudantes serão removidos.
A presença da cláusula ORDER BY determina a ordem em que as linhas serão excluídas, e a cláusula LIMIT estabelece um limite para o número de linhas a serem excluídas. Mesmo ao excluir a linha com o valor máximo de uma coluna "AUTO_INCREMENT", o valor não será reutilizado.
Se a instrução DELETE incluir uma cláusula ORDER BY e LIMIT em conjunto, as linhas serão excluídas na ordem especificada pela cláusula ORDER BY. Por exemplo:
DELETE FROM log_usuario WHERE usuario = ‘rm’ ORDER BY datahora_acao LIMIT 1; |
Nesse exemplo, as linhas correspondentes à condição especificada na cláusula WHERE serão ordenadas pela coluna "datahora_acao" (do tipo DATETIME), e a primeira, ou seja, a mais antiga, será excluída.
Ao aplicar essa instrução ao banco de dados do exemplo, mais precisamente à tabela "convidado", teremos:
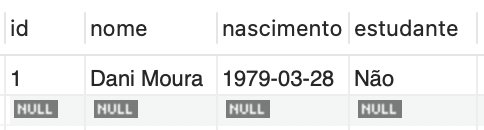
| DELETE FROM convidado WHERE id = 2; |
Após a execução dessa instrução, o resultado da consulta à tabela "convidado" refletirá a exclusão do convidado com ID 2, conforme a Figura 4.
Vamos Exercitar?
A partir de agora, estudante, retomaremos o projeto de um guia turístico que você está desenvolvendo para a empresa em que trabalha. Apesar de o repositório já estar criado, ele ainda está vazio e precisa ter iniciados os testes relacionados aos tipos de dados, conteúdos, valores padrões, comportamentos das chaves e outras características relevantes. Em outras palavras, é hora de começar a avaliar e observar o comportamento do banco de dados.
Para realizar essa análise, é crucial iniciar a manipulação de dados e visualizar os resultados por meio de consultas. O Quadro 1 apresenta uma sugestão de inserção de dados conforme o solicitado na situação:
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: | INSERT INTO pais (nome, continente, codigo) VALUES ('Brasil', 'América', 'BRA'), ('Índia', 'Ásia', 'IDN'), ('China', 'Ásia', 'CHI'), ('Japão', 'Ásia', 'JPN');
SELECT * FROM pais;
INSERT INTO estado (nome, sigla) VALUES ('Maranhão', 'MA'), ('São Paulo', 'SP'), ('Santa Catarina', 'SC'), ('Rio de Janeiro', 'RJ');
SELECT * FROM estado;
INSERT INTO cidade (nome, populacao) VALUES ('Sorocaba', 700000), ('Déli', 26000000), ('Xangai', 22000000), ('Tóquio', 38000000);
SELECT * FROM cidade;
INSERT INTO ponto_tur (nome, tipo) VALUES ('Quinzinho de Barros', 'Instituição'), ('Parque Estadual do Jalapão', 'Atrativo'), ('Torre Eiffel', 'Atrativo'), ('Fogo de Chão', 'Restaurante');
SELECT * FROM ponto_tur; |
Quadro 1 | Exemplo de inserção. Fonte: elaborado pelo autor.
Em seguida, é necessário realizar alguns testes de alterações, como designar o primeiro ponto turístico da lista como "Atrativo" e modificar o código do segundo país (Índia) para "IND". Essas tarefas podem ser executadas da seguinte maneira:
UPDATE ponto_tur SET tipo = 'Atrativo' WHERE id = 1; SELECT * FROM ponto_tur;
UPDATE pais SET codigo = 'IND' WHERE id = 2; SELECT * FROM pais; |
Posteriormente, é possível concluir os testes com instruções de exclusão, visando remover a primeira cidade da lista:
DELETE FROM cidade WHERE id = 1; SELECT * FROM cidade; |
Outros testes, como a exclusão de um dos pontos turísticos da tabela "ponto_tur" de uma posição específica, como a linha 4, podem ser conduzidos da seguinte forma:
DELETE FROM ponto_tur WHERE id = 4; SELECT * FROM ponto_tur; |
Dessa maneira, foi possível demonstrar que o banco de dados possui a estrutura adequada até o momento e responde de maneira precisa às alterações efetuadas.
Saiba Mais
Para se aprofundar ainda mais nas instruções de manipulação de dados, acesse o capítulo 15.2, Data Manipulation Statements, do manual MySQL 8.3.
ORACLE. MySQL 8.3 Reference Manual. 15.2 Data Manipulation Statements. MySQL, [s. l.], c2024.
Para complementar o estudo dos comandos de manipulação de dados, leia o capítulo 3 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 3, p. 37-67.
Também sugerimos a leitura do capítulo 6 do livro Sistemas de banco de dados, disponível na Biblioteca Virtual, que apresenta os fundamentos de SQL básica para complementar os estudos desta aula!
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book. cap. 6, p.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
MACHADO, F. N. R. Banco de dados: projeto e implementação. São Paulo: Saraiva, 2020. E-book.
ORACLE. MySQL 8.3 Reference Manual. 15.2 Data Manipulation Statements. MySQL, [s. l.], c2024. Disponível em: https://dev.mysql.com/doc/refman/8.3/en/sql-data-manipulation-statements.html. Acesso em: 2 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
Aula 2
Alteração de tabelas
Alteração de tabelas
Olá, estudante! Nesta videoaula, exploraremos comandos essenciais para a manipulação eficaz de tabelas em bancos de dados. Para tanto, abordaremos os comandos DDL, tais como o ALTER TABLE, que possibilita a adição, a exclusão, a renomeação e a redefinição de colunas.
Esses conhecimentos são cruciais para aprimorar sua prática profissional e permitir a adaptação dinâmica de estruturas de dados. Esteja preparado para aprofundar sua compreensão e otimizar suas habilidades! Vamos juntos nessa jornada de aprendizado!
Ponto de Partida
No desenvolvimento do sistema de guia turístico no qual vocês está envolvido, o repositório de dados, agora completamente testado e repleto de informações e relacionamentos, revela a omissão de um requisito crucial: a língua nativa de cada país. Essa lacuna exige ajustes na estrutura do banco de dados, ou seja, na estrutura da tabela “país”.
Outro ponto importante é a necessidade de ajustar a estrutura da tabela ponto_tur, de acordo com as seguintes diretrizes:
Excluir a coluna “população”, que, por algum erro da equipe, foi incluída na criação da tabela, mas que não se adequa aos atributos de um ponto turístico.
Alterar a coluna “tipo”, que é um ENUM('Atrativo', 'Serviço', 'Equipamento', 'Infraestrutura', 'Instituição', 'Organização'), de modo a inserir um novo tipo de ponto: ‘Patrimônio Público’.
Renomear a tabela para “pontos_tur”.
Além disso, considerando a possibilidade de múltiplas línguas em um país, é necessário refletir essas mudanças no DER e criar uma tabela que atenda a esse novo relacionamento. Esse processo, abordado nas instruções DDL, demandará também consultas DQL para identificar campos vazios e relacionamentos quebrados, corrigindo essas situações por meio de instruções DML. Essas alterações devem ser realizadas de forma a não requerer a reconstrução completa da base de dados e das tabelas afim de que contemplem também a preservação dos dados existentes.
