ESTRUTURA DE UM REPOSITÓRIO DE DADOS
Aula 1
Introdução a Programação em Bancos de Dados
Introdução a Programação em Bancos de Dados
Boas-vindas à nossa videoaula! Neste conteúdo, revisaremos a estrutura essencial de um banco de dados, exploraremos os fundamentos da linguagem de consulta estruturada (SQL) e mergulharemos nas nuances das transações em bancos de dados SQL. Esses conhecimentos são fundamentais para sua prática profissional, pois eles o capacitam a criar e gerenciar bancos de dados eficientes. Não perca a oportunidade de aprimorar suas habilidades! Assista agora ao vídeo e eleve sua expertise em banco de dados.
Ponto de Partida
A programação em bancos de dados está ligada ao domínio da linguagem SQL: por meio das instruções SQL, é possível explorar a definição da estrutura de qualquer banco de dados relacional. Portanto, é preciso que você adquira conhecimentos sobre a ferramenta MySQL, com ênfase na sua versão gráfica, o MySQL Workbench. Essa ferramenta tem a capacidade de executar, de maneira gráfica, todas as tarefas possíveis na versão de linha de comando (command line client).
Diante disso, nesta aula você se familiarizará com as características dos bancos de dados relacionais, terá uma introdução à linguagem de consulta estruturada SQL, compreenderá as particularidades dessa linguagem e explorará as extensões disponíveis.
Para que você possa fixar ainda mais esse conteúdo, imagine-se na seguinte situação: você foi recentemente contratado por uma empresa multinacional para desenvolver um repositório de dados para um projeto de guia turístico, que será implementado utilizando o SGBD MySQL. Na fase inicial desse projeto, é crucial demonstrar aos superiores o seu conhecimento no editor do MySQL. Para isso, você preparará o ambiente de desenvolvimento em sua máquina de trabalho, instalando o MySQL Community Server e, em seguida, incluirá o banco de dados predefinido “world”, deixando, assim, tudo pronto para que, em um momento futuro, você possa demonstrar seu conhecimento prático.
Está preparado para iniciar? Desejo a você bons estudos!
Vamos Começar!
Revisão da estrutura de um banco de dados
Quando abordamos a programação em bancos de dados, estamos explorando dois temas igualmente importantes:
- Programação – Um conjunto de técnicas usado para criar procedimentos estruturados que capacitam os computadores a realizarem tarefas específicas (foco principal deste livro).
- Bancos de dados relacionais – Conjunto de dados estruturados e inter-relacionados, organizados de maneira a permitir eficiência em sua manipulação por meio de uma linguagem formal (nesse caso, o SQL).
Antes de nos aprofundarmos na programação em si, é vital relembrar alguns dos aspectos fundamentais dos bancos de dados. A Figura 1, a seguir, traz uma representação de um banco de dados, a partir da qual podemos fazer uma análise dos principais conceitos.
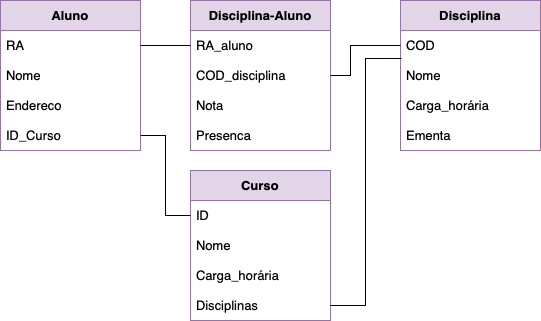
Nessa figura, temos um banco de dados denominado "Universidade" que compreende quatro tabelas:
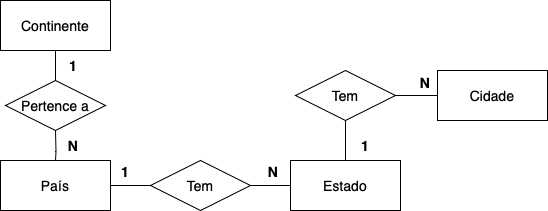
- Aluno – Tabela com uma chave primária associada ao R.A. (Registro Acadêmico) do aluno. Contém informações gerais sobre o aluno, incluindo o nome do curso em que está matriculado na instituição. Detalhes específicos sobre esse curso serão fornecidos em outra tabela. Pode-se presumir que cada aluno está matriculado em apenas um curso, estabelecendo assim uma relação 1:1 com a tabela Curso.
- Curso – Tabela que abriga informações sobre os diversos cursos oferecidos pela universidade (exemplos: Medicina, Engenharia Elétrica, Arquitetura, etc.). Cada um deles apresenta dados sobre carga horária e um conjunto de disciplinas. Há uma relação N:N entre essas tabelas, pois cada curso é composto por várias disciplinas, e cada uma pode ser oferecida em mais de um curso.
- Disciplina – Tabela que tem as informações das diversas disciplinas presentes na universidade, que são identificadas unicamente pela chave primária COD (Código da disciplina).
- Disciplina-Aluno – Estabelece a ligação entre duas tabelas (Disciplina e Aluno) e contém informações sobre as disciplinas que um aluno cursa em determinado semestre.
O banco de dados ilustrado na Figura 1 exemplifica, de maneira simplificada, os bancos de dados encontrados em ambientes profissionais: conjuntos de tabelas que contêm colunas nomeadas, cada uma com um tipo específico de dado. As linhas representam os registros, e as tabelas podem conter informações diversas, coletadas para formar outras tabelas.
Introdução à linguagem de consulta estruturada (SQL)
A linguagem SQL, central nesta disciplina, é a ferramenta utilizada para lidar com diversos aspectos de um banco de dados: sua própria criação, a elaboração das tabelas componentes, a inserção de dados e, sobretudo, a manipulação desses dados para gerar informações úteis em nossos projetos.
A linguagem SQL consolidou-se como a linguagem padrão dos Sistemas de Gerenciamento de Bancos de Dados (SGBD). Seu nome, que significa Structured Query Language (linguagem de consulta estruturada), não abrange completamente sua extensão. Além das instruções de consulta ao banco de dados, é possível criar instruções para:
- Estabelecer esquemas de relacionamento, remover relações e efetuar modificações em estruturas.
- Criar restrições nos relacionamentos, assegurando condições específicas de integridade e proibindo violações.
- Criar visões específicas sobre conjuntos de dados particulares.
- Realizar consultas interativas fundamentadas em álgebra relacional, inclusive operações de inclusão, atualização e exclusão de dados.
- Estipular a segurança do ambiente com controle total de acesso a bancos de dados, tabelas ou campos específicos.
- Determinar todo o controle de transações, garantindo persistência e integridade dos dados.
- Permitir a utilização autônoma ou integrada a outras aplicações.
Durante seus estudos, você utilizará o SGBD MySQL, sistema de código aberto (open source) que é distribuído e respaldado pela Oracle Corporation e que é compatível com diversas plataformas e sistemas, sendo desenvolvido em C e C++. O MySQL possibilita a definição de instruções SQL incorporadas de maneira embutida ou dinâmica na maioria das linguagens de programação, como Node.js, PHP, C#, C++, Java, Android, Swift, para citar apenas algumas
Siga em Frente...
