RECURSOS AVANÇADOS EM BANCOS DE DADOS
Aula 1
Controle transacional
Controle transacional
Olá, estudante! Nesta videoaula, você estudará desde os conceitos do controle transacional até o uso prático dos comandos para confirmar transações (COMMIT) e revertê-las (SAVEPOINT/ROLLBACK). Ter esse conhecimento é essencial para garantir a integridade e a consistência dos dados em sistemas de banco de dados. Por isso, prepare-se para fortalecer suas habilidades e dominar esse aspecto fundamental.
Vamos lá!
Ponto de Partida
É provável que você, estudante, já tenha enfrentado a frustrante situação de perder seus dados, seja ao excluir acidentalmente uma foto no smartphone ou ao não salvar um documento no computador enquanto o edita, o que leva a textos perdidos. Em ambientes empresariais, tais "acidentes" podem ter consequências desastrosas, por isso os sistemas gerenciadores de banco de dados (SGBD) e as linguagens de programação de banco de dados (BD) devem incluir mecanismos que assegurem a integridade das informações armazenadas nas tabelas.
Tendo isso em mente, suponha que você seja funcionário da prefeitura de um município localizado no litoral. As principais atividades econômicas da localidade estão relacionadas ao turismo devido à presença de várias ilhas próximas à costa, que atraem muitas pessoas. A área ao redor do cais é sempre movimentada, com hotéis, bares, restaurantes e agências de passeio de escuna para as ilhas.
Visando garantir a segurança dos turistas, o órgão fiscalizador solicitou à prefeitura que disponibilizasse um banco de dados para gerenciamento e controle dos passeios, das escunas e dos barqueiros. Como você trabalha na prefeitura e é responsável pelos bancos de dados utilizados na administração municipal, desenvolveu uma estrutura que está representada no código do Quadro 1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | CREATE DATABASE litoral; USE litoral;
CREATE TABLE escuna ( numero INT PRIMARY KEY, nome VARCHAR(30), capitao_cpf CHAR(11) ); CREATE TABLE destino ( id INT PRIMARY KEY AUTO_INCREMENT, nome VARCHAR(30) ); CREATE TABLE passeio ( id INT PRIMARY KEY AUTO_INCREMENT, data DATE, hora_saida TIME, hora_chegada TIME, escuna_numero INT, destino_id INT, FOREIGN KEY(escuna_numero) REFERENCES escuna(numero), FOREIGN KEY(destino_id) REFERENCES destino(id) );
INSERT INTO escuna VALUES (12345, "Black Flag","88888888899"), (12346, "Caveira","66666666677"), (12347, "Brazuca","44444444455"), (12348, "Rosa Brilhante 1","12345678900"), (12349, "Tubarão Ocean","22222222233"), (12340, "Rosa Brilhante 2","12345678900");
INSERT INTO destino VALUES (0, "Ilha Dourada"), (0, "Ilha D'areia fina"), (0, "Ilha Encantada"), (0, "Ilha dos Ventos"), (0, "Ilhinha"), (0, "Ilha Torta"), (0, "Ilha dos Sonhos"), (0, "Ilha do Sono");
INSERT INTO passeio VALUES (0,20180102,080000,140000,12345,1), (0,20180102,070000,170000,12346,8), (0,20180102,080000,140000,12340,3), (0,20180103,060000,120000,12347,2), (0,20180103,070000,130000,12348,4), (0,20180103,080000,140000,12349,6), (0,20180103,090000,150000,12345,5), (0,20180104,070000,160000,12347,1), (0,20180104,070000,170000,12345,3), (0,20180104,090000,130000,12349,7), (0,20180105,100000,180000,12340,8), (0,20180105,090000,130000,12347,7); |
Quadro 1 | Script de criação de BD e tabelas juntamente com as respectivas inserções de dados. Fonte: elaborado pelo autor.
Algum tempo depois, um funcionário da prefeitura precisou realizar uma alteração no nome de um dos destinos e, devido a uma falha operacional, todos os nomes foram modificados incorretamente, conforme evidenciado na Figura 1.
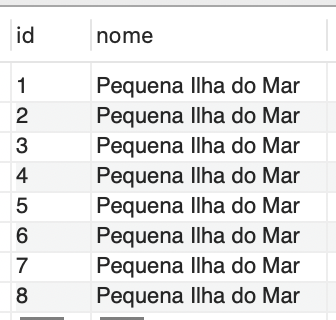
Essa falha resultou em uma interrupção do sistema por algumas horas, causando descontentamento entre os turistas e os proprietários das escunas. Como medida preventiva para evitar que o mesmo problema ocorra no futuro, foi solicitado que você execute as seguintes tarefas:
- Modificar o comando COMMIT para evitar a gravação automática das alterações.
- Criar um ponto de restauração no banco de dados.
- Realizar um teste para reproduzir o mesmo erro cometido pelo funcionário da prefeitura, que consiste em nomear todos os registros com o mesmo nome.
- Efetuar um teste de utilização do ponto de restauração criado.
- Registrar as alterações realizadas.
- Estabelecer um novo ponto de restauração, pois o anterior será eliminado após a gravação das alterações.
A implementação dessas ferramentas na situação problemática garantirá a integridade dos bancos de dados desenvolvidos por você. Portanto, nesta aula você terá a oportunidade de aprofundar seus conhecimentos em controle transacional em banco de dados, utilizando as sintaxes SAVEPOINT, COMMIT e ROLLBACK disponíveis no SQL. Não deixe de aplicar esses recursos de controle de transações em bancos de dados! Está preparado para mais esse desafio?
Vamos Começar!
Introdução ao controle transacional
Nesta aula, estudante, serão abordados os recursos da linguagem SQL, especificamente do subconjunto DTL (linguagem de transação de dados), que lidam com o controle transacional no banco de dados. Por meio das instruções COMMIT, ROLLBACK e SAVEPOINT, você compreenderá como esses recursos podem ser utilizados para garantir a integridade dos bancos de dados. Essas discussões são de extrema importância para o dia a dia do administrador de banco de dados, pois possibilitam a criação de pontos de salvamento, o retorno a um estado anterior ou o cancelamento de uma alteração.
Para ilustrar as técnicas discutidas nesta aula, utilizaremos como exemplo o script apresentado no Quadro 2.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | CREATE TABLE Enfermeiro ( Coren INT PRIMARY KEY, Nome VARCHAR(50) NOT NULL ); CREATE TABLE Paciente ( Num INT PRIMARY KEY, Nome VARCHAR(50) NOT NULL ); CREATE TABLE Remedio ( Cod INT PRIMARY KEY, Nome VARCHAR(50) NOT NULL ); CREATE TABLE Medicacao ( Id INT PRIMARY KEY AUTO_INCREMENT, Data DATE NOT NULL, Hora TIME NOT NULL, PacienteNum INT NOT NULL, RemedioCod INT NOT NULL, EnfermeiroCoren INT NOT NULL, FOREIGN KEY (PacienteNum) REFERENCES Paciente (NumInt), FOREIGN KEY (RemedioCod) REFERENCES Remedio (Cod), FOREIGN KEY (EnfermeiroCoren) REFERENCES Enfermeiro (Coren) ); |
Quadro 2 | Script de criação de BD e tabelas. Fonte: elaborado pelo autor.
Para que você entenda melhor as operações de controle transacional, os registros das tabelas foram adicionados conforme apresenta o Quadro 3.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | INSERT INTO Enfermeiro VALUES (11111, 'Enfermeiro 1'), (22222, 'Enfermeiro 2'), (33333, 'Enfermeiro 3');
INSERT INTO Paciente VALUES (1000, 'Paciente A'), (1001, 'Paciente B'), (1002, 'Paciente C'), (1003, 'Paciente D'), (1004, 'Paciente E'), (1005, 'Paciente F'), (1006, 'Paciente G'), (1007, 'Paciente H'), (1008, 'Paciente I');
INSERT INTO Remedio VALUES (100, 'Controle de pressao'), (101, 'Problemas no estomago'), (102, 'Soro'), (103, 'Calmante'), (104, 'Analgesico'), (105, 'Rins');
INSERT INTO Medicacao VALUES (0, CURRENT_DATE, '05:00:00', 1003, 104, 11111), (0, CURRENT_DATE, '08:00:00', 1001, 100, 11111), (0, CURRENT_DATE, '08:20:00', 1007, 102, 11111), (0, CURRENT_DATE, '08:30:00', 1007, 105, 11111), (0, CURRENT_DATE, '09:00:00', 1004, 104, 22222), (0, CURRENT_DATE, '09:30:00', 1005, 105, 33333), (0, CURRENT_DATE, '10:20:00', 1001, 103, 11111), (0, CURRENT_DATE, '12:00:00', 1008, 102, 22222), (0, CURRENT_DATE, '12:20:00', 1002, 105, 22222), (0, CURRENT_DATE, '13:30:00', 1001, 100, 11111), (0, CURRENT_DATE, '15:00:00', 1003, 104, 22222), (0, CURRENT_DATE, '16:00:00', 1001, 103, 11111), (0, CURRENT_DATE, '20:30:00', 1008, 100, 22222), (0, CURRENT_DATE, '21:00:00', 1002, 105, 11111), (0, CURRENT_DATE, '21:10:00', 1006, 102, 11111), (0, CURRENT_DATE, '23:00:00', 1003, 104, 33333); |
Quadro 3 | Script de inserções de dados. Fonte: elaborado pelo autor.