Nesta aula, você compreenderá como efetuar modificações nas tabelas, um desafio empolgante!
Vamos avançar juntos!
Vamos Começar!
Comandos DDL para alteração de tabelas (ALTER TABLE)
O comando ALTER TABLE é utilizado para alterar a estrutura de uma tabela. Isso engloba a adição ou exclusão de colunas, a criação ou remoção de índices, a alteração dos tipos de coluna existentes, a renomeação de colunas ou até mesmo da tabela em si. Características, como o mecanismo de armazenamento utilizado para a tabela ou o comentário associado, também podem ser alteradas. A sintaxe da instrução é a seguinte:
ALTER TABLE nome_tabela [especificação_alteração [,especificação_alteração] ...] |
A seguir, serão apresentados os principais qualificadores da especificação_alteração que podem ser empregados:
| ADD [COLUMN] (nome_coluna column_definition,...) |
Adiciona à tabela uma ou mais colunas com suas definições.
| `ADD [COLUMN] nome_coluna column_definition [FIRST | AFTER nome_coluna]`. |
Sintaxe alternativa:
| ADD {INDEX|KEY} [índice_nome] (índice_nome_coluna,...) [índice_opção] … |
Adiciona um índice ou chave à tabela, especificando o nome do índice e as colunas envolvidas, além de opções adicionais.
| ALTER [COLUMN] nome_coluna {SET DEFAULT literal | DROP DEFAULT} |
Modifica as configurações de uma coluna, definindo ou removendo um valor padrão.
| ALTER INDEX índice_nome {VISIBLE | INVISIBLE} |
Modifica a visibilidade de um índice, tornando-o visível ou invisível.
| CHANGE [COLUMN] old_nome_coluna new_nome_coluna column_definition [FIRST|AFTER nome_coluna] |
Renomeia uma coluna, alterando seu nome e/ou suas definições, com opções de posicionamento.
| [DEFAULT] CHARACTER SET [=] charset_nome [COLLATE [=] collation_nome] |
Modifica o conjunto de caracteres e a ordenação associada da tabela ou coluna.
| CONVERT TO CHARACTER SET charset_nome [COLLATE collation_nome] |
Converte a tabela para um conjunto de caracteres específico, com opção de alterar a ordenação.
| {DISABLE|ENABLE} KEYS |
Desativa ou ativa a geração de índices para a tabela.
| {DISCARD|IMPORT} TABLESPACE |
Descarta ou importa o espaço de tabela associado.
| DROP [COLUMN] nome_coluna |
Remove uma coluna da tabela.
| DROP {INDEX|KEY} índice_nome |
Remove um índice ou chave específico da tabela.
| DROP PRIMARY KEY |
Remove a chave primária da tabela.
| MODIFY [COLUMN] nome_coluna column_definition [FIRST | AFTER nome_coluna] |
Modifica a definição de uma coluna, com opções de posicionamento.
| ORDER BY nome_coluna [, nome_coluna] … |
Ordena as linhas da tabela com base nas colunas especificadas.
| RENAME COLUMN old_nome_coluna TO new_nome_coluna |
Renomeia uma coluna existente.
| RENAME {INDEX|KEY} old_índice_nome TO new_índice_nome |
Renomeia um índice ou uma chave existente.
| RENAME [TO|AS] new_tbl_nome |
Renomeia a tabela.
A sintaxe para muitas das alterações permitidas é similar às das cláusulas encontradas na instrução CREATE TABLE. A utilização da palavra COLUMN é facultativa e pode ser excluída, exceto no caso de RENAME COLUMN, em que é necessária para diferenciar a operação de renomeação de coluna da operação de renomeação de tabela (RENAME).
É possível realizar múltiplas alterações utilizando as cláusulas ADD, ALTER, DROP e CHANGE em uma única instrução ALTER TABLE, separando-as por vírgulas. Essa capacidade representa uma extensão do MySQL em relação ao SQL padrão, o qual permite apenas uma cláusula por instrução ALTER TABLE. Por exemplo, para descartar várias colunas em uma única instrução, utilize o comando a seguir:
| ALTER TABLE cliente DROP COLUMN parentesco, DROP COLUMN telefones; |
Nessa instrução, as colunas "parentesco" e "telefones" serão removidas da tabela "cliente".
Para modificar o valor do campo de incremento automático de uma tabela, utilize a instrução:
| ALTER TABLE cliente AUTO_INCREMENT = 13; |
Uma tabela pode ter apenas uma coluna identificada como autoincremento. No exemplo anterior, na tabela "cliente", o campo de incremento automático é explicitamente alterado para o valor 13. As próximas inserções de registros nessa tabela terão automaticamente esse campo preenchido com o valor 13 e subsequentes.
No MySQL, é possível especificar uma cadeia de caracteres (CHARSET) diferente para uma tabela em relação ao banco de dados. Por exemplo, caso o banco de dados esteja definido com o padrão UTF-8 e seja necessário alterar uma tabela específica para utilizar o charset LATIN-1, a instrução seria:
| ALTER TABLE pessoas CHARACTER SET = latin1; |
Após a execução dessa instrução, todas as tabelas criadas continuarão utilizando o charset UTF-8, exceto a tabela "pessoas", que estará configurada com o LATIN-1.
Siga em Frente...
Adicionar e excluir colunas (ADD e DROP)
Utilize o comando ADD para introduzir novas colunas em uma tabela e o comando DROP para eliminar colunas existentes. A inclusão da cláusula DROP nome_coluna representa uma extensão do MySQL em relação ao SQL padrão.
Para acrescentar uma coluna em uma posição específica dentro de uma linha da tabela, é necessário empregar FIRST ou AFTER nome_coluna. A configuração padrão é acrescentar a coluna à última posição. Ao realizar a exclusão de colunas, você deve se atentar a algumas condições:
- Se uma tabela possuir apenas uma coluna, não será possível eliminá-la.
- Para remover a tabela por completo, utilize a instrução DROP TABLE.
- Caso as colunas sejam removidas de uma tabela, elas também serão retiradas de qualquer índice ao qual estejam associadas.
- Se todas as colunas que compõem um índice forem descartadas, ele será automaticamente eliminado.
- Se CHANGE ou MODIFY forem utilizados para reduzir o tamanho de uma coluna que integra um índice, e o tamanho resultante for menor que o tamanho do índice, o MySQL o ajustará automaticamente.
No contexto de adição de um campo, como o de "nome", com o tipo especificado na tabela "pessoas", a instrução seria:
| ALTER TABLE pessoas ADD nome VARCHAR(50); |
Para excluir o campo "sobrenome" da mesma tabela, a instrução seria:
| ALTER TABLE pessoas DROP COLUMN sobrenome; |
Após a execução dessa instrução, ao consultar a tabela "pessoas", o campo "sobrenome" não será mais exibido.