Na linguagem SQL, destacam-se cinco subconjuntos de instruções, conforme elencado a seguir:
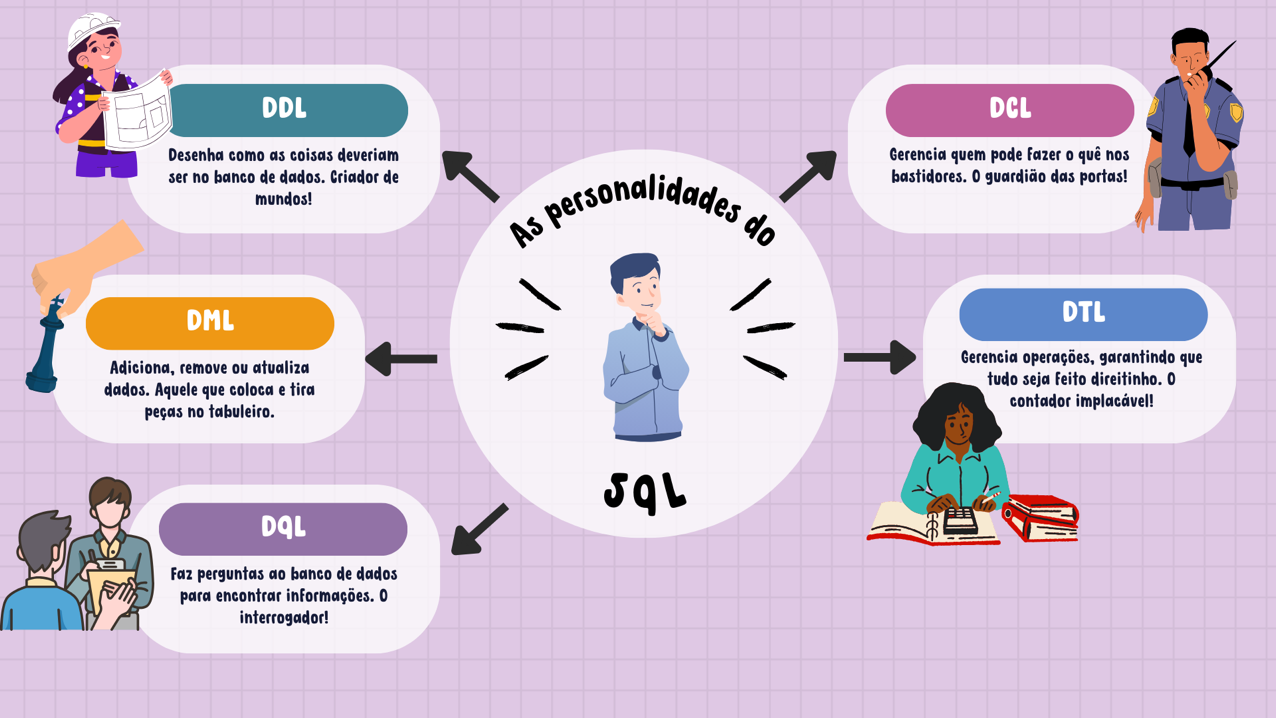
- DDL – Linguagem de definição de dados (do inglês, Data Definition Language): é um conjunto de instruções SQL voltado para a definição dos dados e sua estrutura. As operações incluem o uso de comandos como CREATE, que cria bancos de dados, tabelas e colunas; DROP, responsável por excluir bancos de dados, tabelas e colunas; ALTER, que realiza alterações em bancos de dados, tabelas e colunas; e TRUNCATE, que esvazia completamente uma tabela.
- DML – Linguagem de manipulação dos dados (do inglês, Data Manipulation Language): é um conjunto de instruções SQL direcionado para a inserção e manutenção dos dados. As operações envolvem comandos como INSERT, utilizado para inserir dados em uma tabela; UPDATE, responsável por atualizar dados existentes em uma tabela; e DELETE, que exclui registros de uma tabela.
- DQL – Linguagem de consulta a dados (do inglês, Data Query Language): um conjunto de instruções SQL voltado para a consulta de todos os dados armazenados e suas relações, além de fornecer assistência com comandos de sintaxe. As instruções mais importantes incluem SELECT, principal instrução de consulta do SQL; SHOW, que exibe todas as informações além dos dados (metadata); e HELP, que apresenta informações do manual de referência do MySQL.
- DCL – Linguagem de controle de dados (do inglês, Data Control Language): é um conjunto de instruções SQL destinado ao controle de autorizações de acesso e níveis de segurança. As principais instruções são GRANT, que concede privilégios a contas de usuário, e REVOKE, que revoga os privilégios de uma conta de usuário.
- DTL – Linguagem de transação de dados (do inglês, Data Transaction Language): é um conjunto de instruções para o controle de transações lógicas agrupadas e executadas por comandos DML. As principais instruções incluem START TRANSACTION, que inicia uma nova transação; SAVEPOINT, que identifica um ponto específico em uma transação; COMMIT, que entrega as alterações ao SGBD, tornando-as permanentes; ROLLBACK [TO SAVEPOINT], que reverte toda a transação, cancelando alterações até um determinado ponto; e RELEASE SAVEPOINT, que remove um SAVEPOINT específico.
Transação em bancos de dados SQL
Um conceito muito importante e que será utilizado a todo momento em seus estudos de bancos de dados é a definição de transação em bancos de dados SQL: sequência de operações executadas como uma única unidade lógica de trabalho. Essas operações podem incluir inserções, atualizações, exclusões e consultas. O conceito de transação é fundamental para garantir a integridade dos dados, pois permite que as operações sejam executadas de maneira atômica, consistente, isolada e durável – propriedades conhecidas como as propriedades ACID.
- Atomicidade: todas as operações em uma transação são tratadas como uma unidade indivisível: ou todas as operações são concluídas com sucesso, ou nenhuma delas é aplicada. Se uma operação falhar, a transação é revertida para o estado anterior.
- Consistência: a transação leva o banco de dados de um estado consistente para outro estado consistente. Isso significa que as restrições de integridade do banco de dados devem ser mantidas antes e após a execução da transação.
- Isolamento: cada transação é executada de forma isolada das outras. As modificações feitas por uma transação são invisíveis para outras transações até que a primeira seja concluída. Isso ajuda a evitar interferências e inconsistências causadas por operações concorrentes.
- Durabilidade: uma vez que uma transação é concluída com sucesso, suas alterações tornam-se permanentes no banco de dados, mesmo em caso de falha do sistema. Isso garante que as modificações sobrevivam a eventos como quedas de energia ou falhas no hardware.
O processamento de transações em bancos de dados relacionais é uma parte essencial do gerenciamento de dados, garantindo a integridade, a consistência e a confiabilidade das operações realizadas no ambiente do banco de dados. Esse processamento envolve a execução eficiente e segura de transações no ambiente de um banco de dados. A seguir, exploraremos alguns desses conceitos-chave.
- Início de transação (BEGIN): marca o início de uma transação. A partir desse ponto, as operações realizadas são tratadas como parte da transação até serem confirmadas ou revertidas.
- Confirmação (COMMIT): confirma todas as operações realizadas durante a transação. Isso torna as alterações permanentes no banco de dados.
- Reversão (ROLLBACK): desfaz todas as operações realizadas durante a transação. Isso restaura o banco de dados ao estado anterior à transação.
- Ponto de salvar (SAVEPOINT): permite definir pontos intermediários dentro de uma transação. Isso facilita o ROLLBACK para um estado específico em vez de reverter a transação inteira.
- Controle de concorrência: garante que transações concorrentes não causem problemas como leitura suja, leitura não repetível ou escrita fantasma. Mecanismos como bloqueios e isolamento transacional são empregados para gerenciar a concorrência.
- Log de transações: mantém o registro de todas as transações realizadas. Isso é crucial para a recuperação após falhas e para garantir a consistência do banco de dados.
Vamos Exercitar?
No início desta aula, você foi apresentado a uma situação-problema bem simples: mostrar todo o seu conhecimento na manipulação e na consulta de banco de dados com a linguagem SQL. O SGBD utilizado na empresa é o MySQL Server, e você precisará, neste primeiro, momento instalá-lo em sua máquina de trabalho e configurar o banco de dados “world” (banco de dados pré-existente do MySQL). Assim, você mostrará que está apto a manipular o SGBD.