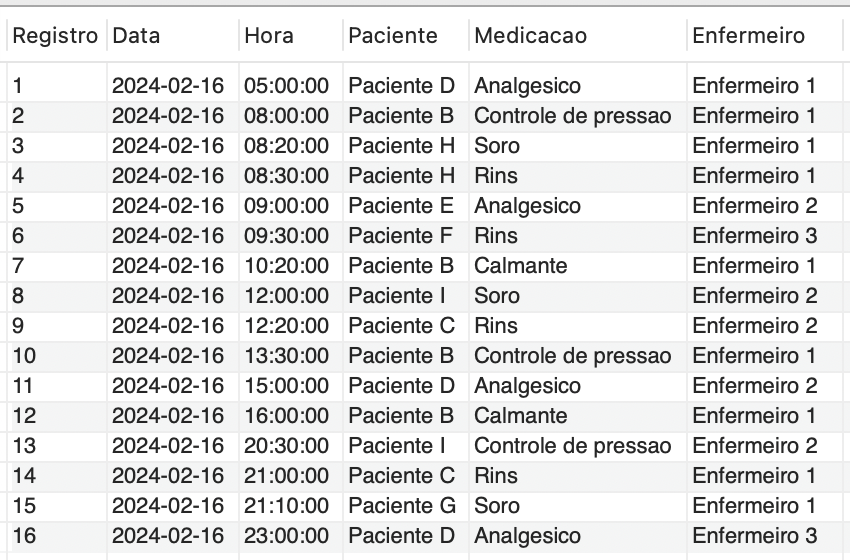
Nesse exemplo, examinaremos dados como data, hora, paciente, medicamento e enfermeiro encarregado da administração do medicamento, como representado na saída mostrada na Figura 2, resultado da seguinte consulta:
SELECT Medicacao.Id AS "Registro", Medicacao.Data, Medicacao.Hora, Paciente.Nome AS "Paciente", Remedio.Nome AS "Medicacao", Enfermeiro.Nome AS “Enfermeiro” FROM Medicacao INNER JOIN Paciente ON Medicacao.PacienteNum = Paciente.Num INNER JOIN Remedio ON Medicacao.RemedioCod = Remedio.Cod INNER JOIN Enfermeiro ON Medicacao.EnfermeiroCoren = Enfermeiro.Coren ORDER BY Medicacao.Id ASC; |
Uma transação pode ser definida como um conjunto de operações que formam uma única unidade lógica de trabalho, na qual uma instrução pode acessar, modificar ou excluir diversos dados em uma ou mais tabelas. Esse processo pode ser iniciado pela aplicação por meio de uma linguagem de programação de alto nível ou por uma linguagem de programação específica de banco de dados, como o SQL.
O controle das transações em um banco de dados relacional é fundamental para garantir a integridade dos dados contidos nas tabelas e, para isso, devem ser mantidas as seguintes propriedades:
Atomicidade: garante que todas as operações de uma transação sejam executadas corretamente; caso contrário, nenhuma das operações será concluída, evitando, assim, execuções parciais de transações.
- Consistência: assegura que, se duas transações forem executadas simultaneamente, uma não interferirá na outra.
- Isolamento: permite que várias transações ocorram simultaneamente, mas cada execução é tratada de forma isolada, sem influência das demais transações em andamento.
- Durabilidade: garante que as alterações feitas pelas transações sejam permanentemente registradas no banco de dados após a conclusão com sucesso.
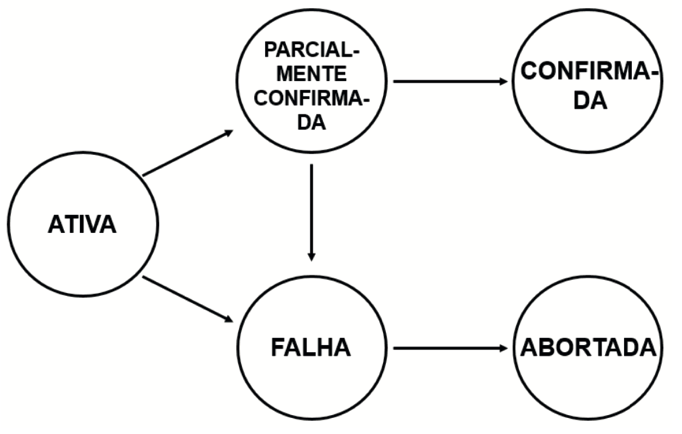
Essas propriedades, conhecidas como ACID, devem ser mantidas em diferentes estados de transações, que incluem:
- Ativa: estado inicial em que a transação está em andamento.
- Parcialmente confirmada: estado em que parte da execução não pode ser concluída devido a erros.
- Falha: estado em que a transação não pode ser executada conforme o esperado.
- Abortada: estado em que se encontra a transação quando é revertida para um estado anterior, após ter sido concluída no banco de dados.
- Confirmada: estado de conclusão da transação bem-sucedida.
O diagrama apresentado na Figura 3 ilustra as possíveis situações dos estados das transações.
Quando uma transação é concluída com sucesso, é considerada como "CONFIRMADA" (committed), o que resulta na criação de um estado que deve garantir a persistência dos dados, mesmo em situações de falha.
Para ilustrar esse conceito, podemos considerar o seguinte exemplo: às vezes, devido a falhas no Sistema de Gerenciamento de Banco de Dados (SGBD), a garantia da durabilidade pode ser comprometida, afetando a integridade do banco de dados. Imagine que, após um depósito feito por você em sua conta corrente, o sistema confirmou a transação (COMMIT), porém, em virtude de uma queda de energia, quando o sistema foi restaurado, o valor depositado não estava mais disponível em sua conta. Nesse caso, a durabilidade não foi assegurada, resultando na falta de integridade da transação.
Siga em Frente...
Comandos de controle transacional: confirmação de transações (COMMIT)
Por padrão, o MySQL vem configurado com o recurso de COMMIT automático, conhecido como AUTOCOMMIT. Isso significa que todas as alterações feitas no banco de dados são automaticamente armazenadas no disco, sem a necessidade de o usuário executar um comando específico. No entanto, é possível que as confirmações sejam controladas pelo administrador do banco de dados. Para isso, basta executar o seguinte comando no SGBD: SET AUTOCOMMIT=0;. Ao desativarmos o AUTOCOMMIT, concordamos em realizar o COMMIT manualmente.
Voltando, agora, ao exemplo do banco de dados utilizado nesta aula, realizaremos a alteração do enfermeiro responsável pelo primeiro atendimento de "Enfermeiro 1" para "Enfermeiro 2", conforme o comando a seguir, com o resultado ilustrado na Figura 4.
UPDATE Medicacao SET EnfermeiroCoren = 22222 WHERE Id = 1; SELECT * FROM Medicacao WHERE Id = 1; |

Porém, nesse caso, não será utilizado o COMMIT para registrar a alteração. Ao fazermos log out e novamente nos conectarmos ao banco para realizarmos a consulta, podemos observar, na Figura 5, que a alteração do registro não foi efetuada.

Para garantir que as alterações feitas na tabela sejam permanentemente gravadas após a confirmação da transação, é essencial executar o comando COMMIT. Esse comando simples e direto assegura a persistência dos dados modificados. Ao fazê-lo, a integridade dos dados na tabela é mantida, assegurando que a transação seja confirmada.
| COMMIT; |
Comandos de controle transacional: reversão de transações (SAVEPOINT/ROLLBACK)
Caso seja necessário reverter uma transação no banco de dados para seu estado anterior, é possível empregar o recurso de ROLLBACK, um dos comandos de controle transacional. No entanto, é importante ressaltar que as instruções relacionadas à linguagem de definição de dados (DDL), incluindo a criação e a exclusão de bancos de dados, bem como alterações, exclusões e criações de tabelas, não são passíveis de serem revertidas utilizando o ROLLBACK.
Porém, para possibilitar a reversão a um ponto específico utilizando o ROLLBACK, o SQL oferece a funcionalidade de criação de pontos de restauração por meio da sintaxe:
| SAVEPOINT [nomeDoPonto]; |
Posteriormente, para utilizar esse ponto de restauração, deve-se empregar a sintaxe:
| ROLLBACK TO SAVEPOINT [nomeDoPonto]; |
É importante notar que, para que os controles transacionais SAVEPOINT e ROLLBACK funcionem corretamente, é necessário ajustar o valor do AUTOCOMMIT para zero. Isso se deve ao fato de que a maioria dos sistemas de gerenciamento de banco de dados tem o valor padrão do AUTOCOMMIT configurado como um. Quando o AUTOCOMMIT está ativado, qualquer exclusão, alteração, inserção de dados ou criação de pontos de salvamento (SAVEPOINT) é imediatamente confirmada pelo COMMIT e as alterações são gravadas no banco de dados, tornando-se irreversíveis.