Renomear, redefinir e reordenar colunas (CHANGE, MODIFY, RENAME COLUMN e ALTER)
As cláusulas CHANGE, MODIFY, RENAME COLUMN e ALTER oferecem a possibilidade de modificar os nomes e as definições de colunas já existentes, apresentando as seguintes características comparativas: a cláusula CHANGE pode renomear uma coluna e alterar sua definição, ou ambas as operações. Embora tenha maior capacidade em comparação com MODIFY ou RENAME COLUMN, isso vem às custas de conveniência para algumas operações. O comando CHANGE requer que o nome da coluna seja especificado duas vezes, caso ainda não tenha sido renomeada, e exige que a definição da coluna seja especificada novamente, mesmo que seja apenas para renomeá-la. Quando combinado com FIRST ou AFTER, esse comando pode reorganizar a ordem das colunas. Para modificar uma coluna e alterar tanto seu nome quanto sua definição, utiliza-se CHANGE, indicando os nomes antigos e novos, juntamente com a nova definição. Um exemplo dessa instrução é:
| ALTER TABLE pessoas CHANGE antigo novo BIGINT NOT NULL; |
Nesse exemplo, uma coluna está sendo renomeada e definida como NOT NULL de "antigo" para "novo", com uma alteração adicional para o tipo de dados BIGINT, mantendo a propriedade NOT NULL.
Já o comando MODIFY também pode alterar a definição de uma coluna, mas não seu nome, sendo mais conveniente que CHANGE nesse aspecto. Além disso, utilizando os qualificadores FIRST ou AFTER, é possível reorganizar a ordem das colunas. Um exemplo de instrução é:
| ALTER TABLE pessoas MODIFY novo INT NOT NULL; |
MODIFY é mais conveniente quando se deseja alterar a definição sem modificar o nome, pois exige apenas a especificação do nome da coluna uma vez.
Por fim, a cláusula RENAME COLUMN tem a capacidade de alterar o nome de uma coluna, mas não sua definição. É um comando mais conveniente que CHANGE quando o objetivo é apenas renomear uma coluna sem modificar sua definição, exigindo apenas os nomes antigos e novos. Um exemplo dessa instrução é:
| ALTER TABLE pessoas RENAME COLUMN novo TO antigo; |
Nesse caso, a coluna chamada "novo" na tabela "pessoas" está sendo renomeada para "antigo".
Vamos Exercitar?
Durante o desenvolvimento do aplicativo de guia turístico, você foi incumbido de ajustar a estrutura de algumas tabelas do banco.
O primeiro ajuste a ser feito é na tabela “país”, na qual devemos adicionar uma nova coluna correspondente à língua oficial do país. Para isso, você deve executar o seguinte comando:
| ALTER TABLE pais ADD lingua_oficial VARCHAR(50) NOT NULL; |
O próximo passo consiste no tratamento da tabela “ponto_tur”. Primeiramente, exclua a coluna “população” com o seguinte comando:
| ALTER TABLE ponto_tur DROP COLUMN populacao; |
Em seguida, altere o atributo “tipo” com a seguinte sintaxe:
| ALTER TABLE ponto_tur MODIFY tipo ENUM('Atrativo', 'Serviço', 'Equipamento', 'Infraestrutura', 'Instituição', 'Organização', ‘Patrimônio Público’); |
Note que o MODIFY foi utilizado, pois não há a necessidade de alterar o nome do atributo. Agora, falta apenas renomear a tabela:
| ALTER TABLE ponto_tur RENAME pontos_tur; |
Saiba Mais
Para conhecer mais e melhor as instruções de definição de dados para alteração de tabelas e estruturas, acesse o capítulo 15.1, Data Definition Statements, do manual do MySQL 8.3.
ORACLE. MySQL 8.3 Reference Manual. 15.1 Data Definition Statements. MySQL, [s. l.], c2024.
Para complementar o estudo dos comandos de definição de dados, como o ALTER TABLE, leia o capítulo 3 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 3, p. 37-67.
Também sugerimos o acesso ao site W3Schools, à sessão SQL ALTER TABLE Statement, que fornece diversos exemplos de utilização desse tipo de comando!
W3SCHOOLS. SQL ALTER TABLE Statement. W3Schools, [s. l.], c2024.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
ORACLE. MySQL 8.3 Reference Manual. 15.1 Data Definition Statements. MySQL, [s. l.], c2024. Disponível em: https://dev.mysql.com/doc/refman/8.3/en/sql-data-definition-statements.html. Acesso em: 2 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
W3SCHOOLS. SQL ALTER TABLE Statement. W3Schools, [s. l.], c2024. Disponível em: https://www.w3schools.com/sql/sql_alter.asp. Acesso em: 2 fev. 2024.
Aula 3
Uso de Constraints (restrições)
Uso de Constraints (restrições)
Olá, estudante! Nesta videoaula, exploraremos a definição e a aplicação de constraints (restrições) em bancos de dados. Aprenderemos a utilizar comandos como ADD CONSTRAINT, PRIMARY KEY e FOREIGN KEY, essenciais para a modelagem e integridade dos dados. Veremos também como atualizar e excluir constraints com qualificadores específicos.
Esses conhecimentos são cruciais para garantir a consistência e a eficiência dos seus projetos profissionais em banco de dados. Prepare-se para aprimorar suas habilidades!
Vamos lá!
Ponto de Partida
Agora, com o repositório de dados do sistema de guia turístico que você está desenvolvendo completamente testado e repleto de informações e relacionamentos, identificou-se a omissão de um requisito crucial: cada país pode ter mais de uma língua nativa. Essa lacuna exige ajustes na estrutura do banco de dados!
Diante disso, será necessário refletir as mudanças que ajustem essa lacuna no DER e criar uma tabela que atenda a esse novo relacionamento. Esse processo, abordado nas instruções DDL, demandará também consultas DQL para identificar campos vazios e relacionamentos quebrados, corrigindo essas situações por meio de instruções DML. Essas alterações devem ser realizadas de forma que não seja preciso reconstruir completamente a base de dados e as tabelas e que se possa preservar os dados existentes.
Vamos Começar!
Definição de constraints (restrições)
As constraints, ou restrições, em um banco de dados são elementos utilizados para garantir a integridade e a consistência dos dados armazenados. Elas impõem regras e limitações sobre as operações que podem ser realizadas em determinadas colunas ou tabelas, assegurando que apenas dados válidos e consistentes sejam inseridos ou modificados. Existem vários tipos de constraints com funções específicas:
- PRIMARY KEY (chave primária): garante que cada linha em uma tabela seja única e identificável por meio de um valor único em uma coluna específica. Isso evita duplicidade e facilita a indexação.
- UNIQUE KEY (chave única): é similar à chave primária, mas permite que a coluna tenha valores nulos, garantindo apenas a unicidade dos valores não nulos. É útil quando se permite a ausência de valor em uma coluna.
- FOREIGN KEY (chave estrangeira): estabelece uma relação entre duas tabelas, garantindo que os valores em uma coluna correspondam aos valores existentes em outra tabela. Isso mantém a consistência referencial e evita registros órfãos.
- CHECK CONSTRAINT (restrição de verificação): define uma condição a que os valores em uma coluna devem atender. Se a condição não for satisfeita, a operação de inserção ou atualização é rejeitada. Isso é útil para impor regras específicas sobre os dados.