O primeiro passo é instalar o MySQL Server. Para isso, utilizaremos a versão Community, cuja instalação é gratuita. Acesse o site do MySQL Community Server e instale a versão mais recente, incluindo o Command Line Client (para acesso via linha de comando) e o MySQL Workbench (para acesso via interface gráfica).
Com o MySQL instalado e funcionando, basta carregar o banco de dados predefinido “world”, seguindo as instruções a seguir no MySQL Workbench:
1.Acesse a página de download.
2.Em seguida, encontre o link para download do arquivo conforme a figura a seguir (prefira baixá-lo no formato .Zip):

3.Descompacte o arquivo e abra o arquivo world.sql na sua instância do MySQL (você tem de estar conectado no banco).
4.Por fim, basta executar todo o script SQL como qualquer outro.
5.Pronto! Atualize a lista de SCHEMAS no painel lateral esquerdo e você verá o banco de dados “world”.
Saiba Mais
Para relembrar os conceitos de modelagem de banco de dados, fica como sugestão a leitura dos capítulos de 1 a 4 do livro Banco de dados: projeto e implementação, disponível na Biblioteca Virtual.
- MACHADO, F. N. R. Banco de dados: projeto e implementação. São Paulo: Saraiva, 2020. E-book.
Outra sugestão é a leitura do capítulo 8 do livro Banco de dados: projeto e implementação, disponível na Biblioteca Virtual, para relembrar um conceito muito importante no projeto de banco de dados: normalização de dados
- MACHADO, F. N. R. Banco de dados: projeto e implementação. São Paulo: Saraiva, 2020. E-book. cap. 8, p. 172-199.
A fim de ampliar o conhecimento sobre os fundamentos da linguagem SQL, leia o capítulo 4 do livro Introdução a sistemas de banco de dados, também disponível na Biblioteca Virtual.
- DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book. cap. 4, p. 70-84.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
MACHADO, F. N. R. Banco de dados: projeto e implementação. São Paulo: Saraiva, 2020. E-book.
ORACLE. Other MySQL Documentation. MySQL, [S. l.], c2024. Disponível em: https://dev.mysql.com/doc/index-other.html. Acesso em: 29 jun. 2024.
Aula 2
Linguagem de consulta de dados
Linguagem de consulta de dados
Prepare-se para uma videoaula imperdível, estudante! Nela, abordaremos a estrutura básica da linguagem de consulta de dados (DQL), desvendaremos as cláusulas SELECT, FROM e WHERE para aperfeiçoar suas habilidades de consulta e exploraremos também as extensões de consultas que potencializam sua eficácia.
Esses conhecimentos são essenciais para sua prática profissional, pois tornarão suas análises de dados mais precisas. Não fique de fora, aprimore suas habilidades agora!
Ponto de Partida
Nesta aula você aprenderá a realizar buscas simples em bancos de dados e compreenderá as principais instruções utilizadas para este fim.
Para reforçar seu aprendizado, retomemos a situação-problema que já lhe foi apresentada na aula anterior: você, estudante, foi contratado por uma empresa multinacional para desenvolver um banco de dados para um projeto de guia turístico, que será implementado utilizando o SGBD MySQL. Neste primeiro momento, como você está na fase de demonstrar aos superiores seu conhecimento na manipulação de um banco de dados, utilizará instruções SQL na exploração de um banco de dados já existente no MySQL Server.
Nesse contexto, você precisará empregar instruções SQL para compreender a estrutura de tabelas, identificar chaves primárias e estrangeiras e determinar os relacionamentos entre as tabelas, permitindo, assim, a formulação de instruções de consultas. Como são utilizados os editores SQL do MySQL? Como acessar um banco de dados específico? Quais instruções são úteis para consultar a estrutura? Como definir um relacionamento no banco de dados? É possível extrair informações desses relacionamentos?
Bons estudos!
Vamos Começar!
Linguagem de consulta de dados (DQL): estrutura básica de consultas
No contexto de um repositório de dados, é essencial recordar que a definição de tabelas se baseia em princípios, incluindo o de que cada tabela é uma relação, na qual o conjunto de uma linha e algumas colunas é denominado tupla. Cada coluna tem um nome único, representando um domínio distinto. A ordem dos registros e dos campos é irrelevante; não podem existir dois registros idênticos; e cada tabela deve ser identificada de maneira única no banco de dados com um nome próprio.
Em um Sistema de Gerenciamento de Banco de Dados (SGBD) relacional, os repositórios de dados são armazenados em tabelas identificáveis de maneira única. As instruções SQL permitem valores nulos em campos de tabelas para indicar a inexistência ou desconhecimento do valor e possibilitam a especificação explícita de campos que não podem conter valores nulos.
Na linguagem de consulta a dados (DQL), a instrução básica é composta por três cláusulas: SELECT (identificação dos campos desejados em uma consulta), FROM (listagem das tabelas a serem lidas) e WHERE (expressões lógicas envolvendo os campos das tabelas). A combinação dessas três cláusulas produz uma consulta que resulta de produto cartesiano das tabelas especificadas na cláusula FROM, que é filtrada pelas condições da cláusula WHERE e na qual se aplicam os resultados nos campos indicados na cláusula SELECT.
O produto cartesiano, representando conjuntos multiplicados por seus pares ordenados, implica que as consultas SQL resultem na multiplicação da quantidade de registros das tabelas mencionadas, destacando a importância de estabelecer condições precisas para evitar resultados vastos e imprecisos, que podem acarretar alto custo de processamento. Um exemplo de consulta precisa é apresentado como:
SELECT nome, nascimento, cpf FROM clients WHERE cpf = ‘12345678901’ |
Em contraste, uma consulta imprecisa, como SELECT * FROM clientes, pode resultar em um produto cartesiano enorme e indesejado.
Antes de efetuar qualquer consulta ou interação no editor SQL, é crucial garantir que o acesso esteja direcionado ao banco de dados desejado. Caso deseje acessar o banco intitulado "mundo", é recomendável empregar inicialmente a instrução:
| USE mundo; |
Ela estabelece ou modifica o banco no qual as operações serão realizadas. Para visualizar todas as definições associadas a uma tabela específica, como a tabela "cidade", utilize a instrução:
| SHOW COLUMNS FROM cidade; |
Essa ação resultará na apresentação de uma tabela que inclui os nomes dos campos e suas respectivas propriedades.
Consultas com as cláusulas SELECT, FROM e WHERE
O resultado obtido de uma consulta SQL é uma tabela, e, para compreendermos essas consultas, utilizaremos o banco de dados "mundo", composto pelas tabelas:
- cidade (Id, Nome, CodigoPais, Estado, Populacao).
- pais (Codigo, Nome, Continente, Regiao, Area, Populacao).
- linguapais (CodigoPais, Lingua, Oficial, Porcentagem).
Exemplificaremos, a seguir, com uma consulta simples em nosso banco de dados de fictício: "Encontre os nomes de todas as cidades na tabela cidade". A consulta correspondente é:
SELECT Nome FROM cidade; |
O resultado dessa instrução será uma tabela com apenas um campo, identificado pelo cabeçalho Nome. É importante observar que o SQL permite resultados duplicados. Isso significa que, se houver registros na tabela cidade com conteúdo igual, ele será exibido. No entanto, é possível explicitamente eliminar duplicidades usando a palavra-chave DISTINCT, como mostrado na consulta a seguir:
SELECT DISTINCT Nome FROM cidade; |
Podemos usar o símbolo "*" para indicar "todos os campos" e, assim, retornar todas as colunas da tabela, conforme demonstrado na consulta a seguir:
SELECT * FROM cidade; |
Na cláusula SELECT, é possível incluir expressões aritméticas utilizando operadores como +, -, *, e /. Por exemplo:
SELECT Nome, Populacao / 2 FROM cidade; |
Siga em Frente...