Para modificar o valor do AUTOCOMMIT, utiliza-se a sintaxe SQL:
| SET AUTOCOMMIT=0; |
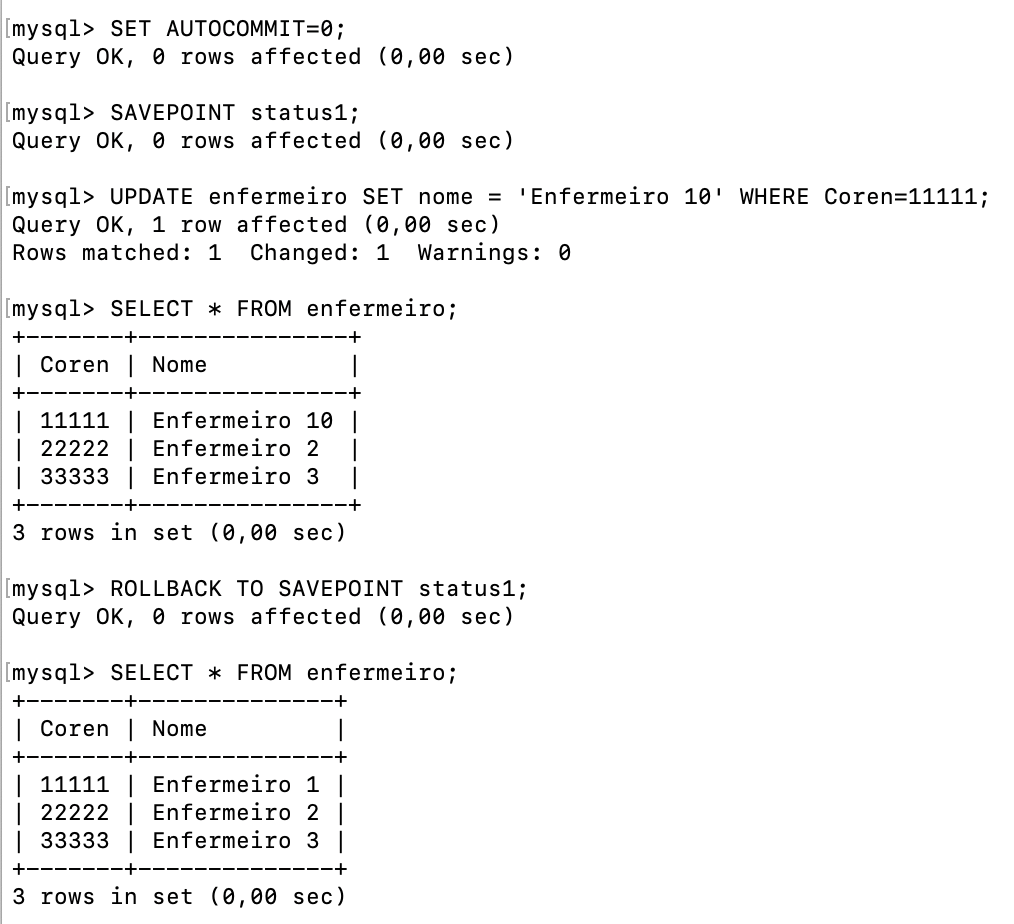
Por exemplo, considerando-se uma tabela chamada "enfermeiro" com três registros, "Enfermeiro 1", "Enfermeiro 2" e "Enfermeiro 3", podemos criar um ponto de restauração da seguinte forma:
SET AUTOCOMMIT=0; SAVEPOINT status1; |
Se, posteriormente, o nome do "Enfermeiro 1" for alterado para "Enfermeiro 10", é possível reverter essa mudança utilizando o ponto de restauração previamente criado:
| ROLLBACK to savepoint status1; |
Esses mecanismos estão ilustrados na Figura 6.
Assim, podemos assegurar que as operações transacionais sejam retrocedidas para um estado prévio.
Por fim, é importe ficar atento a isto: após a execução de um comando `ROLLBACK TO SAVEPOINT`, todos os savepoints criados posteriormente ao savepoint especificado são removidos automaticamente. Isso ocorre porque o ROLLBACK restaura o estado do banco de dados para o ponto em que o SAVEPOINT foi criado, descartando todas as alterações feitas desde então. Como resultado, todos os savepoints criados após o ponto especificado não têm mais relevância e são eliminados. Essa funcionalidade garante que o banco de dados retorne ao estado consistente mais recente antes do ponto de restauração especificado, simplificando a gestão de savepoints e mantendo a integridade do sistema de banco de dados.
Vamos Exercitar?
Como funcionário da prefeitura encarregado do desenvolvimento dos bancos de dados para o gerenciamento dos passeios de escuna em uma cidade litorânea, você ficou encarregado de resolver um incidente ocorrido quando um colaborador inadvertidamente renomeou todos os registros com o mesmo nome, resultando na impossibilidade de realizar os passeios planejados. Como medida preventiva, algumas alterações foram realizadas:
Para desativar o recurso de COMMIT automático e evitar que as alterações sejam gravadas automaticamente, é necessário empregar a seguinte sintaxe:
| SET AUTOCOMMIT=0; |
Por outro lado, para criar um ponto de restauração no banco de dados, deve-se utilizar a seguinte sintaxe:
| SAVEPOINT point1; |
Para efeitos de teste, a sintaxe adiante será empregada para reproduzir o mesmo erro cometido pelo colaborador:
UPDATE destino SET Nome = “Pequena ilha do Mar”; |
As modificações sugeridas estão refletidas na saída apresentada na Figura 7.
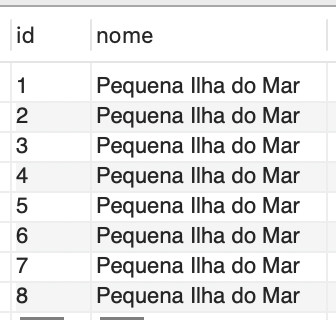
Para empregar o ponto de restauração criado e testá-lo, deve-se utilizar a seguinte sintaxe SQL:
| ROLLBACK TO SAVEPOINT point1; |
A fim de verificar se os nomes foram devidamente restaurados, os registros podem ser examinados na saída ilustrada na Figura 8.
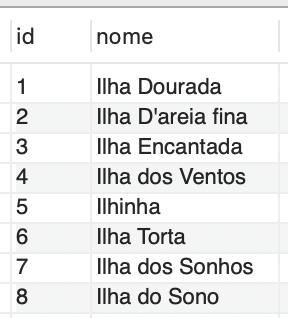
Para consolidar as alterações feitas, é necessário utilizar o comando:
| COMMIT; |
Em seguida, é aconselhável criar outro ponto de restauração, pois os existentes serão removidos após a confirmação das alterações:
| SAVEPOINT point2; |
Com essas medidas, quaisquer mudanças imprevistas (e indesejadas) não resultarão mais em erros ou perdas de dados.
Saiba Mais
Para complementar o estudo sobre transações e controle transacional, leia o capítulo 17 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 17, p. 452-470.
Recomendamos ainda uma visita ao seguinte site, que apresenta, de forma bem intuitiva, um resumo com exemplos de controle transacional.
REIS, F. dos. Como trabalhar com Transações em MySQL. Bóson Treinamentos em Ciência e Tecnologia, [s. l.], 26 maio 2021.
Aprenda, com mais detalhes, como utilizar os comandos COMMIT, SAVEPOINT e ROLLBACK no seguinte link: TUTORIALSPOINT. SQL – Transactions. Tutorialspoint, [s. l.], c2024.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
REIS, F. dos. Como trabalhar com Transações em MySQL. Bóson Treinamentos em Ciência e Tecnologia, [s. l.], 26 maio 2021. Disponível em: http://www.bosontreinamentos.com.br/mysql/como-trabalhar-com-transacoes-em-mysql/. Acesso em: 17 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
TUTORIALSPOINT. SQL – Transactions. Tutorialspoint, [s. l.], c2024. Disponível em: https://www.tutorialspoint.com/sql/sql-transactions.htm. Acesso em: 13 fev. 2024.
Aula 2
Procedimentos e Funções
Procedimentos e Funções
Olá, estudante! Hoje, mergulharemos no mundo dos Procedimentos e Funções em bancos de dados. Desde uma introdução a esses conceitos até a diferenciação entre Funções (FUNCTION) e Procedimentos Armazenados (PROCEDURE), você aprenderá como utilizar essas ferramentas poderosas para automatizar tarefas e melhorar a eficiência do seu trabalho. Prepare-se para expandir seu conhecimento e aprimorar suas habilidades práticas.
Vamos começar!
Ponto de Partida
É provável que você já tenha notado a presença de campos destinados à inserção de códigos promocionais (vouchers) em alguns sites, geralmente localizados no carrinho de compras. Ao inserir um código válido, o sistema de banco de dados realiza determinadas operações (possivelmente dentro de um procedimento armazenado) e recalcula o valor da compra. Essas operações são viáveis graças aos recursos oferecidos pela linguagem de programação SQL, que permitem a automação de algumas tarefas dentro das tabelas do banco de dados.
Com isso em mente, retomemos a situação apresentada na aula anterior: você está trabalhando na prefeitura de uma cidade litorânea, onde o setor turístico desempenha um papel importante na economia. No cargo em que ocupa, você é responsável pelo gerenciamento dos bancos de dados de um projeto relacionado ao controle dos passeios de barco para as ilhas próximas à cidade. Recentemente, visando aprimorar a segurança dos usuários durante os passeios, um ponto de venda de passagens foi instalado no píer. Para esse fim, foi necessário elaborar uma tabela para registrar as vendas, por meio do script apresentado no Quadro 1:
1 2 3 4 5 6 7 | CREATE TABLE Vendas ( Numero INT PRIMARY KEY AUTO_INCREMENT, DestinoId INT NOT NULL, Embarque DATE NOT NULL, Qtd INT NOT NULL, FOREIGN KEY (DestinoId) REFERENCES Destino(Id) ); |
Quadro 1 | Script de criação da tabela Vendas. Fonte: elaborado pelo autor.
Após isso, o campo "Valor" foi incluído na tabela "Passeio" através do seguinte comando:
| ALTER TABLE destino ADD COLUMN Valor DECIMAL(5,2); |
Em seguida, você precisou viabilizar a atualização do recém-adicionado campo “valor” na tabela Destino, utilizando o comando UPDATE, como ocorre na seguinte atualização da primeira linha:
| UPDATE destino SET Valor = 100 WHERE id = 1; |
Após feitas todas as atualizações, a tabela fica como evidenciado na Figura 1.