- NOT NULL CONSTRAINT (restrição de não nulo): impede a inserção de valores nulos em uma coluna específica. Isso assegura que informações cruciais não estejam ausentes, preservando, assim, a integridade semântica dos dados.
Ao definir constraints, os benefícios são significativos, pois elas contribuem para a consistência e a qualidade dos dados, impedindo a introdução de informações inconsistentes ou inválidas. Além disso, ajudam a preservar a integridade referencial, evitando relações ambíguas ou quebras na cadeia de dados relacionados.
Em resumo, as constraints são pilares fundamentais para garantir a qualidade e a confiabilidade dos dados em um banco de dados, proporcionando uma estrutura robusta e coerente. A compreensão e a aplicação eficiente desses conceitos são essenciais para qualquer profissional envolvido em projetos de gerenciamento de bancos de dados.
Siga em Frente...
Uso de restrições (ADD CONSTRAINT, PRIMARY KEY, FOREIGN KEY)
Se você atribuir os qualificadores UNIQUE INDEX ou PRIMARY KEY a uma tabela, o MySQL os armazenará antes de qualquer outro índice, inclusive antes dos não exclusivos, visando detectar chaves duplicadas o mais cedo possível.
Ao definir uma chave primária em uma tabela utilizando a cláusula CREATE TABLE ou ALTER TABLE, você pode especificar um campo como PRIMARY KEY. Por exemplo, na instrução adiante, o campo "id" é declarado como chave primária e não pode conter valores nulos:
CREATE TABLE pessoa( id INT NOT NULL PRIMARY KEY, nome VARCHAR(255) NOT NULL, sobrenome VARCHAR(255), idade INT ); |
Suponhamos que você deseje alterar essa chave primária para incluir duas colunas, não apenas uma. Inicialmente, é necessário remover a chave primária existente:
| ALTER TABLE pessoa DROP PRIMARY KEY; |
Em seguida, você deve nomear uma nova restrição PRIMARY KEY e defini-la para várias colunas usando a seguinte sintaxe SQL:
ALTER TABLE pessoa ADD CONSTRAINT PK_pessoa PRIMARY KEY (id, sobrenome); |
Agora, você está declarando uma chave primária composta na tabela "pessoa" com o nome PK_pessoa e as duas colunas que a compõem.
O MySQL oferece suporte a chaves estrangeiras, permitindo a referência cruzada de dados entre tabelas e a imposição de restrições. A sintaxe essencial para definir uma restrição de chave estrangeira em uma instrução CREATE TABLE ou
ALTER TABLE é semelhante à apresentada a seguir: ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCES tbl_name (index_col_name, ...) [ON DELETE referencias] [ON UPDATE referencias] |
- tbl_name: nome da tabela à qual a chave estrangeira será adicionada.
- CONSTRAINT [symbol]: opcionalmente, pode-se fornecer um nome simbólico para a restrição. O uso do símbolo é uma prática recomendada para facilitar a identificação e a manutenção futura.
- FOREIGN KEY: indica que estamos adicionando uma chave estrangeira.
- index_name: opcionalmente especifica o nome da chave estrangeira. Se não fornecido, o MySQL atribuirá automaticamente um nome a ela.
- (index_col_name, ...): representa a lista de colunas, na tabela atual, que formará a chave estrangeira.
- REFERENCES tbl_name (index_col_name, ...): define a tabela e as colunas na tabela de referência às quais a chave estrangeira está vinculada.
- referências: RESTRICT | CASCADE | SET NULL | NO ACTION. Qualificadores que proporcionam controle sobre o comportamento da chave estrangeira em situações de exclusão ou atualização de registros nas tabelas envolvidas.
O MySQL automaticamente gera um índice de chave estrangeira, cujo nome segue determinadas regras:
- Se especificado, o símbolo CONSTRAINT é utilizado; caso contrário, utiliza-se o index_name FOREIGN KEY.
- Na ausência de símbolo CONSTRAINT ou FOREIGN KEY index_name, o nome do índice de chave estrangeira é derivado do nome da coluna de chave estrangeira na tabela referenciada.
Relacionamentos de chave estrangeira envolvem uma tabela pai (contendo valores fundamentais) e uma tabela filha (com valores idênticos referenciando a tabela pai). A cláusula FOREIGN KEY é aplicada na tabela filha, mas é preciso que ambas compartilhem o mesmo mecanismo de armazenamento. É necessário que haja correspondência nos tipos de dados entre colunas na chave estrangeira e na chave referenciada, embora haja flexibilidade no comprimento de tipos de string.
O MySQL exige índices em chaves estrangeiras e chaves referenciadas para agilizar as verificações de integridade referencial, evitando varreduras extensivas nas tabelas. Na tabela de referência, um índice é criado automaticamente, se inexistente, com as colunas de chave estrangeira listadas como as primeiras, mantendo-se a ordem.
Um exemplo concreto desses conceitos é ilustrado no trecho de código a seguir, no qual tabelas pai e filha são criadas. O índice necessário é gerado automaticamente na tabela de referência, garantindo a eficiência nas verificações de chaves estrangeiras.
CREATE TABLE pai ( id INT NOT NULL, nome VARCHAR(50), PRIMARY KEY (id) ); CREATE TABLE filha ( id INT PRIMARY KEY, parente_id INT, nome VARCHAR(50) ); |
Com a inclusão desses atributos, ambas as tabelas serão geradas, e é possível identificar um vínculo entre elas, evidenciado pelo campo parente_id na tabela secundária. Para ilustrar isso, estabeleceremos uma integridade referencial entre as tabelas, empregando esse elo por meio da seguinte instrução:
ALTER TABLE secundaria ADD CONSTRAINT FK_parente FOREIGN KEY (parente_id) REFERENCES principal(id); |
Após a execução dessa instrução, o MySQL estabelece uma integridade referencial, implementando uma chave estrangeira que conecta a tabela secundária à tabela principal, utilizando os campos parente_id e id, respectivamente. Embora não seja explicitamente mencionado, o MySQL cria automaticamente um índice para a coluna parente_id com esses comandos.
Atualização e exclusão de constraints (restrições) com o uso de qualificadores
Com o intuito de preservar a integridade referencial, o MySQL impede qualquer operação de INSERT ou UPDATE que tente introduzir um valor de chave estrangeira em uma tabela filha, caso não exista um valor correspondente de chave candidata na tabela pai. Quando uma operação UPDATE ou DELETE impacta um valor de chave na tabela pai que possui linhas correspondentes na tabela filha, o resultado depende da ação referencial especificada nas subcláusulas ON UPDATE e ON DELETE da cláusula FOREIGN KEY conforme a sintaxe apresentada:
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCES tbl_name (index_col_name, ...) [ON DELETE referencias] [ON UPDATE referencias] |
*referencias: RESTRICT | CASCADE | SET NULL | NO ACTION
O MySQL oferece quatro opções quanto à ação a ser tomada, que são destacadas a seguir:
- CASCADE: exclui ou atualiza a linha na tabela pai e automaticamente exclui ou atualiza as linhas correspondentes na tabela filha. Ambas as cláusulas ON DELETE CASCADE e ON UPDATE CASCADE são suportadas. É importante evitar a definição de várias cláusulas ON UPDATE CASCADE para atuarem na mesma coluna, seja na tabela pai, seja na tabela filha.