Essa instrução exibirá uma tabela com os campos "Nome" e "Populacao", sendo que o valor de "Populacao" será dividido por 2. Além disso, é importante destacar que o SQL oferece operações com datas, tipos especiais e outras funções aritméticas.
Para aprofundarmos nosso entendimento sobre a cláusula WHERE, consideremos a seguinte consulta: "Localize todos os nomes de cidades cuja população seja inferior a 100.000". Para realizar essa busca, execute o seguinte comando:
SELECT Nome, Populacao FROM cidade WHERE Populacao < 100000; |
Os conectivos AND, OR e NOT podem ser empregados como subqualificadores para a cláusula WHERE. Além disso, operadores de comparação como <, <=, >, >=, = e <> são aplicáveis não apenas com strings e expressões aritméticas, mas também com tipos especiais e datas.
Uma maneira de simplificar algumas operações com a cláusula WHERE é através do uso do operador BETWEEN, como exemplificado a seguir:
SELECT Nome, Populacao FROM cidade WHERE Populacao BETWEEN 90000 AND 100000; |
Isso equivale a:
SELECT Nome, Populacao FROM cidade WHERE Populacao >= 90000 AND Populacao <= 100000; |
Alternativamente, podemos empregar o operador de comparação NOT BETWEEN, como demonstrado na consulta a seguir:
SELECT Nome, Populacao FROM cidade WHERE Populacao NOT BETWEEN 60000 AND 70000; |
Conforme mencionado anteriormente, a cláusula FROM gera um produto cartesiano das tabelas especificadas nela. Portanto, para a consulta "Encontre todos os nomes e populações das cidades e línguas do seu país", o comando é o seguinte:
SELECT cidade.Nome, cidade.Populacao, linguapais.Linguagem FROM cidade, pais, linguapais WHERE cidade.CodigoPais = pais.Codigo AND pais.Codigo = linguapais.CodigoPais; |
É importante notar que, na instrução SQL, estamos utilizando a notação nome-tabela.nome-campo. Essa prática é adotada para evitar ambiguidades, uma vez que alguns campos têm nomes idênticos em tabelas distintas, como é o caso dos campos "CodigoPais" e "Nome", por exemplo.
Podemos aplicar a mesma abordagem para a consulta que busca cidades que falem português, com a seguinte sintaxe:
SELECT cidade.Nome, cidade.Populacao, linguapais.Linguagem FROM cidade, pais, linguapais WHERE cidade.CodigoPais = pais.Codigo AND pais.Codigo = linguapais.CodigoPais AND linguaPais.Linguagem = "Português"; |
Extensões de consultas
Os campos têm a capacidade de serem rebatizados por meio da cláusula AS, da seguinte maneira:
nome-antigo AS nome-novo
Essa cláusula é aplicável tanto em SELECT quanto em FROM. Empregando alguns exemplos anteriores, a utilização seria a seguinte:
SELECT Nome, Populacao AS PopulacaoDaCidade FROM cidade; |
Como resultado, obteremos uma tabela com o campo "Populacao" renomeado para "PopulacaoDaCidade".
É possível também utilizar a cláusula AS para a definição de variáveis de registro, que estão associadas a uma tabela específica. Tais variáveis são estabelecidas na cláusula FROM. Como ilustração, a consulta "Encontre todos os nomes e populações das cidades e línguas do seu país" pode ser realizada através da seguinte sintaxe:
SELECT C.Nome, C.Populacao, L.Linguagem FROM cidade AS C, pais AS P, linguapais AS L WHERE C.CodigoPais = P.Codigo AND P.Codigo = L.CodigoPais; |
No que diz respeito a operações de strings e ordenação, o operador LIKE é empregado para determinar correspondência de padrões, utilizando caracteres especiais, tais como:
- Porcentagem (%): corresponde a qualquer substring.
- Sublinhado (_): corresponde a qualquer caractere.
Como exemplo, a consulta "Encontre os nomes de todas as cidades na tabela cidade com nomes iniciados por 'Sor'" pode ser realizada com a seguinte sintaxe:
SELECT Nome FROM cidade WHERE Nome LIKE 'Sor%'; |
Outra cláusula relevante é a ORDER BY, que gerencia a ordenação dos registros com base no campo especificado, como na consulta "Encontre os nomes de todas as cidades na tabela cidade, ordenadas por nome":
SELECT Nome FROM cidade ORDER BY Nome; |
Por padrão, essa cláusula ordena de forma ascendente, mas é possível explicitar essa ordem utilizando ASC ou, alternativamente, DESC para ordenar de maneira decrescente. Como exemplo, a seguinte sintaxe realiza a busca "Encontre os nomes de todas as cidades na tabela cidade ordenados por nome em ordem decrescente":
SELECT Nome FROM cidade ORDER BY Nome DESC; |
Vamos Exercitar?
Para iniciar a resolução da situação-problema, vamos investigar a estrutura do banco de dados "world". No editor SQL, é necessário primeiro indicar ao MySQL qual é a base de trabalho padrão:
| USE world; |
Após esse passo, todas as instruções SQL serão direcionadas para o banco de dados identificado. Agora, é possível explorar a estrutura dessa base executando a instrução:
| SHOW TABLES; |
Nesse ponto, todas as tabelas que compõem o banco de dados "world" serão listadas, como: "city", "country" e "countrylanguage".
Com os nomes das tabelas identificados, é possível visualizar os campos de cada uma por meio da instrução:
| SHOW COLUMNS FROM nome-tabela; |
Vamos examinar a estrutura da tabela "city" como exemplo:
| SHOW COLUMNS FROM city; |
O resultado apresentará uma tabela com seis colunas, cada uma representando uma propriedade do campo, como "Field" (campo), "Type" (tipo), "Null" (pode conter valor nulo), "Key" (chave), "Default" (valor padrão) e "Extra" (características especiais). Cada linha dessa tabela representa um campo, indicando que a tabela "city" é composta por cinco campos: ID, Name, CountryCode, District, Population.
Agora vamos realizar algumas consultas básicas:
SELECT Name FROM city WHERE Name LIKE 'Sor%';
SELECT Name, Population FROM city WHERE Name LIKE 'Sor%';
SELECT city.Name, city.Population, country.Name FROM city, country WHERE city.Name LIKE 'Sor%' AND city.CountryCode = country.Code; |
Dessa forma, demonstra-se o conhecimento necessário para avançar para a próxima etapa.
Saiba Mais
Para conhecer outras instruções e aprofundar seus conhecimentos nas instruções SQL, acesse o capítulo 13, SQL Statements, do manual do MySQL 8.3.
ORACLE. MySQL 8.3 Reference Manual – Including MySQL NDB Cluster 8.3. [S. l.]: ORACLE, c2024.
Para complementar o estudo das consultas e da extensão de consultas, leia o capítulo 4 do livro Sistema de banco de dados, disponível na Biblioteca Virtual.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 3, p. 37-67.