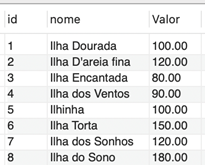
Considerando o impacto direto da baixa temporada na empregabilidade e na renda dos residentes, devido à falta de turistas, foi tomada a decisão de tornar a cidade mais atrativa, oferecendo descontos de 30% nos passeios durante esse período. O gerente de T.I. da prefeitura solicitou que você desenvolvesse uma solução no banco de dados para que o operador pudesse inserir o número da venda já realizada e receber o valor a ser pago, considerando a promoção dos passeios de escuna, que oferecem 30% de desconto na baixa temporada.
Ao resolver esse desafio no banco de dados para o caixa de passeios no píer, será necessário aplicar técnicas como FUNCTIONS e PROCEDURES, demonstrando a aplicabilidade da automação de execuções nas tabelas de um banco de dados por meio das sintaxes SQL.
Nesta aula, portanto, exploraremos as técnicas FUNCTIONS e PROCEDURES, que possibilitarão a criação de rotinas de automatização dentro do banco de dados. Todos estão contando com seu comprometimento e sua expertise técnica para uma solução inteligente no banco de dados dos passeios de escuna no píer da cidade. Pronto para mais esse desafio?
Então, mãos à obra!
Vamos Começar!
Introdução a procedimentos e funções
No fim do semestre, quando as médias finais por disciplina são divulgadas, é provável que você tenha notado que o sistema exibe diversas informações, como as médias do primeiro e do segundo bimestres, inseridas pelo professor. Nas últimas colunas, são apresentadas a média final e o status, indicando se você foi aprovado ou se precisa fazer o exame para alcançar a aprovação. A coluna responsável pelo cálculo da média final requer uma função (FUNCTION) ou até mesmo um procedimento armazenado (PROCEDURE) para realizar os cálculos necessários. Naturalmente, durante a revisão dos resultados, essas operações não ficam visíveis ao aluno.
A linguagem de programação de banco de dados SQL oferece recursos específicos que podem automatizar várias operações, permitindo que consultas, cálculos e outros processamentos dentro do banco de dados sejam realizados de forma mais eficiente em termos de tempo e uso de recursos do servidor no qual o sistema de gerenciamento de banco de dados (SGBD) está instalado.
Para ilustrar os conceitos e as aplicações abordados nesta aula, desenvolvemos um banco de dados para armazenar essas informações, conforme demonstrado no Quadro 2, que mostra as tabelas criadas para esse propósito.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | CREATE TABLE Aluno ( RA INT PRIMARY KEY NOT NULL, Nome VARCHAR(30) NOT NULL, Telefone BIGINT NOT NULL ); CREATE TABLE Disciplina ( Id INT PRIMARY KEY AUTO_INCREMENT, Nome VARCHAR(30) NOT NULL ); CREATE TABLE Notas ( AlunoRA INT NOT NULL, DisciplinaId INT NOT NULL, NotaP1 DECIMAL(3,1) NOT NULL, NotaP2 DECIMAL(3,1) NOT NULL, FOREIGN KEY (AlunoRA) REFERENCES Aluno(RA), FOREIGN KEY (DisciplinaId) REFERENCES Disciplina(Id) ); |
Quadro 2 | Script de criação das tabelas.Fonte: elaborado pelo autor.
Posteriormente, os registros para essas tabelas foram inseridos conforme o script apresentado no Quadro 3 e na representação da Figura 2.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | INSERT INTO Aluno VALUES (1234, "Aluno_A", 988776655), (1235, "Aluno_B", 997975566), (1236, "Aluno_C", 988225544), (1237, "Aluno_D", 966887744), (1238, "Aluno_E", 911223344), (1239, "Aluno_F", 922334455);
INSERT INTO Disciplina VALUES (0, "Banco de dados"), (0, "Programação estruturada"), (0, "Redes de computadores"), (0, "LFA");
INSERT INTO Notas VALUES (1234, 1, 7.0, 5.5), (1235, 1, 7.0, 5.5), (1236, 1, 6.0, 8.5), (1237, 1, 5.0, 3.5), (1238, 1, 2.5, 3.5), (1239, 1, 9.0, 5.5), (1234, 2, 6.0, 7.5), (1235, 2, 6.5, 8.5), (1236, 2, 5.0, 4.5), (1237, 2, 8.0, 7.0), (1238, 2, 7.5, 6.5), (1239, 2, 6.0, 5.5), (1234, 3, 8.5, 5.5), (1235, 3, 3.5, 7.5), (1236, 3, 7.0, 3.5), (1237, 3, 2.0, 7.0), (1238, 3, 2.5, 7.5), (1239, 3, 4.0, 9.5), (1234, 4, 5.0, 6.5), (1235, 4, 7.5, 7.5), (1236, 4, 7.0, 6.5), (1237, 4, 6.0, 7.0), (1238, 4, 4.5, 3.5), (1239, 4, 2.0, 2.5); |
Quadro 3 | Script de inserções de dados. Fonte: elaborado pelo autor.
|
|
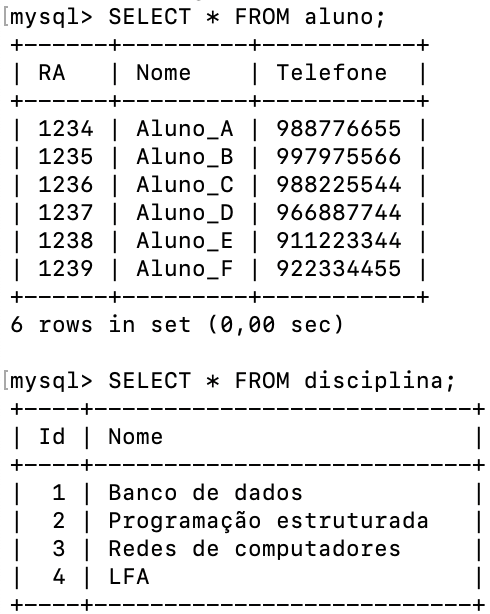
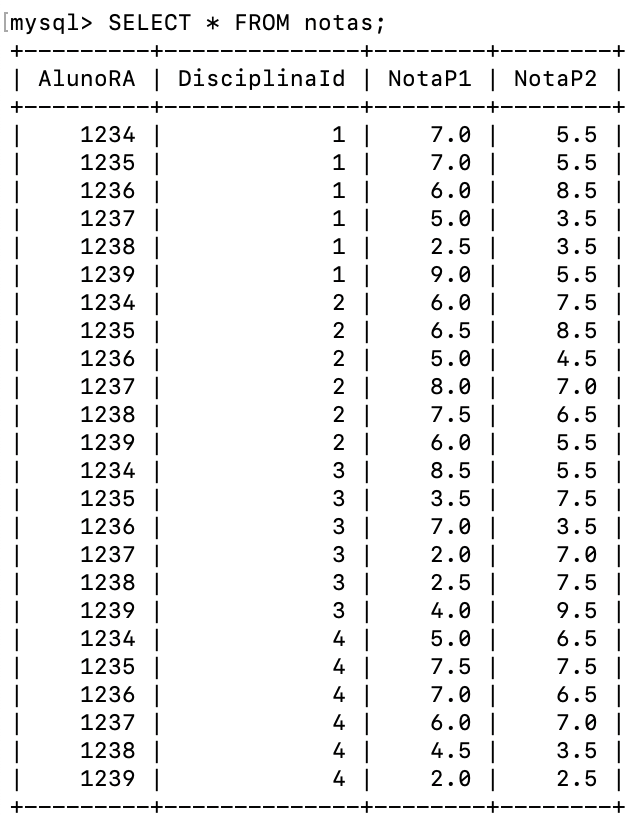
Figura 2 | Tabelas do banco de dados de exemplo. Fonte: captura de tela adaptada do MySQL elaborada pelo autor.
Siga em Frente...
Funções (FUNCTION)
As funções foram introduzidas na linguagem SQL a partir da versão SQL:2003. Essa abordagem permite a realização de operações aritméticas mais complexas, aproveitando os valores das colunas existentes em um banco de dados. O principal propósito ao empregar uma FUNCTION é produzir tabelas como resultado, conhecidas como funções de tabela.
A sintaxe para criar uma função em SQL é definida com o comando central FUNCTION e, para sua estruturação no banco de dados, utiliza-se a seguinte sintaxe SQL:
CREATE FUNCTION nome_da_funcao (x tipo, y tipo) RETURNS tipo RETURN (função); |
Onde:
- nome_da_funcao: pode ser escolhido pelo desenvolvedor, sendo uma prática comum prefixá-las com "fn", por exemplo: fn_teste.
- (x tipo, y tipo): declara duas variáveis (x e y) e seus respectivos tipos, como: (w INT, z DECIMAL(6,2)).
- RETURNS tipo: determina o tipo de dado a ser retornado após a execução da função, como: RETURNS DECIMAL(6,2).
- RETURN (função): representa a expressão em que são definidas as operações aritméticas, determinadas em (x tipo, y tipo), por exemplo: RETURN (x + 2) - (y + 1).