- SET NULL: exclui ou atualiza a linha na tabela pai e define como NULL a coluna ou colunas de chave estrangeira na tabela filha. Ambas as cláusulas ON DELETE SET NULL e ON UPDATE SET NULL são suportadas. É necessário ter cautela ao especificar a ação SET NULL para garantir que as colunas na tabela filha não tenham sido declaradas como NOT NULL.
- RESTRICT: rejeita a operação de exclusão ou atualização na tabela pai. Especificar RESTRICT (ou NO ACTION) é equivalente a omitir as cláusulas ON DELETE ou ON UPDATE.
- NO ACTION: é uma palavra-chave padrão do SQL, que, no MySQL, é equivalente a RESTRICT. O servidor MySQL rejeita a operação de exclusão ou atualização na tabela pai se houver um valor de chave estrangeira relacionado na tabela referenciada. Enquanto alguns sistemas de bancos de dados têm cheques diferidos, no MySQL as restrições de chave estrangeira são verificadas imediatamente, tornando NO ACTION o mesmo que RESTRICT.
Para remover uma restrição, execute a seguinte instrução, na qual a chave criada é retida após a execução, excluindo apenas a restrição:
| ALTER TABLE filha DROP FOREIGN KEY FK_parente; |
Vamos Exercitar?
Retomando a tarefa de desenvolvimento do guia turístico, nesta fase é necessário introduzir algumas modificações no trabalho já realizado. Para isso, é essencial revisar o diagrama de entidade-relacionamento (DER) e ajustá-lo para incorporar as novas tabelas e relações a serem estabelecidas. É importante ter em mente que essa ação pode exigir alterações no DER. Após essa revisão, é preciso criar uma tabela que leve em consideração essas novas relações com um país, conforme especificado no DER.
Além da mudança na definição do banco de dados (DDL), é necessário, por meio de instruções de consulta de dados (DQL), identificar campos vazios ou relacionamentos quebrados. Em seguida, utilizando instruções de manipulação de dados (DML), é preciso corrigir essas situações, garantindo a ausência de campos vazios ou de relacionamentos quebrados. Certifique-se de que todas as alterações implementadas até o momento tenham alcançado o efeito desejado.
Neste ponto, é observado um novo requisito: o fato de alguns países terem mais de um idioma, com um deles sendo designado como o idioma oficial. Nesse contexto, a cardinalidade é de 1 para N, indicando que um país pode ter um ou mais idiomas. Uma possível solução para isso é criar uma tabela chamada "linguagemPais," com a estrutura adequada e um campo referenciando a tabela pai, "pais," por meio da coluna "codigoPais."
CREATE TABLE IF NOT EXISTS linguagemPais ( id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, codigoPais INT(11), linguagem VARCHAR(30) NOT NULL DEFAULT '', oficial ENUM('Sim', 'Não') NOT NULL DEFAULT ‘Não’ ); |
Sendo assim, a primeira tarefa é excluir a coluna “lingua_oficial”, adicionada anteriormente, pois, na nova modelagem, ela não será mais necessária.
| ALTER TABLE pais DROP COLUMN lingua_oficial; |
Após isso, é preciso criar a restrição que assegurará a integridade referencial. Para abordar essa questão, é necessário executar a seguinte instrução:
ALTER TABLE linguagemPais ADD CONSTRAINT FK_linguagemPais FOREIGN KEY (codigoPais) REFERENCES pais(id); |
Após essa execução, a chave estrangeira estará referenciada, permitindo a adição apenas de idiomas associados a países existentes.
Com isso em mente, todas as tabelas definidas devem ter campos destinados a criar restrições e integridades referenciais. Para que um relacionamento seja bem-sucedido, os campos nas tabelas filhas não podem conter valores nulos. Portanto, é necessário revisar novamente o DER do projeto, verificar todas as tabelas e relações e, após a atualização do projeto lógico, implementar fisicamente todas as alterações e inclusões de campos e restrições, garantindo a integridade referencial conforme especificado no DER.
Saiba Mais
Para entender mais sobre constraints no MySQL, acesse o capítulo 15.1.20.5, FOREIGN KEY Constraints, do manual do MySQL 8.3.
ORACLE. MySQL 8.3 Reference Manual. 15.1.20.5 FOREIGN KEY Constraints. MySQL, [s. l.], c2024.
Para complementar o estudo dos comandos de criação de chaves estrangeiras e integridade referencial, sugerimos o capítulo 3 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 3, p. 37-67.
Também sugerimos o acesso ao site W3Schools, mais especificamente à sessão SQL Constraints, que apresenta links com explicações e exemplos para diversos tipos de restrições mais comumente utilizadas.
W3SCHOOLS. SQL Constraints. W3Schools, [s. l.], c2024.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
ORACLE. MySQL 8.3 Reference Manual. 15.1.20.5 FOREIGN KEY Constraints. MySQL, [s. l.], c2024. Disponível em: https://dev.mysql.com/doc/refman/8.3/en/create-table-foreign-keys.html. Acesso em: 2 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
W3SCHOOLS. SQL Constraints. W3Schools, [s. l.], c2024. Disponível em: https://www.w3schools.com/sql/sql_constraints.asp. Acesso em: 2 fev. 2024.
Aula 4
Exclusão de tabelas em banco de dados
Exclusão de tabelas em banco de dados
Olá, estudante! Nesta videoaula, exploraremos temas essenciais para sua prática profissional, como a consistência de dados, os comandos DDL, essenciais para a exclusão de tabelas, e a interconexão entre a exclusão de tabelas e a integridade referencial.
Compreender esses conceitos é vital para a administração eficaz de bancos de dados, por isso prepare-se para aprimorar suas habilidades e seus conhecimentos. Não perca essa oportunidade de enriquecer sua prática profissional.
Vamos lá!
Ponto de Partida
Você está envolvido em um projeto de grande importância em uma empresa multinacional: o desenvolvimento de um guia turístico. No presente momento, seu banco de dados está configurado com uma estrutura sólida e tem relacionamentos estabelecidos. Ao definir chaves primárias e estrangeiras, você implementou restrições nos relacionamentos, assegurando a integridade dos campos e regras para a manutenção dos dados. No entanto, é comum a necessidade de reavaliar e eventualmente excluir estruturas, seja devido a definições atualizadas ou novos requisitos.
Considerando, por exemplo, um GPS, fundamental para determinar localizações por meio de coordenadas de latitude e longitude, você percebeu a importância de armazenar informações precisas sobre pontos turísticos. Embora tenha, inicialmente, incluído esses dados em uma tabela específica, agora você recebeu uma proposta de alteração na tabela de elementos turísticos para incorporar esses campos diretamente. Após essas alterações, a tabela temporária utilizada para essa finalidade pode ser excluída. Adicionalmente, você precisa realizar modificações nas tabelas "Países" e "Cidades", incluindo novos elementos, como uma nota de interesse para turistas e uma lista dos três melhores restaurantes, respectivamente.
Após essas alterações, é importante que você manipule os dados para testar as mudanças implementadas e que, em colaboração com a equipe, discuta as adaptações necessárias a serem feitas no diagrama de entidades e relacionamentos. Esse processo garante que a estrutura do seu banco de dados reflita com precisão a realidade atual.