Outra sugestão é a leitura do capítulo 6 do livro Sistemas de banco de dados (disponível na Biblioteca Virtual 3.0), que apresenta fundamentos de SQL básicos para complementar os estudos desta aula.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
ORACLE. MySQL 8.3 Reference Manual – Including MySQL NDB Cluster 8.3. [S. l.]: ORACLE, c2024. Disponível em: https://downloads.mysql.com/docs/refman-8.3-en.pdf. Acesso em: 22 jan. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
Aula 3
Criação de banco de dados
Criação de banco de dados
Explore conosco, caro estudante, o universo do planejamento de bancos de dados, da internacionalização e dos comandos DDL. Por ser essencial à sua prática profissional, você aprenderá a estruturar e a otimizar bancos de dados, garantindo eficiência. Além disso, desvendaremos a linguagem de definição de dados (DDL), focando nos comandos de criação de bases sólidas. Não perca essa oportunidade de aprimorar suas habilidades. Junte-se a nós nesta videoaula essencial!
Ponto de Partida
Olá, estudante! Nesta aula, você aprenderá a criar um banco de dados utilizando a linguagem SQL. Para isso, avancemos na situação-problema apresentada nas aulas anteriores: agora, você está envolvido no projeto de elaboração de um aplicativo para o serviço de guia turístico da empresa multinacional que o contratou. Ao conceber esse aplicativo, é necessário que ele siga a estrutura da vida real, na qual os elementos turísticos estão vinculados a cidades, que compõem estados, que, por sua vez, constituem países. O guia turístico em desenvolvimento terá a capacidade de apresentar informações tanto nacionais quanto internacionais.
Diante desse contexto, sua responsabilidade inclui criar uma representação abstrata dessa realidade por meio de um diagrama entidade-relacionamento, um documento que deve ser constantemente atualizado ao longo do projeto para servir como referência ao banco de dados. Essa atualização frequente é importante para manter o controle sobre o documento e, assim, possibilitar a identificação de alterações.
Além disso, um fator técnico crucial é considerado na linguagem utilizada: o banco de dados deve suportar caracteres acentuados e estar preparado para a internacionalização. Essas configurações precisam ser especificadas durante a criação do banco. Após atentar-se para esses requisitos e compreender o uso correto das instruções SQL, você dará os primeiros passos na construção do banco de dados. Nessa fase inicial, é necessária uma extensa fase de planejamento e elaboração de rascunhos para definir as características do banco, proporcionando conhecimento e certeza na prevenção de potenciais problemas.
Durante a criação do banco de dados, é essencial compreender questões de internacionalização e identificar elementos que possam limitar sua utilidade. Nesse sentido, as propriedades de um banco de dados são fundamentais para determinar como os dados serão armazenados e como devem ser cuidadosamente estudados por todos os profissionais de tecnologia.
Bons estudos!
Vamos Começar!
Planejamento de um banco de dados
O planejamento de um banco de dados não apenas aborda a forma como os dados serão armazenados, mas define também a sua estrutura, denominada de metadados: dados que descrevem a estrutura de um banco de dados.
No processo de planejamento do banco de dados, há cinco passos principais, conforme descrito a seguir:
- Coletar informações: compreender o propósito do banco de dados, sua abrangência e público-alvo. Identificar limitações e problemas para superá-los na definição da estrutura.
- Identificar principais estruturas: reconhecer as principais entidades, ou seja, as tabelas que serão gerenciadas pelo banco de dados. Essas tabelas representam objetos tangíveis ou intangíveis, como pessoas, locais, clientes, cidades, vendas, reclamações, autorizações de compra, entre outros.
- Modelar a estrutura: documentar as principais tabelas através de um diagrama entidade-relacionamento (DER), que serve como registro intelectual e precisa ser constantemente atualizado para promover a compreensão de outras pessoas.
- Identificar tipos de dados nas estruturas: detalhar os tipos de dados a serem armazenados, incluindo números inteiros, decimais, cadeias de caracteres, datas, etc. Classificar essas informações em dados brutos, dados de categorização, dados de identificação e dados de relação ou referência.
- Identificar relacionamentos: demonstrar a razão pela qual um banco de dados relacional existe, estabelecendo associações e relacionamentos entre as tabelas para gerenciar integridades, consultas e relações lógicas de agregação ou desagregação de dados.
- O planejamento de um banco de dados é essencial antes de sua implementação, exigindo a execução cuidadosa de cada passo. Ao final do processo, um diagrama entidade-relacionamento (DER) é obtido, orientando as atividades de implementação e facilitando o compartilhamento de conhecimentos com a equipe.
Internacionalização de um banco de dados
É uma consideração essencial durante o desenvolvimento, pois os dados armazenados devem respeitar as regras de escrita, gramática ou representação específicas de cada país. Sistemas gerenciadores de bancos de dados, incluindo o MySQL, oferecem cláusulas especiais para lidar com essas questões, sendo duas delas o CHARSET e o COLLATION.
Ao explorar essas cláusulas, é importante refletir sobre experiências em que você tenha se deparado com palavras grafadas de maneira incorreta em aplicativos ou sites. Esses erros muitas vezes não são relacionados ao conteúdo, mas a falhas na apresentação, especialmente no que diz respeito ao entendimento adequado do CHARSET e do COLLATION.
O CHARSET, literalmente um conjunto de caracteres, refere-se a símbolos e codificações que determinam como eles são representados binariamente. Por outro lado, o COLLATION estabelece regras para a comparação entre caracteres dentro desse conjunto.
O MySQL oferece suporte a uma variedade de conjuntos de caracteres e a seus agrupamentos de regras de comparação correspondentes. Para verificar quais conjuntos de caracteres estão disponíveis em seu MySQL, você pode utilizar a seguinte instrução:
| SHOW CHARACTER SET; |
Essa instrução apresentará todos os conjuntos de caracteres disponíveis, mas, para uma análise mais específica, concentraremos nossa atenção em dois deles: "latin1" e "UTF-8". Para obter informações detalhadas sobre o conjunto de caracteres "latin1", você pode utilizar a seguinte instrução:
| SHOW CHARACTER SET WHERE charset LIKE 'latin1'; |
Essa instrução fornecerá detalhes, incluindo a descrição ("DESCRIPTION") como "cp 1252 West European", e, por padrão, o conjunto de regras associado ("DEFAULT COLLATION") será "latin1_swedish_ci". Agora, para obter informações sobre o conjunto de caracteres "UTF-8", você pode empregar a instrução a seguir:
| SHOW CHARACTER SET WHERE charset LIKE 'utf8'; |
Essas instruções permitem-lhe explorar e compreender os conjuntos de caracteres disponíveis no MySQL e auxiliam na escolha adequada para atender às necessidades específicas do projeto.
O banco de dados é caracterizado pela descrição (DESCRIPTION) "UTF-8 Unicode" e, por padrão, pelo conjunto de regras associado (DEFAULT COLLATION) é "utf8_general_ci".
A distinção entre eles é bastante simples: considere diversas línguas com todos os caracteres e símbolos que as abrangem. Agora, concentre-se apenas nas línguas de base latina, dentre as quais incluímos o português. Nesse subconjunto, o português conta com um conjunto de caracteres significativamente menor. O UTF-8 engloba muitas línguas, enquanto o "latin1" abrange apenas uma parte delas. Portanto, aplicações com uso internacional mais amplo devem preferir o padrão UTF-8.
É relevante observar que, no MySQL, cada conjunto de caracteres (CHARSET) já possui um conjunto de regras associado (COLLATION). No entanto, para exibir todas as instruções instaladas, você pode utilizar a seguinte instrução:
| SHOW COLLATION; |
Para visualizar o conjunto de regras associado ao UTF-8, utilize a instrução:
| SHOW COLLATION WHERE collation LIKE 'utf8_general_ci'; |
Perceba que alguns conjuntos de regras apresentam o sufixo "_ci" ou "_cs". O sufixo "CI" (case insensitive) indica que não há distinção entre maiúsculas e minúsculas em todas as regras, enquanto o "CS" (case sensitive) já revela que há tal distinção. Por exemplo, pesquisas com a palavra "moura" retornarão resultados como "Moura", "MOURA" ou "moura" no caso de "CI", enquanto apenas "moura" retornará no caso de "CS".