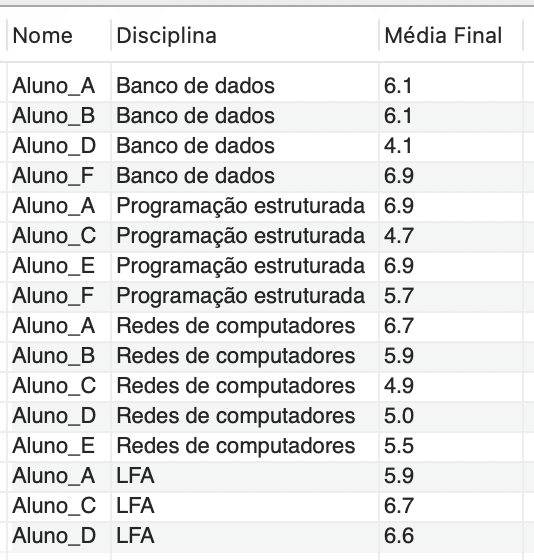
Para entender melhor essa técnica, vamos desenvolver uma função no banco de dados do exemplo para calcular a média final, onde: Média Final = (NotaP1 * 0,4) + (NotaP2 * 0,6). Para isso, a sintaxe SQL é a seguinte:
CREATE FUNCTION fn_media(x DECIMAL(3,1), y DECIMAL(3,1)) RETURNS DECIMAL(3,1) RETURN (x * 0.4) + (y * 0.6); |
A sintaxe para utilizar uma função desenvolvida em uma tabela segue o formato:
SELECT nome_da_funcao (parâmetro x, parâmetro y) FROM nome_da_tabela WHERE nome_da_coluna (condição); |
Onde (parâmetro x, parâmetro y) devem ser inseridas nas colunas utilizadas na função.
Assim, para utilizar a FUNCTION desenvolvida no exemplo (fn_media), que seleciona o nome do aluno, a disciplina e a média final dos alunos em exame (com notas entre 4,1 e 6,9 inclusive), deve-se empregar a seguinte sintaxe SQL:
SELECT Aluno.Nome, Disciplina.Nome AS "Disciplina", fn_media(NotaP1, NotaP2) AS “Média Final” FROM Notas INNER JOIN Aluno ON Notas.AlunoRA = Aluno.RA INNER JOIN Disciplina ON Notas.DisciplinaId = Disciplina.Id WHERE fn_media(NotaP1, NotaP2) >= 4.0 AND fn_media(NotaP1, NotaP2) <= 6.9; |
Essa consulta produz uma saída conforme apresenta a Figura 3.
Para visualizar todas as funções desenvolvidas, você pode utilizar a seguinte sintaxe SQL:
| SHOW FUNCTION STATUS; |
O resultado desse comando listará todas as funções criadas no sistema de gerenciamento do banco de dados, apresentando informações sobre cada uma delas. Elas podem ser visualizadas de acordo com o retorno desse comando, como mostrado na Figura 4.

O primeiro registro na lista mostra a FUNCTION desenvolvida no exemplo. Para exibir a estrutura de uma função, você pode utilizar a seguinte sintaxe SQL:
| SHOW CREATE FUNCTION nome_da_funcao; |
Já para remover uma função, você pode usar a seguinte sintaxe SQL:
| DROP FUNCTION nome_da_funcao; |
Ao criar funções no MySQL, é importante especificar se elas são DETERMINISTIC, NO DETERMINISTIC ou NO SQL para evitar erros. As funções determinísticas (DETERMINISTIC) são aquelas que sempre produzem o mesmo resultado para os mesmos parâmetros de entrada e são otimizadas pelo MySQL para consultas repetidas. Funções não determinísticas, marcadas como NO DETERMINISTIC, podem retornar resultados diferentes para os mesmos parâmetros, enquanto aquelas marcadas como NO SQL indicam que não acessam dados do banco de dados. Essas especificações permitem ao otimizador do MySQL tomar decisões mais eficientes sobre como executar consultas envolvendo essas funções, o que leva a um melhor desempenho geral do banco de dados. Isso evita alguns problemas, como:
Ambiguidade no comportamento: sem essa especificação, o MySQL pode ter dificuldade em otimizar consultas, levando a resultados inesperados ou inconsistentes.
Problemas de otimização: o MySQL usa essa informação para otimizar consultas. Funções DETERMINISTIC podem ser cacheadas para melhor desempenho, enquanto outras podem resultar em consultas mais lentas.
Dependências externas não especificadas: funções que acessam dados do banco de dados sem essa indicação podem causar problemas de concorrência e inconsistência nos resultados.
Procedimentos armazenados (PROCEDURE)
Os procedimentos armazenados foram introduzidos na versão SQL:1999 para fornecer capacidade procedural aos bancos de dados, embora não com o objetivo de substituir técnicas disponíveis em linguagens de programação como Java, C++ ou C#. Esse recurso permite armazenar procedimentos, como seleção de dados, exclusão de registros, alteração de dados, entre outras funções disponíveis na linguagem de programação SQL.
No MySQL, os procedimentos armazenados (PROCEDURE) são inseridos em uma tabela chamada ROUTINES, no banco de dados INFORMATION_SCHEMA, disponível no dicionário de dados.
A sintaxe para criar um procedimento armazenado é definida usando a palavra-chave PROCEDURE. Para estruturá-lo em um banco de dados, utiliza-se o seguinte comando SQL:
CREATE PROCEDURE nome_do_procedure (var_nome tipo) Declarações; |
Onde:
- nome_do_procedure: identifica o nome do procedimento, sendo uma prática comum prefixá-lo com "proc", por exemplo: proc_teste.
- (var_nome tipo): declara uma variável, seguindo a prática comum de prefixar o nome com "var" seguido pelo tipo da variável, como: var_teste INT.
- Declarações: podem incluir seleções de dados e outras operações.
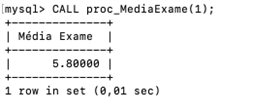
Para entender melhor essa técnica, vamos desenvolver um procedimento armazenado para calcular a média geral de todos os alunos que estão em exame nas quatro disciplinas que temos cadastradas no banco. Para isso, a seguinte sintaxe SQL foi desenvolvida:
CREATE PROCEDURE proc_MediaExame (var_DisciplinaId INT) SELECT AVG(fn_media(NotaP1, NotaP2)) AS “Média Exame” FROM Notas WHERE DisciplinaId = var_DisciplinaId AND (fn_media(NotaP1, NotaP2) >= 4.0 AND fn_media(NotaP1, NotaP2) <= 6.9); |
Nessa sintaxe:
- (var_DisciplinaId INT): cria uma variável que faz referência à coluna Id da tabela Disciplina, sendo do tipo inteiro. Essa variável é utilizada na chamada do procedimento armazenado.
- SELECT AVG(fn_media(NotaP1, NotaP2)): seleciona a média geral calculada pela função para cada aluno.
- WHERE DisciplinaId = var_DisciplinaId: impõe que o valor na coluna "DisciplinaId", na tabela Notas, deve ser igual ao valor encontrado na variável "var_DisciplinaId".
- (fn_media(NotaP1, NotaP2) >= 4.0 AND fn_media(NotaP1, NotaP2) <= 6.9): representa a condição para selecionar os alunos em exame, com notas entre 4,1 e 6,9 (inclusive).
Para utilizar um procedimento armazenado, a seguinte sintaxe SQL deve ser usada:
| CALL nome_do_procedure(var_nome); |
Observe que, na sintaxe, o trecho do comando (var_nome) refere-se ao exemplo criado, no qual é definida a variável (var_DisciplinaId INT). Ao definir-se o valor dessa variável, o banco de dados restringe a busca, comparando-o com o valor encontrado na condição, como em WHERE DisciplinaId = var_DisciplinaId. Para entender como os procedimentos são usados, consulte a Figura 5.
(a) |
(c) |
(b) |
(d) |
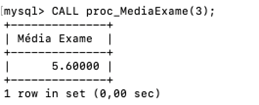
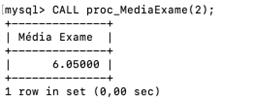
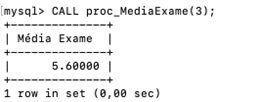
Figura 5 | Média geral dos alunos de exame em: a) banco de dados; b) programação estruturada; c) rede de computadores; e d) linguagem formal e autômatos (LFA). Fonte: captura de tela adaptada do MySQL Workbench elaborada pelo autor.
Observe que, ao executar o PROCEDURE, apenas a variável VAR_DISCIPLINAID foi modificada em todos os exemplos.
Para listar todos os procedimentos armazenados, utilize o comando SQL a seguir. Isso revelará todos os procedimentos armazenados no SGBD:
| SHOW PROCEDURE STATUS; |
Já para remover um procedimento armazenado, utilize o comando SQL:
| DROP PROCEDURE nome_do_procedure; |
Vamos Exercitar?
Para atender à demanda de implementação de uma solução no banco de dados da prefeitura de uma cidade litorânea, com o intuito de efetuar a venda dos ingressos para os passeios de escuna com um desconto de 30%, foram desenvolvidos funções e procedimentos SQL específicos. Essas medidas foram tomadas após uma reunião com o prefeito e os proprietários das escunas, que enfrentaram uma redução no número de turistas durante a baixa temporada e decidiram promover descontos para atrair mais visitantes.
Primeiramente, foi criada uma função denominada `fn_desc` utilizando a sintaxe SQL, conforme mostrado a seguir:
CREATE FUNCTION fn_desc(x DECIMAL(5,2), y INT) RETURNS DECIMAL(5,2) DETERMINISTIC RETURN ((x * y) * 0.7); |
Nessa função:
- ‘x DECIMAL(5,2)’ e ‘y INT’ representam os parâmetros que recebem o valor do passeio na tabela Destino e a quantidade de ingressos disponíveis na tabela Vendas, respectivamente.
- ‘RETURNS DECIMAL(5,2)’ especifica que a função retornará um valor com desconto de 30%, formatado como moeda.
- ‘RETURN ((x * y) * 0.7)’ calcula o valor com desconto, multiplicando o valor do destino pelo número de ingressos e aplicando um desconto de 30%.