Ao realizar alterações estruturais que envolvam a exclusão de tabelas, é necessário compreender as limitações e restrições estabelecidas nos relacionamentos entre as tabelas afetadas. Ademais, é essencial compreender as etapas para a exclusão, bem como as instruções SQL necessárias e a definição de novas estruturas resultantes dessas alterações.
Avancemos juntos nesta jornada de aprendizado!
Vamos Começar!
Consistência de dados
Depois que a estrutura do banco de dados foi estabelecida, incluindo todos os campos, tipos de dados, chaves primárias e estrangeiras, torna-se possível realizar a manutenção dos dados, ou seja, efetuar operações de inclusão, alteração e exclusão. No entanto, ao realizar essas ações, é necessário ter estabelecido restrições para assegurar a integridade e a proteção dos relacionamentos entre as tabelas. Suponha que seja necessário excluir uma tabela, modificando sua estrutura. Após essa certificação, ao considerar alterações no banco de dados, é essencial garantir que tais modificações possam ser implementadas sem comprometer as restrições existentes.
Conforme estudado, toda tabela deve ter uma chave primária que identifica um registro específico. Por outro lado, uma chave estrangeira desempenha o papel de conectar duas tabelas, sendo um campo que referencia uma chave primária em outra tabela. A tabela que contém a chave estrangeira é denominada tabela filha, enquanto a que detém a chave candidata, primária ou não, é chamada de tabela pai ou referenciada.
A restrição FOREIGN KEY é empregada para evitar ações que possam romper as relações entre as tabelas, além de prevenir a inserção de dados inválidos na coluna de chave estrangeira, uma vez que ela deve consistir em valores presentes na tabela para a qual aponta. O trecho de código a seguir ilustra essa estrutura com algumas instruções.
CREATE TABLE aluno ( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, nome CHAR(50) NOT NULL ); CREATE TABLE curso ( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, nome CHAR(50) NOT NULL ); CREATE TABLE nota ( aluno_id INT NOT NULL, curso_id INT NOT NULL, dataavaliacao DATE NOT NULL, nota DOUBLE NOT NULL, PRIMARY KEY(aluno_id, curso_id, dataavaliacao), INDEX i2 (curso_id), FOREIGN KEY (aluno_id) REFERENCES aluno(id) ON DELETE CASCADE, FOREIGN KEY (curso_id) REFERENCES curso(id) ON DELETE [ACTION] ); |
Conforme evidenciado na estrutura apresentada, a tabela "nota" incorpora duas restrições, as quais têm como base as seguintes tabelas:
Ambas as tabelas contribuem com suas chaves primárias para estabelecer relacionamentos com a tabela "nota". As referências mencionadas nesse exemplo podem ser verificadas através da instrução a seguir, que apresenta o comando CREATE TABLE responsável pela criação da tabela em questão. É importante observar que, ao executar essa declaração, são necessários privilégios adequados para interagir com essa tabela.
| SHOW CREATE TABLE nome_tabela; |
Ao executar a instrução adiante, os resultados da criação da tabela “nota” podem ser visualizados da seguinte forma:
| SHOW CREATE TABLE nota; |
A execução dessa instrução resultará em uma mensagem, conforme ilustrado na Figura 1.

Na interface indicada na Figura 1, ao efetuar um clique com o botão direito do mouse na linha mencionada e selecionar a opção "COPY FIELD UNQUOTED", obteremos, como saída, a instrução descrita no Quadro 1, conforme exposto a seguir:
1 2 3 4 5 6 7 8 9 10 11 12 13 | CREATE TABLE 'nota' ( 'aluno_id' int NOT NULL, 'curso_id' int NOT NULL, 'dataavaliacao' date NOT NULL, 'nota' double NOT NULL, PRIMARY KEY ('aluno_id','curso_id','dataavaliacao'), KEY 'i2' ('curso_id'), CONSTRAINT 'nota_ibfk_1' FOREIGN KEY ('aluno_id') REFERENCES 'aluno' ('id') ON DELETE CASCADE, CONSTRAINT 'nota_ibfk_2' FOREIGN KEY ('curso_id') REFERENCES 'curso' ('id') ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
Quadro 1 | Instrução. Fonte: elaborado pelo autor.
O conjunto de comandos compreendido entre as linhas 6 (inclusive) e 12 (inclusive) deve ser sempre empregado para identificar as restrições associadas às tabelas que podem ser sujeitas a alterações ou exclusões. Conforme previamente destacado, ao analisarmos esse comando, podemos confirmar que a tabela "nota" é vinculada como filha das tabelas "aluno" e "curso". Qualquer tentativa de excluir a tabela "aluno" ou "curso" está rigidamente controlada, indicando que tal ação não será permitida.
Para ilustrar, as duas restrições criadas automaticamente na tabela "nota" foram denominadas pelo MySQL. A primeira restrição é chamada de "nota_ibfk_1", associada à tabela "aluno", enquanto a segunda restrição é denominada "nota_ibfk_2". Isso ocorre porque, na utilização da instrução para sua criação, conforme a sintaxe adotada, não há um nome explicitamente fornecido.
Siga em Frente...
Comandos DDL utilizados na exclusão de tabelas
Quando o objetivo é remover uma ou mais tabelas, a instrução adequada é o DROP TABLE. Observe que essa instrução elimina não apenas a definição da tabela, mas também todos os dados contidos nela. A sintaxe envolve a enumeração das tabelas que serão afetadas, conforme exemplificado a seguir:
| DROP TABLE [IF EXISTS] nome_tabela [, nome_tabela] … |
Se alguma das tabelas mencionadas na lista de argumentos não existir, a instrução resultará em falha, apresentando um erro que identifica quais tabelas inexistentes não puderam ser removidas, sem realizar nenhuma alteração. Para evitar esse erro, pode-se utilizar a cláusula IF EXISTS, pois, em vez de gerar um erro, ela emite um alerta para cada tabela inexistente. Esse recurso também pode ser útil para eliminar tabelas em situações excepcionais em que há uma entrada no dicionário de dados, embora não delete tabelas gerenciadas pelo mecanismo de armazenamento.
No exemplo apresentado, para verificar a existência da tabela "aluno" antes de executar o comando DROP, utiliza-se a instrução a seguir:
| DROP TABLE IF EXISTS aluno; |
Se a exclusão da tabela "aluno" for inevitável e se houver uma restrição de chave estrangeira que impeça a exclusão, é necessário primeiro excluir a restrição. No caso da tabela "nota", que faz referência à tabela "aluno" (pai), a instrução para remover a restrição seria:
| ALTER TABLE nota DROP FOREIGN KEY nota_ibfk_1; |
Após essa instrução, a exclusão pode ser realizada com sucesso. Esse processo de garantir que todas as restrições declaradas no banco de dados sejam tratadas antes de efetuar alterações na estrutura é essencial.