Siga em Frente...
Linguagem de definição de dados (DDL): comandos para a criação de um banco de dados
Para criar um banco de dados, é necessário utilizar as instruções da classe linguagem de definição de dados (DDL). A seguinte sintaxe tem como objetivo criar um banco de dados com o nome especificado:
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [create_specification] … create_specification: [DEFAULT] CHARACTER SET [=] charset_name | [DEFAULT] COLLATE [=] collation_name |
Essa instrução cria um banco de dados com o nome fornecido. CREATE SCHEMA é um sinônimo para CREATE DATABASE. Um erro ocorrerá se o banco de dados já existir e IF NOT EXISTS não for especificado. As opções “create_specification” identificam características do banco de dados, como seu conjunto de caracteres (CHARACTER SET) e o conjunto de regras de comparação (COLLATE). Essas características são armazenadas no arquivo db.opt no diretório do banco de dados.
Para criar um banco de dados chamado "mundo", com CHARSET UTF-8 e COLLATION "utf8_general_ci", a instrução seria:
CREATE DATABASE mundo DEFAULT CHARSET = utf8 DEFAULT COLLATE = utf8_general_ci; |
Após a execução, você pode visualizar o banco de dados utilizando a instrução SHOW DATABASES.
Se houver a necessidade de alterar CHARSET ou COLLATION do banco de dados, a instrução apropriada é:
ALTER {DATABASE | SCHEMA} [db_name] alter_specification … alter_specification: [DEFAULT] CHARACTER SET [=] charset_name | [DEFAULT] COLLATE [=] collation_name |
Para alterar o CHARSET do banco de dados "mundo" para "latin1", pode-se usar, por exemplo, esta instrução:
| ALTER DATABASE mundo CHARSET = latin1; |
É essencial ter precaução com a instrução seguinte, pois ela resultará na exclusão do banco de dados:
| DROP {DATABASE | SCHEMA} [IF EXISTS] db_name |
A execução desse comando apagará o banco de dados especificado em “db_name” (nome do banco de dados).
Todas as instruções SQL podem ser organizadas em um arquivo de texto chamado Script, amplamente utilizado para a criação de bancos de dados. No Script, os comandos SQL devem seguir uma ordem lógica de execução e, durante o aprendizado, é possível criar um Script de estudo para testar os comandos.
Vamos Exercitar?
Você faz parte de uma empresa que está desenvolvendo um aplicativo para o serviço de guia turístico e está dando continuidade ao projeto. Para a definição da abrangência do banco de dados, considera-se que ele terá alcance internacional, estando preparado para uma possível utilização global. Antes de criar o banco de dados, as discussões sobre as tabelas básicas já devem ter sido iniciadas.
A estrutura inicial proposta contempla as seguintes tabelas:
- Países: serão armazenados dados como nome, continente, área, ano de independência, população, expectativa de vida, forma de governo, capital e moeda.
- Estados: serão registradas informações quanto a nome, sigla, região e capital.
- Cidades: haverá dados como nome, população e data de criação.
- Pontos de interesse turístico: serão englobados atrativos turísticos, serviços e equipamentos turísticos, infraestrutura de apoio ao turismo e instituições ou organizações relacionadas ao turismo.
Para garantir a internacionalização do banco de dados, o UTF-8 (encoding) é utilizado como conjunto de caracteres para aplicações internacionais. A criação do banco de dados ocorre com a seguinte instrução:
CREATE DATABASE IF NOT EXISTS gt DEFAULT CHARSET = utf8 DEFAULT COLLATE = utf8_general_ci; |
Ao executar essa instrução, o MySQL configura a base de dados com a codificação UTF-8, permitindo a inclusão de caracteres internacionais. O padrão de pesquisa para esse banco segue as regras comuns de comparação do "utf8_general_ci", o que demonstra não haver diferenciação entre caracteres maiúsculos e minúsculos durante as consultas.
Saiba Mais
Para entender melhor outros conceitos fundamentais para o projeto de criação de um banco de dados, leia o capítulo 6 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 6, p. 132-167.
A seguinte página apresenta, de forma simples e intuitiva, um complemento aos conceitos de CHARSET e COLLATION.
CAMPOS, V. Criando databases: qual charset usar? Vitor Campos, [s. l.], 23 mar. 2023.
Outra sugestão é a leitura do capítulo 13 do livro Banco de dados: projeto e implementação, disponível na Biblioteca Virtual, que apresenta os fundamentos de criação de bancos de dados.
MACHADO, F. N. R. Banco de dados: projeto e implementação. São Paulo: Saraiva, 2020. E-book.
Referências Bibliográficas
CAMPOS, V. Criando databases: qual charset usar? Vitor Campos, [s. l.], 23 mar. 2023. Disponível em: https://vitorcampos.com.br/2023/03/criando-databases-qual-charset-usar/. Acesso em: 22 jan. 2024.
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
MACHADO, F. N. R. Banco de dados: projeto e implementação. São Paulo: Saraiva, 2020. E-book.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
Aula 4
Criação de tabelas
Criação de tabelas
Estudante, venha explorar, nesta videoaula, a fundação do design de banco de dados! Ao longo dela, mergulharemos na estrutura e nos elementos cruciais para a criação de tabelas e dominaremos os comandos DDL essenciais, detalhando identificadores e tipos de dados.
Esses conhecimentos são fundamentais para sua prática profissional, pois lhe permitem a criação de bases sólidas de conhecimento. Não perca essa oportunidade de fortalecer suas habilidades. Assista à videoaula agora!
Ponto de Partida
Olá, estudante! Nesta aula, abordaremos as instruções para criação de tabelas, conteúdo de extrema importância, já que, em um banco de dados, várias tabelas são utilizadas, cada uma representando, de maneira matricial, com suas linhas e colunas, dados que podem, em suas relações, representar informações.
No contexto de seu trabalho para a empresa que está desenvolvendo um guia turístico, você foi encarregado de implementar o repositório de dados que armazenará as informações do aplicativo, para o qual já foi criado um banco de dados e em que foram utilizadas instruções para consultas. Além disso, a estrutura das tabelas que comporão o banco de dados já foi planejada.
Agora, sua responsabilidade no projeto é implantar, por meio de tabelas, a estrutura do repositório de dados do guia turístico. Para tanto, é necessário finalizar o diagrama entidade-relacionamento. Há ainda a necessidade de definir os principais campos em cada tabela, seus tipos de dados e a forma como os pontos de interesse turístico serão organizados, classificados como atrativos, serviços, equipamentos, infraestrutura de apoio e instituições ou organizações. Adicionalmente, é preciso criar uma tabela extra para armazenar as coordenadas de latitude e longitude, pois algumas funcionalidades poderão utilizar um GPS. Cada elemento turístico também deve ter um campo indicando se está publicado ou não, sendo que o valor padrão é falso.
Para ajudá-lo na resolução desse desafio, nesta aula, exploraremos os conceitos relacionados à criação de tabelas, compreenderemos a estrutura e os identificadores utilizados nesse processo e discutiremos como esses elementos afetam as propriedades das tabelas. Com esses conhecimentos, você estará apto a dominar as instruções necessárias para criar suas tabelas e implementar a definição da estrutura do repositório de dados. Bons estudos!
Vamos Começar!