Posteriormente, foi desenvolvido um procedimento armazenado chamado ‘proc_desc’, que utiliza a função ‘fn_desc’ para calcular o valor com desconto e exibir informações relevantes sobre a venda. O procedimento é definido da seguinte maneira:
CREATE PROCEDURE proc_desc (VAR_VendasNumero INT) SELECT (fn_desc(destino.valor, Vendas.Qtd)) AS "Valor com desconto", destino.Nome AS "Destino", vendas.Qtd AS "Passagens", vendas.Embarque FROM Vendas INNER JOIN destino ON Vendas.DestinoId = destino.Id WHERE Numero = var_VendasNumero; |
Nesse procedimento:
- ‘VAR_VendasNumero INT’ é a variável a ser passada para o procedimento armazenado através do comando ‘CALL’.
- ‘fn_desc(destino.valor, Vendas.Qtd)’ utiliza a função ‘fn_desc’, passando como parâmetros os campos "valor" da tabela Destino e "quantidade" (Qtd) da tabela Vendas.
Agora, para validar e testar o funcionamento das novas implementações, foram inseridos três registros na tabela de vendas. Eles podem ser observados na Figura 6.

Para testar a função e o procedimento desenvolvidos, podemos utilizar a seguinte sintaxe SQL:
CALL proc_desc(1); CALL proc_desc(2); CALL proc_desc(3); |
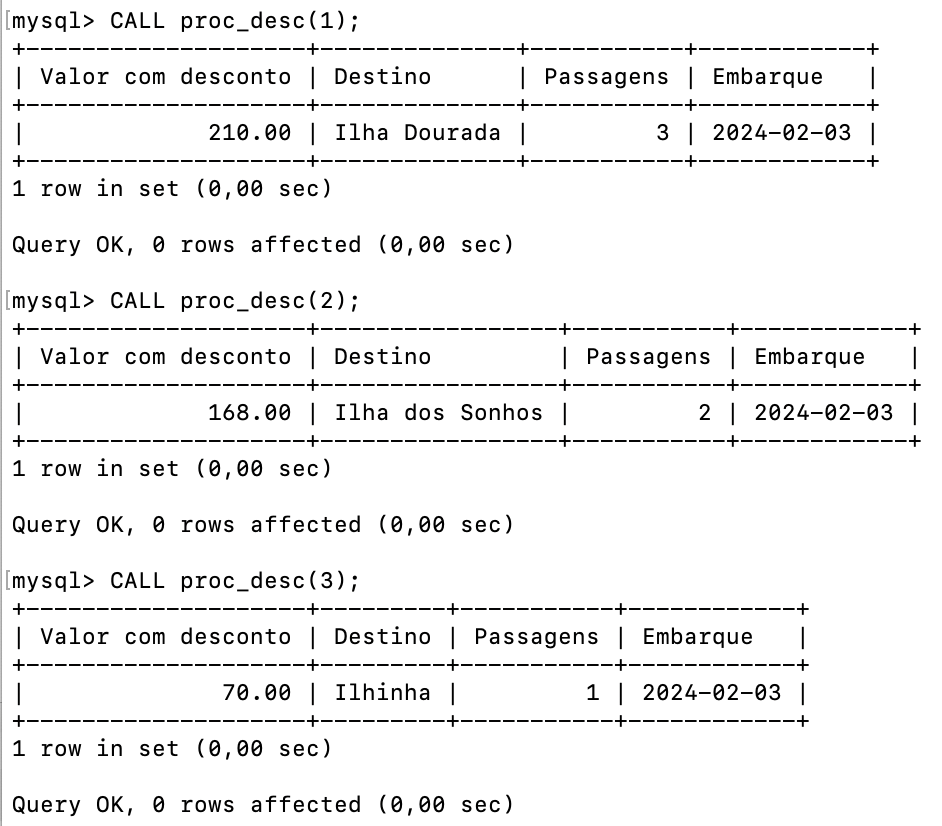
Esses comandos serão executados para os registros de vendas de números 1, 2 e 3, respectivamente, permitindo, assim, verificar o funcionamento correto da função de cálculo de desconto e do procedimento de exibição dos resultados. Os resultados gerados estão presentes na Figura 7, que demonstra o valor com desconto, o destino do passeio, a quantidade de passagens e a data de embarque para cada registro de venda correspondente.
Saiba Mais
Para complementar o estudo sobre funções e procedimentos, leia o capítulo 5 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 5, p. 108-112.
Recomendamos também uma visita ao seguinte site, que apresenta, de forma bem intuitiva, um resumo com exemplos sobre funções e procedimentos.
DEVMEDIA. Procedures e funções no MySQL. DevMedia, Rio de Janeiro, 2006.
Conheça mais sobre a otimização na chamada de funções com a marcação DETERMINISTIC, estudada na aula, a partir da consulta ao Manual de Referência do MySQL 8.0.
ORACLE. MySQL 8.0 Reference Manual. 10.2.1.20 Function Call Optimization. MySQL, [s. l.], c2024.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
DEVMEDIA. Procedures e funções no MySQL. DevMedia, Rio de Janeiro, 2006. Disponível em: https://www.devmedia.com.br/procedures-e-funcoes-no-mysql/2550. Acesso em: 18 fev. 2024.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
ORACLE. MySQL 8.0 Reference Manual. 10.2.1.20 Function Call Optimization. MySQL, [s. l.], c2024. Disponível em: https://dev.mysql.com/doc/refman/8.0/en/function-optimization.html. Acesso em: 18 fev. 2024.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
Aula 3
Controle de acesso
Controle de acesso
Olá, estudante! Nesta videoaula, adentraremos o universo do controle de acesso em sistemas de bancos de dados. Por isso, iremos desde uma introdução a esse tema até o uso prático de comandos para concessão e revogação de privilégios (GRANT e REVOKE) e a utilização de ROLES (papéis). Com isso, você compreenderá como garantir a segurança e a integridade dos dados.
Prepare-se para fortalecer suas habilidades em segurança de dados.
Vamos lá!
Ponto de Partida
Olá, estudante! Vamos imaginar uma empresa de grande porte, na qual diversos setores utilizam um ou mais sistemas distribuídos, interligados por softwares ou pela própria rede. Independentemente do número de usuários na empresa, sempre haverá diferentes níveis de acesso a esses sistemas entre eles: alguns têm privilégios de administrador, outros são usuários internos e há também os usuários finais.
Mas, afinal, qual a diferença entre esses tipos de usuários? A resposta é simples: seus privilégios de acesso. Por exemplo, se um usuário tem privilégios de administrador, ele pode realizar ações como limpar tabelas ou acessar informações sensíveis, o que poderia ser problemático para os administradores de bancos de dados.
Tendo esse contexto em mente, imagine que você trabalha como administrador de banco de dados (DBA) em uma empresa de desenvolvimento de software e agora tem a importante tarefa de determinar os níveis de acesso dos desenvolvedores ao banco de dados, decisão muito importante para garantir a segurança e a integridade dos dados da empresa.
Sua tarefa consiste, então, na elaboração de um relatório detalhado sobre como definir os privilégios de acesso de cada desenvolvedor ao banco de dados. Isso envolve não apenas decidir se os desenvolvedores terão acesso somente para visualização de informações ou se poderão manipular dados, mas envolve também considerar se é mais eficiente conceder esses privilégios individualmente para cada desenvolvedor ou agrupá-los em categorias. Inicialmente, a proposta é dividir a equipe de desenvolvimento em dois grupos distintos: o Grupo A, composto por desenvolvedores responsáveis apenas por consultas e relatórios, e o Grupo B, encarregado do desenvolvimento de aplicativos.
A questão da segurança é primordial, pois a concessão de privilégios inadequados pode resultar em vazamento de informações confidenciais ou em modificações indesejadas no banco de dados. Portanto, analise cuidadosamente o perfil de cada desenvolvedor e atribua privilégios de acesso de forma criteriosa, garantindo que apenas as pessoas autorizadas tenham acesso aos dados relevantes para suas funções.
Desenvolva suas habilidades nesta área e esteja preparado para tomar decisões fundamentadas e que contribuam para o bom funcionamento do banco de dados e para o sucesso da empresa como um todo. Aproveite a leitura e absorva o conhecimento oferecido nesta aula.
Bons estudos!
Vamos Começar!
Introdução ao controle de acesso
Um banco de dados de uma empresa contém uma ampla gama de informações e, tipicamente, atende a diversos grupos de usuários, dentre os quais a maioria necessita apenas de acesso a uma parcela específica do banco de dados para desempenhar suas funções. Diante disso, além de ser desnecessário, conceder acesso irrestrito a todos os dados pode ser problemático, por isso um Sistema de Gerenciamento de Banco de Dados (SGBD) deve oferecer mecanismos para controlar o acesso aos dados. Sendo assim, para compreender melhor os grupos de usuários, podemos classificá-los em duas categorias fundamentais:
- Administradores de banco de dados: são os profissionais que interagem diretamente com o banco de dados, sendo responsáveis por sua segurança e organização.
- Usuários de banco de dados: incluem aqueles que interagem tanto direta quanto indiretamente com o banco de dados, conforme os privilégios concedidos pelos administradores.