Exclusão de tabelas e integridade referencial
Neste ponto, é crucial ressaltar a importância da implementação de restrições apropriadas para prevenir erros significativos durante a execução do comando DROP TABLE. A remoção de tabelas implica na eliminação de todos os dados, e, em sistemas nos quais os backups não são instantâneos (quase todos os sistemas em operação), a exclusão inadvertida de uma tabela resultará em perda de dados. Em contextos como o de um sistema de faturamento, um comando de remoção de tabelas aplicado erroneamente pode acarretar prejuízos para a organização. Essa é a razão primordial pela qual estudamos as restrições, compreendendo seu funcionamento e sua sintaxe antes de abordarmos a exclusão de tabelas.
A instrução DROP TABLE não deve ser confundida com a instrução destinada a apagar todo o conteúdo de uma tabela, ou seja, esvaziar a tabela. A instrução para realizar essa ação é a TRUNCATE TABLE, e sua sintaxe é a seguinte:
| TRUNCATE [TABLE] nome_tabela; |
De maneira lógica, a TRUNCATE TABLE assemelha-se a uma instrução DELETE (que exclui todas as linhas) ou a uma sequência de instruções DROP TABLE e CREATE TABLE. Ainda que o comando TRUNCATE TABLE compartilhe semelhanças com o comando DELETE, sua classificação difere do dele, pois é considerado uma instrução da linguagem de definição de dados (DDL), em contraste com o comando DELETE, que pertence à linguagem de manipulação de dados (DML).
A instrução TRUNCATE TABLE falhará para uma tabela se houver alguma restrição FOREIGN KEY de outras tabelas que a referenciem, no entanto, restrições de chaves estrangeiras entre colunas da mesma tabela são permitidas. Desde que a definição da tabela seja válida, é possível recriar a tabela como uma tabela vazia usando TRUNCATE TABLE, mesmo que os dados ou arquivos de índice tenham sido corrompidos.
O campo AUTO_INCREMENT é responsável por ser automaticamente incrementado em cada registro, funcionando naturalmente como uma chave primária, se assim desejado pelo usuário. Qualquer valor AUTO_INCREMENT é redefinido para seu valor inicial.
Há um recurso que deve ser utilizado com cautela: podemos instruir o MySQL a, em circunstâncias especiais, mesmo com restrições em seu banco de dados, ignorá-las. A instrução a seguir exemplifica esse recurso:
| SET FOREIGN_KEY_CHECKS = 1; |
Ao executar essa instrução, o MySQL verificará, antes da exclusão, quais restrições estarão impostas na estrutura do banco de dados. Se definidas como 1 (o padrão), as restrições de chave estrangeira para tabelas são verificadas. Se definidas como 0, serão ignoradas, com algumas exceções. Ao recriar uma tabela que foi descartada, ocorrerá um erro se a definição da tabela não estiver em conformidade com as restrições de chave estrangeira que fazem referência à tabela. Da mesma forma, uma operação ALTER TABLE retornará um erro se uma definição de chave estrangeira for formada incorretamente.
É importante observar que definir 'foreign_key_checks’ como 1 não aciona uma varredura dos dados da tabela existente. Portanto, as linhas adicionadas à tabela enquanto a condição 'foreign_key_checks = 0' for verdadeira não serão verificadas quanto à consistência. Embora essa configuração normalmente permaneça ativada para impor a integridade referencial durante a operação normal, desabilitar a verificação de chave estrangeira pode ser útil ao recarregar tabelas em uma ordem diferente da exigida por seus relacionamentos.
No exemplo apresentado, uma tentativa de excluir a tabela "curso" seria inicialmente malsucedida devido à restrição na tabela "nota", que a referencia. No entanto, ao executar a instrução ‘SET FOREIGN_KEY_CHECKS = 0;', o MySQL é instruído a ignorar quaisquer restrições existentes. Em seguida, ao executar a instrução 'DROP TABLE IF EXISTS curso;', a exclusão da tabela "curso" ocorrerá com sucesso. Após essa operação, é possível restaurar o MySQL ao seu estado padrão, utilizando todas as restrições existentes para alterações de estrutura, ao executar a instrução ‘SET FOREIGN_KEY_CHECKS = 1;'.
Vamos Exercitar?
Ao longo do desenvolvimento do guia turístico, foi inicialmente necessário criar uma tabela para armazenar informações de GPS, como latitude e longitude, associando-as a uma tabela de pontos turísticos para referência. No entanto, uma revisão do projeto revelou que não há mais a necessidade de manter essas informações em uma tabela separada. Para solucionar esse problema, a decisão tomada foi a de realizar alterações na estrutura da tabela de pontos turísticos, que está definida da seguinte forma:
CREATE TABLE IF NOT EXISTS ponto_tur ( id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(50) NOT NULL DEFAULT '', tipo ENUM('Atrativo', 'Serviço', 'Equipamento', 'Infraestrutura', 'Instituição', 'Organização', ‘Patrimônio Público’), publicado ENUM('Não', 'Sim') NOT NULL DEFAULT ‘Não’ ); |
Para efetuar essa alteração, a instrução utilizada é:
| ALTER TABLE ponto_tur ADD coordenada GEOMETRY; |
É importante observar que não foram adicionados campos separados para latitude e longitude, pois no MySQL já é possível criar campos do tipo "Geometry", que nos permite trabalhar com coordenadas, mapas geográficos e, especificamente, com uma coordenada que pode ser representada como um ponto com duas referências, por exemplo: POINT(-23.5111264 -47.4461944).
A tabela anteriormente criada para essa finalidade pode ser excluída utilizando a instrução:
| DROP TABLE IF EXISTS coordenada; |
Para dar continuidade às modificações, seguindo o mesmo modelo e os comandos aprendidos nesta seção, a solicitação é alterar a tabela "Países", incluindo uma nota de 0 a 10, para indicar o interesse turístico no país em questão. Posteriormente, utilize o mesmo procedimento para modificar a tabela "Cidades", incorporando uma lista que contenha os três melhores restaurantes da cidade em foco.
Saiba Mais
Para entender mais sobre exclusão de tabelas no MySQL, acesse o capítulo 15.1.32, DROP TABLE Statement, do manual do MySQL 8.3.
ORACLE. MySQL 8.3 Reference Manual. 15.1.32 DROP TABLE Statement. MySQL, [s. l.], c2024.
Para complementar o estudo dos comandos de criação de chaves estrangeiras e integridade referencial, leia o capítulo 3 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 3, p. 37-67.
Veja, no seguinte site, uma explicação sobre as diferenças e especificidades entre os comandos TRUNCATE e DELETE.
AGUIAR, G. M. Truncate versus Delete – Uma explicação mais detalhada. Gustavo Maia Aguiar, [s. l.], 21 jul. 2010.
Referências Bibliográficas
AGUIAR, G. M. Truncate versus Delete – Uma explicação mais detalhada. Gustavo Maia Aguiar, [s. l.], 21 jul. 2010. Disponível em: https://gustavomaiaaguiar.wordpress.com/2010/07/21/truncate-versus-delete-uma-explicacao-mais-detalhada/. Acesso em: 2 fev. 2024.