Estrutura e elementos envolvidos na criação de tabelas
O diagrama entidade-relacionamento (DER) é uma das representações mais frequentemente utilizadas para modelar dados em sistemas gerenciadores de bancos de dados. Esse modelo tem como finalidade assegurar que todos os dados presentes em um contexto específico estejam completamente e precisamente representados.
Os administradores de banco de dados (DBA, sigla em inglês para data base administrator) fazem uso desses modelos para criar uma reprodução fiel na construção física do banco de dados. O processo de tentar compreender, modelar e classificar uma realidade é uma forma de abstrair um modelo, e abstrair significa analisar, em um determinado contexto, as diversas características e propriedades relacionadas a fatos ou objetos considerados relevantes ou essenciais durante esse procedimento.
Ao observarmos um mapa-múndi, estamos diante da representação do planeta Terra, na qual identificamos alguns continentes, excluindo detalhes como fronteiras nacionais, etnias, idiomas, extensões territoriais, entre outros. Contudo, quando essa abstração é realizada com o intuito de apresentar clareza nas regras de negócio e na compreensão do propósito para o qual foi criada, obtemos um modelo conceitual, como ilustrado na Figura 1.
Nesse tipo de modelo, a compreensão torna-se simples e acessível para o usuário final, uma vez que, com ele, ficamos cientes de quais dados precisamos armazenar no banco de dados.
Já um diagrama entidade-relacionamento representa o modelo lógico de uma estrutura de banco de dados, no qual não há nenhuma especificidade do sistema gerenciador de banco de dados. O modelo lógico descreve a configuração que estará presente no banco de dados, conforme ilustrado na Figura 2.
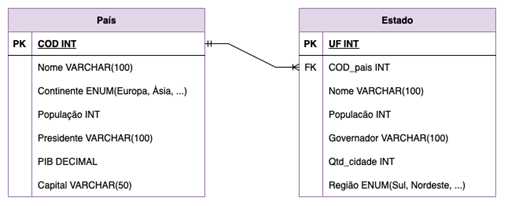
Linguagem de definição de dados (DDL): comandos para a criação de tabelas
A instrução utilizada para criar tabelas e definir sua estrutura é a CREATE TABLE. Na sua sintaxe, diversos parâmetros podem ser empregados, mas focalizaremos os principais:
CREATE TABLE [IF NOT EXISTS] nome_tabela ( Lista_campos ); |
Essa instrução cria uma tabela com o nome especificado. Se ela já existir e a cláusula IF NOT EXISTS for utilizada, isso não resultará em um erro, apenas emitirá um alerta.
Na lista de campos, a sintaxe é a seguinte:
nome_campo tipo_campo[tamanho] [NOT NULL|NULL] [DEFAULT valor] [AUTO_INCREMENT] [PRIMARY KEY] |
Nessa sintaxe, a cláusula NOT NULL|NULL indica se o campo aceita valores nulos ou não, DEFAULT especifica o valor padrão do campo e AUTO_INCREMENT identifica que o valor do campo é incrementado automaticamente quando um novo registro é inserido na tabela. Cada tabela pode ter apenas um campo AUTO_INCREMENT.
Siga em Frente...
Identificadores e tipos de dados utilizados na criação de tabelas e atributos
A seguir, são apresentados os tipos de dados que o MySQL é capaz de armazenar, classificados em três categorias: numéricos; data e hora; e texto.
- Tipos numéricos
INT [(M)] [UNSIGNED] [ZEROFILL]: indica um número inteiro no intervalo de -2147483648 a 2147483647. O intervalo sem sinal é de 0 a 4294967295. INTEGER é um sinônimo de INT.
BIGINT [(M)] [UNSIGNED] [ZEROFILL]: refere-se a um número inteiro no intervalo de -9223372036854775808 a 9223372036854775807, com o intervalo sem sinal de 0 a 18446744073709551615.
FLOAT [(M, D)] [UNSIGNED] [ZEROFILL]: representa um número de ponto flutuante de precisão simples. Os valores aceitos variam de -3,402823466E+38 a -1,175494351E-38, 0 e 1,175494351E-38 a 3,402823466E+38.
DOUBLE [(M, D)] [UNSIGNED] [ZEROFILL]: corresponde a um número de ponto flutuante de precisão dupla. Os valores admissíveis estão no intervalo de -1,7976931348623157E+308 a -2,2250738585072014E-308, 0 e 2,2250738585072014E-308 a 1,7976931348623157E+308. Além disso, DOUBLE PRECISION pode ser utilizado como sinônimo de DOUBLE.
- Tipo data e hora
DATE: o intervalo suportado é de '1000-01-01' a '9999-12-31', exibido no formato 'YYYY-MM-DD'.
DATETIME [(fsp)]: combinação de data e hora, com intervalo de '1000-01-01 00:00:00.000000' a '9999-12-31 23:59:59.999999'. Permite atribuição de valores usando strings ou números. 'fsp' opcional define a precisão dos segundos fracionários.
TIMESTAMP [(fsp)]: intervalo de '1970-01-01 00:00:01.000000' UTC a '2038-01-19 03:14:07.999999' UTC. É armazenado como segundos desde a época ('1970-01-01 00:00:00' UTC).
TIME [(fsp)]: intervalo de '-838:59:59.000000' a '838:59:59.000000'. É exibido como 'HH:MM:SS [fração]'. Permite atribuição de valores usando strings ou números.
YEAR[(4)]: ano em formato de quatro dígitos, exibido no formato YYYY, de 1901 a 2155 e 0000.
- Tipo texto
CHAR [(M)]: cadeia de comprimento fixo, preenchida à direita com espaços, com comprimento máximo de 255 caracteres.
VARCHAR (M): cadeia de comprimento variável, com comprimento máximo de 65.535 caracteres.
BINARY [(M)]: similar ao CHAR, mas armazena bytes binários em vez de caracteres não binários, com comprimento opcional M.
VARBINARY (M): similar ao VARCHAR, mas armazena bytes binários, com comprimento máximo em bytes.
TINYBLOB: coluna BLOB com comprimento máximo de 255 bytes.
TINYTEXT: coluna TEXT com comprimento máximo de 255 caracteres.
BLOB [(M)]: coluna BLOB com comprimento máximo de 65.535 bytes.
TEXT [(M)]: coluna TEXT com comprimento máximo de 65.535 caracteres.
MEDIUMBLOB: coluna BLOB com comprimento máximo de 16.777.215 bytes.
MEDIUMTEXT: coluna TEXT com comprimento máximo de 16.777.215 caracteres.
LONGBLOB: coluna BLOB com comprimento máximo de 4.294.967.295 bytes (4 GB).
LONGTEXT: coluna TEXT com comprimento máximo de 4.294.967.295 caracteres (4 GB).
ENUM ('valor1', 'valor2', ...): objeto de string com um valor escolhido em uma lista específica.
SET ('valor1', 'valor2', ...): objeto de string com zero ou mais valores escolhidos em uma lista específica.
Para ilustrar a criação de uma tabela, vamos desenvolver uma, chamada "convidado". Sua estrutura terá os campos Identificação, Nome, Sobrenome, E-mail, Data de registro e Data de nascimento. O comando para criação dessa tabela é o seguinte:
CREATE TABLE convidados ( id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(30) NOT NULL, sobrenome VARCHAR(30) NOT NULL, email VARCHAR(50), data_reg DATETIME, nascimento DATE ); |
O campo "id" tem um comprimento de até seis dígitos, e a cláusula AUTO_INCREMENT indica que esse campo será automaticamente preenchido pelo Sistema de Gerenciamento de Banco de Dados (SGBD) e incrementado a cada inserção de registro. Além disso, é a chave primária da tabela, uma vez que utiliza a cláusula PRIMARY KEY.