Há dois tipos de privilégios no contexto de controle de acesso: o privilégio por controle de acesso discricionário, que envolve a concessão e a revogação de privilégios, e o por controle de acesso obrigatório, baseado em papéis para segurança multinível. Examinemos, agora, esses dois tipos de privilégios:
- Privilégio por controle de acesso discricionário (DAC): permite que o administrador do banco de dados (DBA) e os usuários selecionados concedam e revoguem privilégios. Os privilégios discricionários são essencialmente associados a contas de usuários ou a grupos de usuários. Informalmente, existem dois níveis de atribuição de privilégios para o uso do sistema de banco de dados: o primeiro é o nível de conta, que se refere às capacidades concedidas diretamente à própria conta e que pode incluir privilégios como Create Table ou Create Schema para criar relações básicas, Create Alter para modificar o esquema, Drop para excluir relações ou visões, Modify para manipular tabelas e Select para recuperar e visualizar informações do banco de dados. O segundo é o nível de relação (tabela), que se aplica a relações-base ou visões. Em SQL, diversos tipos de privilégios podem ser atribuídos individualmente para cada relação R, incluindo o privilégio Select para recuperação, Modify para modificação e References para referenciar a relação em restrições de integridade.
- Privilégio por controle de acesso obrigatório baseado em papéis para segurança multinível (MAC): essa abordagem é caracterizada por uma estrutura de tudo ou nada, na qual um usuário detém um privilégio ou não. Esse método, conhecido como controle de acesso obrigatório, geralmente é complementar aos mecanismos de controle de acesso discricionário. É importante observar que atualmente a maioria dos Sistemas de Gerenciamento de Banco de Dados (SGBDs) comerciais oferece apenas mecanismos para controle de acesso discricionário. Esse tipo de privilégio é uma técnica consolidada para gerenciar efetivamente a segurança em sistemas de larga escala, abrangendo toda a organização. Sua premissa fundamental reside na associação de permissões a papéis específicos, aos quais os usuários são designados conforme apropriado. Esses papéis podem ser criados utilizando os comandos "Create Role" e "Destroy Role". Em seguida, os comandos "Grant" e "Revoke" são empregados para conceder ou retirar privilégios dos papéis. Essa abordagem representa uma alternativa robusta aos controles de acesso convencionais tanto discricionários quanto obrigatórios, garantindo que apenas usuários autorizados tenham acesso a determinados dados ou recursos.
Siga em Frente...
Comandos de controle de acesso para concessão e revogação de privilégios (GRANT e REVOKE)
Os privilégios desempenham um papel fundamental na proteção e na integridade dos dados, ao mesmo tempo em que estabelecem a responsabilidade individual de cada usuário sobre seus dados específicos. Nesse contexto, utilizamos os comandos da linguagem de controle de dados (DCL) do SQL: GRANT e REVOKE.
Quando uma tabela ou vista é criada, o comando GRANT é utilizado. Nesse processo, o nome do usuário que a criou é automaticamente associado ao nome da tabela ou vista. Por exemplo, se o usuário Pedro criou a tabela Cliente, internamente ela será reconhecida como Pedro.Cliente. O criador da tabela ou da vista tem privilégios completos sobre ela e pode atribuir diferentes níveis de acesso a outros usuários através do comando GRANT, como é demonstrado na sintaxe a seguir:
GRANT [privilégio] ON [objeto] TO {usuário | papel | PUBLIC} [WITH {ADMIN | GRANT} OPTION]; |
Onde:
- GRANT [ALL | privilégio]: é o comando básico para conceder privilégios em um sistema. O pode ser usado com o ALL, que concederá todos os privilégios disponíveis.
- ON [objeto]: indica o objeto ao qual os privilégios serão aplicados, ou seja, ao banco de dados, à tabela ou a outro objeto do banco de dados ao qual os privilégios estão sendo concedidos.
- TO {usuário | papel | PUBLIC}: especifica para quem os privilégios estão sendo concedidos. Pode ser um usuário específico, um papel (também conhecido como função) ou todos os usuários do banco de dados, designados pela palavra-chave "PUBLIC".
- [WITH {ADMIN | GRANT} OPTION]: esta parte é opcional e especifica se o usuário que está recebendo os privilégios terá permissão para conceder esses mesmos privilégios a outros usuários. Se for utilizado "WITH ADMIN OPTION", o usuário terá permissão para conceder os mesmos privilégios. Se for especificado "WITH GRANT OPTION", o usuário só poderá conceder os privilégios se já tiver recebido permissão para fazê-lo anteriormente.
Suponha que você tenha um banco de dados chamado "biblioteca" e deseje conceder permissões de leitura para um usuário chamado "leitor" em todas as tabelas desse banco de dados. Você pode fazer isso usando o seguinte comando:
| GRANT SELECT ON biblioteca.* TO 'leitor'@'localhost'; |
Esse comando concede permissão de leitura (SELECT) para o usuário "leitor" em todas as tabelas do banco de dados "biblioteca" quando acessado do localhost. Agora, imagine que você queira conceder permissões de leitura e escrita em uma tabela específica chamada "livros" para o mesmo usuário "leitor". Você pode fazer isso com o seguinte comando:
| GRANT SELECT, INSERT, UPDATE, DELETE ON biblioteca.livros TO 'leitor'@'localhost'; |
Além disso, é possível conceder permissões para todos os bancos de dados no servidor MySQL. Por exemplo, se você quiser conceder permissões de criação de banco de dados para um usuário chamado "admin", você pode usar o seguinte comando:
| GRANT CREATE ON *.* TO 'admin'@'localhost'; |
Ele concede permissão de criação de banco de dados (CREATE) para o usuário "admin" em todos os bancos de dados no servidor MySQL quando acessado do localhost.
O comando REVOKE, por sua vez, é usado para remover ou revogar privilégios anteriormente concedidos a usuários ou grupos de usuários em um banco de dados, tabela ou coluna específica. Isso é útil quando você precisa restringir ou alterar os privilégios de acesso de determinados usuários. A sintaxe é a seguinte:
REVOKE [privilégio] ON [ OBJETO ] [ esquema ].objeto [( coluna [ ,...n ])] FROM [privilegiado] [ ,...n ] |
Onde:
- REVOKE [privilégio]: indica que estamos revogando privilégios. E [privilégio] especifica o privilégio ou lista de privilégios que estão sendo revogados. Eles podem incluir SELECT, INSERT, UPDATE, DELETE, entre outros. Se nenhum privilégio for especificado, todos serão revogados.
- ON [ OBJETO ] [ esquema ].objeto [( coluna [ ,...n ])]: especifica o objeto em relação ao qual os privilégios estão sendo revogados. Pode ser uma tabela, um banco de dados ou mesmo uma coluna específica dentro de uma tabela. Se o objeto for uma tabela, você pode especificar as colunas entre parênteses. O esquema é opcional e permite especificar o banco de dados ao qual o objeto pertence. Se o esquema não for especificado, o banco de dados atual (selecionado) será usado.
- FROM [privilegiado] [ ,...n ]: especifica o usuário ou os usuários dos quais os privilégios estão sendo revogados. Você pode listar vários usuários separados por vírgula. Se o privilégio estiver sendo revogado de um grupo de usuários, você também pode listar o grupo aqui.
- Suponha que você tenha concedido o privilégio SELECT à um usuário chamado 'leitor’ na tabela 'livros’ do banco de dados 'biblioteca’. Para revogar esse privilégio, você pode usar o seguinte comando:
| REVOKE SELECT ON biblioteca.livros FROM 'leitor'@'localhost'; |
Depois de executar esse comando, 'leitor’ não será capaz de executar consultas SELECT na tabela 'livros’.
Por fim, é importante destacar que, após conceder ou revogar privilégios usando o comando GRANT ou REVOKE no MySQL, geralmente é uma prática recomendada usar o seguinte comando:
| FLUSH PRIVILEGES; |
Ele é usado para garantir que as alterações entrem em vigor imediatamente, sem a necessidade de reiniciar o servidor MySQL. O comando FLUSH PRIVILEGES força o servidor MySQL a recarregar os arquivos de permissões e a atualizar as configurações em tempo de execução.
Utilização de ROLES (papéis)
No MySQL, um papel (ou ROLE, em inglês) é uma entidade que representa um conjunto de privilégios que pode ser atribuído a usuários ou a outros papéis. Isso simplifica a administração de privilégios, pois, em vez de conceder ou revogar privilégios para cada usuário individualmente, pode-se atribuir um papel a eles e gerenciar os privilégios desse papel.
A sintaxe para criar um papel e atribuir privilégios a ele no MySQL é a seguinte:
CREATE ROLE 'roleteste'@'localhost'; GRANT SELECT ON teste.tab1 TO 'roleteste'@'localhost'; GRANT 'roleteste'@'localhost' TO 'userteste'@'localhost'; |
Onde:
- CREATE ROLE 'roleteste'@'localhost': cria um papel chamado 'roleteste', que está associado ao host 'localhost'. Aqui, 'roleteste' é o nome do papel que estamos criando e '@'localhost' especifica o host ao qual o papel está associado.
- GRANT SELECT ON teste.tab1 TO 'roleteste'@'localhost': concede o privilégio SELECT na tabela 'tab1' do banco de dados 'teste' ao papel 'roleteste' no host 'localhost'. Isso significa que os usuários que têm o papel 'roleteste' poderão executar consultas SELECT na tabela 'tab1'.
- GRANT 'roleteste'@'localhost' TO 'userteste'@'localhost': atribui o papel 'roleteste' ao usuário 'userteste' no host 'localhost'. Dessa forma, o usuário 'userteste' herda todos os privilégios associados ao papel 'roleteste'. Isso é útil quando queremos conceder um conjunto específico de privilégios a vários usuários, pois podemos atribuir o papel aos usuários em vez de conceder os privilégios individualmente.
Usar papéis no MySQL simplifica a administração de privilégios, tornando-a mais organizada e fácil de gerenciar, especialmente em ambientes com muitos usuários e complexidade de permissões. Eles ajudam a garantir a consistência nos privilégios concedidos aos usuários e facilitam a manutenção do sistema.