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
ORACLE. MySQL 8.3 Reference Manual. 15.1.32 DROP TABLE Statement. MySQL, [s. l.], c2024. Disponível em: https://dev.mysql.com/doc/refman/8.3/en/drop-table.html. Acesso em: 2 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
Encerramento da Unidade
MANIPULAÇÃO DE DADOS E ESTRUTURAS
Videoaula de Encerramento
Olá, estudante! Na videoaula de encerramento desta unidade, você recordará os conhecimentos adquiridos sobre criação e manipulação de tabelas e dados em um banco de dados. Ao compreender os comandos DML, a alteração de tabelas, o uso de constraints e a exclusão de tabelas, você estará apto a aplicar essas competências de forma eficaz em sua prática profissional.
Prepare-se para consolidar seu aprendizado e aprimorar suas habilidades no universo dos bancos de dados. Não perca essa oportunidade de fortalecer sua expertise!
Ponto de Chegada
Olá, estudante! Para desenvolver a competência desta unidade – criar e manipular tabelas e dados em um banco de dados –, você teve de, primeiramente, conhecer os conceitos fundamentais relacionados à manipulação de bancos de dados. Nesse contexto, destacamos o uso dos comandos DML (Data Manipulation Language), que são essenciais para a manipulação eficiente de informações em um banco de dados: inserir, atualizar e excluir dados em tabelas. Esses comandos são cruciais para a criação e manipulação de registros, pois lhe permitem desenvolver a habilidade de gerenciar informações de forma eficaz.
Além disso, a unidade abordou a alteração de tabelas, um aspecto fundamental para a adaptação dinâmica do banco de dados às necessidades do sistema. Após os estudos das aulas, agora você é capaz de realizar modificações na estrutura das tabelas, adicionando ou removendo colunas conforme a evolução dos requisitos do projeto.
Ao longo da unidade você aprendeu também como a utilização de constraints (restrições) é importante, uma vez que lhe proporciona a capacidade de impor regras e garantir a integridade dos dados armazenados. As constraints desempenham um papel crucial na definição de relacionamentos e na aplicação de restrições para preservar a consistência dos dados.
Finalmente, você estudou a exclusão de tabelas em um banco de dados, um ponto de atenção redobrada. Você deve realizar esse processo com cautela, compreendendo os cuidados necessários para evitar perdas irreversíveis e garantir a integridade do sistema.
É Hora de Praticar!
A empresa Doces Sonhos gerencia sua produção de doces em um banco de dados relacional. Assim, a tabela "PRODUTOS" armazena informações sobre cada doce, como nome, descrição, preço e quantidade em estoque. A tabela "INGREDIENTES" armazena os ingredientes de cada doce, com a quantidade utilizada. O SQL de criação dessas tabelas é apresentado a seguir:
CREATE TABLE PRODUTOS ( id_produto INT PRIMARY KEY AUTO_INCREMENT, nome VARCHAR(255) NOT NULL, descricao TEXT, preco INT NOT NULL, quantidade_estoque INT NOT NULL ); CREATE TABLE INGREDIENTES ( id_ingrediente INT PRIMARY KEY AUTO_INCREMENT, nome VARCHAR(255) NOT NULL, quantidade DECIMAL(10,2) NOT NULL, unidade VARCHAR(20) NOT NULL ); CREATE TABLE COMPOSICAO ( id_produto INT NOT NULL, id_ingrediente INT NOT NULL, quantidade_usada DECIMAL(10,2) NOT NULL, PRIMARY KEY (id_produto, id_ingrediente), ); |
A Doces Sonhos está reformulando sua linha de produtos e, com a expansão, precisa atualizar a estrutura do seu banco de dados de modo a torná-lo mais robusto e a atender os requisitos da empresa. Nesse contexto, você será o responsável por essas mudanças, portanto precisa realizar as seguintes alterações no banco de dados:
- Criar a relação entre as tabelas PRODUTO e INGREDIENTES na tabela COMPOSIÇÃO, id_produto e id_ingrediente as chaves estrangeiras das respectivas tabelas.
- Alterar a coluna "PRECO" da tabela "PRODUTOS" para permitir valores decimais com duas casas após a vírgula.
- Adicionar uma nova coluna, "DATA_VALIDADE", à tabela "PRODUTOS" para registrar a data de validade de cada doce.
- Excluir a coluna "DESCRICAO" da tabela "PRODUTOS", pois a empresa decidiu centralizar essas informações em outro sistema.
- Inserir os seguintes dados nas respectivas tabelas:
id_produto | Nome | data_validade | preco | quantidade_estoque |
1 | Brigadeiro | 2024-09-28 | 5.00 | 100 |
2 | Beijinho | 2024-09-12 | 4.00 | 50 |
3 | Pudim | 2024-09-20 | 10.00 | 20 |
Quadro 1 | Produto. Fonte: elaborado pelo autor.
id_ingrediente | nome | quantidade | unidade |
1 | Chocolate | 100 | g |
2 | Leite condensado | 395 | g |
3 | Coco ralado | 50 | g |
4 | Leite | 500 | ml |
5 | Ovos | 3 | unidade |
Quadro 2 | Ingredientes. Fonte: elaborado pelo autor.
id_produto | id_ingrediente | quantidade_usada |
1 | 1 | 100 |
1 | 2 | 395 |
2 | 2 | 395 |
2 | 3 | 50 |
3 | 2 | 395 |
3 | 4 | 500 |
3 | 5 | 3 |
Quadro 3 | Composição. Fonte: elaborado pelo autor.
Vamos lá! Mãos à obra!
Reflita
- Quais são os principais comandos DML utilizados para manipulação de dados em um banco de dados?
- Como as constraints contribuem para a integridade e a consistência dos dados em tabelas?
- Quais são os cuidados essenciais ao excluir tabelas em um banco de dados para garantir a segurança e a integridade do sistema?
Resolução do estudo de caso
Veja, a seguir, a resolução:
1.
ALTER TABLE COMPOSICAO ADD FOREIGN KEY (id_produto) REFERENCES PRODUTO(id_produto);
ALTER TABLE COMPOSICAO ADD FOREIGN KEY (id_ingrediente) REFERENCES INGREDIENTES(id_ingrediente); |
2.
ALTER TABLE PRODUTOS ALTER COLUMN preco DECIMAL(10,2); |
3.
ALTER TABLE PRODUTOS ADD COLUMN data_validade DATE; |
4.
ALTER TABLE PRODUTOS DROP COLUMN descricao; |
5.
INSERT INTO PRODUTOS (id_produto, nome, data_validade, preco, quantidade_estoque) VALUES (1, 'Brigadeiro', '2024-09-28', 5.00, 100), (2, 'Beijinho', '2024-09-12', 4.00, 50), (3, 'Pudim', '2024-09-20', 10.00, 20); INSERT INTO INGREDIENTES (id_ingrediente, nome, quantidade) VALUES (1, 'Chocolate', 100, ‘g’), (2, 'Leite condensado', 395, ‘g’), (3, 'Coco ralado', 50, ‘g’), (4, 'Leite', 500, ‘ml’), (5, 'Ovos', 3, ‘unidades’); INSERT INTO COMPOSICAO (id_produto, id_ingrediente, quantidade_usada) VALUES (1, 1, 100), (1, 2, 395). (2, 2, 395), (2, 3, 50), (3, 2, 395), (3, 4, 500), (3, 5, 3); |
Dê o play!
Assimile

Referências
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.