Os campos "nome" e "sobrenome" são do tipo VARCHAR e podem conter até 30 caracteres. Os dois primeiros campos não aceitam valores nulos, enquanto o campo "email", também do tipo VARCHAR, pode conter até 50 caracteres e aceitar valores nulos.
O campo "data_reg" é capaz de armazenar data e hora, enquanto o campo "nascimento" armazena exclusivamente uma data.
Vamos Exercitar?
Por ter assumido a responsabilidade pelo banco de dados de um aplicativo de guia turístico em desenvolvimento, você está agora encarregado de criar o repositório de dados para armazenar informações sobre o roteiro turístico. Nessa fase do projeto, o foco está na criação de tabelas para organizar as informações e estabelecer como esses dados estão inter-relacionados. As instruções para criar essas tabelas podem ser visualizadas a seguir:
CREATE TABLE IF NOT EXISTS pais ( id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(50) NOT NULL DEFAULT '', continente ENUM('Ásia', 'Europa', 'América', 'África', 'Oceania', 'Antártida') NOT NULL DEFAULT 'América', codigo CHAR(3) NOT NULL DEFAULT ‘’ );
CREATE TABLE IF NOT EXISTS estado ( id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(50) NOT NULL DEFAULT '', sigla CHAR(2) NOT NULL DEFAULT ‘’ );
CREATE TABLE IF NOT EXISTS cidade ( id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(50) NOT NULL DEFAULT '', populacao INT(11) NOT NULL DEFAULT ‘0’ );
CREATE TABLE IF NOT EXISTS ponto_tur (id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, nome VARCHAR(50) NOT NULL DEFAULT '', populacao INT(11) NOT NULL DEFAULT '0', tipo ENUM('Atrativo', 'Serviço', 'Equipamento', 'Infraestrutura', 'Instituição', 'Organização'), publicado ENUM('Não', 'Sim') NOT NULL DEFAULT ‘Não’ );
CREATE TABLE IF NOT EXISTS coordenada ( latitude FLOAT(10,6), longitude FLOAT(10,6) ); |
Ao concluir essas etapas, você terá elaborado o repositório de dados conforme as especificações do projeto.
Saiba Mais
Para entender melhor modelagem lógica e diagramas entidade-relacionamento, leia o capítulo 3 do livro Sistemas de banco de dados.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
Também sugerimos a consulta da seguinte página, que contém mais detalhes sobre as instruções de criação de tabelas com SQL:
W3SCHOOLS. SQL CREATE TABLE Statement. W3Schools, [s. l.], c2024.
A seguinte documentação do MySQL 8.3 apresenta, no capítulo 11, um complemento aos tipos de dados utilizados na criação de campos em tabelas, confira:
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
ORACLE. MySQL 8.3 Reference Manual: Chapter 11 Data Types. Disponível em: https://dev.mysql.com/doc/refman/8.3/en/data-types.html. Acesso em: 22 jan. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
W3SCHOOLS. SQL CREATE TABLE Statement. W3Schools, [s. l.], c2024. Disponível em: https://www.w3schools.com/sql/sql_create_table.asp. Acesso em: 22 jan. 2024.
Encerramento da Unidade
ESTRUTURA DE UM REPOSITÓRIO DE DADOS
Videoaula de Encerramento
A videoaula de encerramento foi preparada de maneira muito especial: nela, você explorará a aplicação prática da linguagem de consulta de dados (SQL) na programação de bancos de dados relacionais. Ainda, revisaremos juntos a criação de bancos de dados e de suas tabelas utilizando SQL, habilidades cruciais para sua jornada profissional.
Por isso, não perca esta última oportunidade de consolidar seus conhecimentos.
Aproveite esta videoaula imperdível!
Ponto de Chegada
Olá, estudante! Para desenvolver a competência desta unidade, que é conhecer a linguagem de consulta estruturada e a criação de um banco de dados, foi necessário compreender bem os conceitos abordados ao longo das aulas.
Primeiramente, exploramos os princípios essenciais que embasam a programação em bancos de dados. Nesse contexto, foi crucial assimilar a importância desse tipo de programação para o gerenciamento eficiente de informações, considerando a estrutura e a lógica da manipulação de dados.
Em seguida, você aprendeu que a linguagem de consulta de dados (SQL) é utilizada para formular consultas complexas e extrair informações específicas de um banco de dados, desenvolvendo, assim, a habilidade de realizar operações de leitura com precisão.
Por meio do SQL, abordamos o processo de criação de um banco de dados, enfatizando a importância de definir adequadamente a estrutura do banco para atender às necessidades do projeto. Com isso, você entendeu que essa etapa requer a aplicação prática dos conhecimentos adquiridos na programação, garantindo que o banco de dados seja projetado de maneira eficiente.
Por fim, você compreendeu que a criação de tabelas explora a fase específica de estruturação do banco de dados, momento em que se aprende a criar tabelas e definir seus campos. Esse conhecimento é crucial para organizar e armazenar dados de maneira coerente, atendendo às demandas específicas do sistema em desenvolvimento.
Agora, para solidificar a competência da unidade, é essencial praticar ativamente cada conceito aprendido. Após o estudo dessas aulas e refletindo sobre os tópicos trabalhados, você já é capaz de entender a importância da programação em bancos de dados, formular consultas eficientes, criar bancos de dados adequados e estruturar tabelas de maneira coerente.
Bom trabalho!
É Hora de Praticar!
Você foi contratado para desenvolver o banco de dados de uma biblioteca chamada Leituroteca, que deseja modernizar seu sistema de gerenciamento, tornando-o mais eficiente e organizado. Para isso, é necessário criar um banco de dados relacional que armazene informações cruciais sobre livros, autores, editoras e usuários.
Diante desse contexto, atente-se aos seguintes requisitos:
Livros: cada livro deve ser identificado por um ISBN (International Standard Book Number). É necessário armazenar o título do livro, o ano de publicação e o ID do autor responsável pela obra.
Autores: cada autor deve ter um ID único, um nome e o país de origem.
Editoras: elas devem ser identificadas por um ID exclusivo e um nome.
Usuários: cada usuário da biblioteca deve ter um ID único. Armazene também o nome do usuário e sua data de nascimento.
Observação: crie apenas as tabelas e os campos. Não é necessário definir os relacionamentos.
Reflita
- Qual a importância da programação em bancos de dados no contexto de gerenciamento de informações?
- Como a linguagem de consulta de dados (SQL) pode ser aplicada para extrair informações específicas de um banco de dados?
- Por que a criação adequada de um banco de dados, considerando sua estrutura, é crucial para o sucesso de um projeto de sistema?
Resolução do estudo de caso
Veja, a seguir, um exemplo de resolução da situação proposta:
CREATE DATABASE IF NOT EXISTS Biblioteca; USE Biblioteca; CREATE TABLE IF NOT EXISTS Livros ( ISBN INT PRIMARY KEY, Titulo VARCHAR(100) NOT NULL, Ano_Publicacao INT, ID_Autor INT ); CREATE TABLE IF NOT EXISTS Autores ( ID_Autor INT PRIMARY KEY, Nome VARCHAR(50) NOT NULL, Pais_Origem VARCHAR(50) ); CREATE TABLE IF NOT EXISTS Editoras ( ID_Editora INT PRIMARY KEY, Nome VARCHAR(50) NOT NULL ); CREATE TABLE IF NOT EXISTS Usuarios ( ID_Usuario INT PRIMARY KEY, Nome VARCHAR(50) NOT NULL, Data_Nascimento DATE ); |
Dê o play!
Assimile
O infográfico a seguir ilustra e identifica os cinco conjuntos de comandos da linguagem SQL. Confira!
Referências
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.