Além das funcionalidades básicas de criação e atribuição de privilégios, os papéis (ROLES) oferecem recursos adicionais que contribuem para uma gestão de permissões mais flexível e eficiente. Alguns exemplos são:
Hierarquia de papéis: no MySQL, é possível criar uma hierarquia de papéis, na qual um papel pode herdar os privilégios de outro. Isso permite uma organização mais granular e uma gestão mais eficaz das permissões. Por exemplo, um papel de nível mais alto pode conter privilégios gerais compartilhados por vários papéis de nível inferior.
Revogação de privilégios em cascata: quando um papel é revogado de um usuário, os privilégios concedidos por esse papel também são revogados automaticamente. Isso simplifica o processo de gestão de permissões, garantindo que todas as concessões associadas a um papel sejam retiradas quando ele é removido de um usuário.
Definição de padrões de privilégios: os papéis podem ser utilizados para definir padrões de privilégios para diferentes grupos de usuários. Por exemplo, é possível criar o papel "leitura", que concede apenas privilégios de leitura em determinadas tabelas, e o papel "escrita", que concede privilégios de escrita nessas mesmas tabelas. Em seguida, pode-se atribuir esses papéis aos usuários conforme necessário, facilitando a gestão de permissões de acordo com as funções dos usuários.
Administração centralizada: com papéis, a administração de permissões pode ser centralizada em um conjunto específico de papéis, o que facilita a manutenção e garante a consistência nas permissões concedidas aos usuários. Isso é especialmente útil em ambientes empresariais com muitos usuários e sistemas complexos.
Segurança aprimorada: o uso de papéis pode contribuir para a segurança do sistema, uma vez que reduz o risco de concessões excessivas ou desnecessárias de privilégios. Ao definir papéis com permissões bem definidas e atribuí-los aos usuários com base em suas funções, é possível garantir que cada usuário tenha apenas os privilégios necessários para realizar suas tarefas, minimizando, assim, os pontos de vulnerabilidade no sistema.
Vamos Exercitar?
Na situação proposta no início da aula, o objetivo de sua tarefa como DBA era fornecer um relatório claro sobre como determinar os privilégios necessários para os desenvolvedores de sua empresa, visando preservar a integridade do banco de dados. Inicialmente, foi proposto dividir a equipe de desenvolvimento em dois grupos distintos: o Grupo A, composto por desenvolvedores responsáveis apenas por consultas e relatórios, e o Grupo B, encarregado do desenvolvimento de aplicativos.
Diante disso, primeiramente, crie os usuários e os papéis necessários. Serão cinco usuários, criados a partir dos seguintes comandos:
CREATE USER 'usuario1'@'localhost' IDENTIFIED BY 'senha1'; CREATE USER 'usuario2'@'localhost' IDENTIFIED BY 'senha2'; CREATE USER 'usuario3'@'localhost' IDENTIFIED BY 'senha3'; CREATE USER 'usuario4'@'localhost' IDENTIFIED BY 'senha4'; CREATE USER 'usuario5'@'localhost' IDENTIFIED BY 'senha5'; |
Em seguida, é preciso criar as ROLES, sendo o papel ‘grupo_a_role’ para os desenvolvedores de consultas e relatórios e o papel ‘grupo_b_role’ para os desenvolvedores de aplicativos.
CREATE ROLE grupo_a_role; CREATE ROLE grupo_b_role; |
O próximo passo é associar os usuários às suas respectivas roles:
GRANT grupo_a_role TO 'usuario1'@'localhost', 'usuario2'@'localhost', GRANT grupo_b_role TO 'usuario3'@'localhost', 'usuario4'@'localhost', 'usuario5'@'localhost'; |
Agora, é preciso conceder permissões específicas para cada role: para o Grupo A, que não necessita de permissões para realizar alterações nos registros, apenas visualizá-los, sugerimos o seguinte comando como exemplo para a tabela ‘Produto’, no banco de dados ‘dbase’:
| GRANT SELECT ON dbase.Produto TO grupo_a_role; |
Nesse contexto, optamos por não incluir a cláusula "WITH GRANT OPTION", uma vez que essa conta não precisa de autorização para conceder acessos adicionais.
Já para o Grupo B, que requer privilégios mais abrangentes do que o Grupo A, propomos o seguinte comando de exemplo, ainda utilizando a tabela "Produto":
| GRANT SELECT, INSERT, DELETE, UPDATE ON dbase.Produto TO grupo_b_role; |
Alternativamente, também seria viável utilizar o comando "ALL", pois necessitamos de todos os privilégios:
| GRANT ALL ON dbase.Produto TO grupo_b_role; |
Saiba Mais
Para complementar o estudo sobre funções e procedimentos, faça a leitura do capítulo 4.7 do livro Sistema de banco de dados.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book. cap. 4.7, p. 90-94.
Para saber a extensão do que é possível fazer em termos de atribuição de privilégio, recomendamos que você estude a fundo os próprios comandos do SQL passíveis de privilégios.
DUARTE, E. Gerenciamento de usuários e controle de acessos do MySQL. DevMedia, Rio de Janeiro, 2006.
Aprenda como criar um usuário no MySQL Server para posteriormente conceder/revogar privilégios, no seguinte site:
SVERDLOV, E.; PIMENTA, F. Como criar um novo usuário e atribuir permissões no MySQL. Digital Ocean, [s. l.], 3 dez. 2014.
Referências Bibliográficas
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
DUARTE, E. Gerenciamento de usuários e controle de acessos do MySQL. DevMedia, Rio de Janeiro, 2006. Disponível em: https://www.devmedia.com.br/gerenciamento-de-usuarios-e-controle-de-acessos-do-mysql/1898. Acesso em: 18 fev. 2024.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.
SVERDLOV, E.; PIMENTA, F. Como criar um novo usuário e atribuir permissões no MySQL. Digital Ocean, [s. l.], 3 dez. 2014. Disponível em: https://www.digitalocean.com/community/tutorials/como-criar-um-novo-usuario-e-conceder-permissoes-no-mysql-pt. Acesso em: 18 fev. 2024.
Aula 4
Backup e restauração
Backup e restauração
Olá, estudante! Na videoaula de hoje, você estudará temas importantes para sua prática profissional no universo da administração de bancos de dados MySQL. Por isso, abordaremos estratégias fundamentais, como backup e restauração no MySQL, além de discutir a importância da redundância de dados e a utilização de backups na nuvemm
Esse conhecimento é fundamental para garantir a segurança e disponibilidade dos dados em sua carreira. Prepare-se para aprofundar seus conhecimentos nesta área crucial.
Vamos começar juntos essa jornada de aprendizado!
Ponto de Partida
Nesta aula, você, estudante, será introduzido aos conceitos de backup e restore. Essa etapa lhe permitirá compreender o funcionamento e a importância de cada um deles.
A perda de informações de um banco de dados é uma experiência angustiante, especialmente se elas forem confidenciais. São anos de dados e memórias perdidos devido a falhas diversas, sem chance de recuperação. Para prevenir tal incidente, a solução é simples: realizar backups dos dados. Um backup é uma cópia de segurança de todas as informações virtuais, feita para evitar a perda de arquivos importantes ou permitir a recuperação de arquivos modificados sem autorização.
Após compreender o funcionamento de backups e restores, você será instruído sobre a replicação de dados, desde seu conceito básico até sua aplicação adequada. Para que você se aproprie plenamente desses conhecimentos, vamos a uma situação-problema:
Sr. Joaquim, um dos principais gestores da empresa em que você trabalha, está preocupado com a segurança das informações durante o período de feriado prolongado. Embora tenha tomado medidas como a separação das áreas do sistema, ele ainda enfrenta o risco de queda de desempenho devido ao aumento do tráfego em uma das instâncias. Para evitar interrupções significativas, o Sr. Joaquim disponibilizou outro servidor com um link de internet adicional. No entanto, suas dúvidas persistem quanto ao procedimento correto a ser adotado para garantir a continuidade operacional e evitar a indisponibilidade prolongada de uma das instâncias.
Agora, cabe a você utilizar seus conhecimentos e suas habilidades para apresentar uma solução viável por meio da ferramenta Workbench do MySQL. Sua tarefa é, então, encontrar uma maneira eficaz de otimizar a infraestrutura existente, garantindo a distribuição equilibrada do tráfego e a disponibilidade contínua das instâncias, mesmo diante de picos de acesso.
Esse desafio requer criatividade, pensamento analítico e capacidade de resolver problemas de forma proativa. Com dedicação nos estudos e nas aulas, você será capaz de criar e restaurar backups de banco de dados, além de implementar a replicação de dados, aumentando, assim, a segurança da estrutura.
Vamos em frente!
Vamos Começar!
Backup e restauração no MySQL
Para garantir a segurança dos dados, é preciso armazenar as informações em locais adicionais, como em outra unidade de disco, em um servidor alternativo, em um dispositivo de armazenamento externo, ou em backups na nuvem. Isso garante a preservação, a capacidade de recuperação das informações, ou até mesmo do banco de dados completo. Diante disso, os administradores devem aproveitar os recursos oferecidos pelo próprio servidor de banco de dados ou por outros meios para criar cópias de segurança. Uma abordagem comum é realizar backups periódicos, para os quais muitos sistemas operacionais e servidores oferecem ferramentas dedicadas. Alternativamente, podem ser utilizados aplicativos utilitários disponíveis no mercado, alguns dos quais são gratuitos. A maioria dos Sistemas de Gerenciamento de Banco de Dados (SGBDs) relacionais padrão SQL fornecem utilitários para cópia e restauração (backup/restore) das bases de dados.
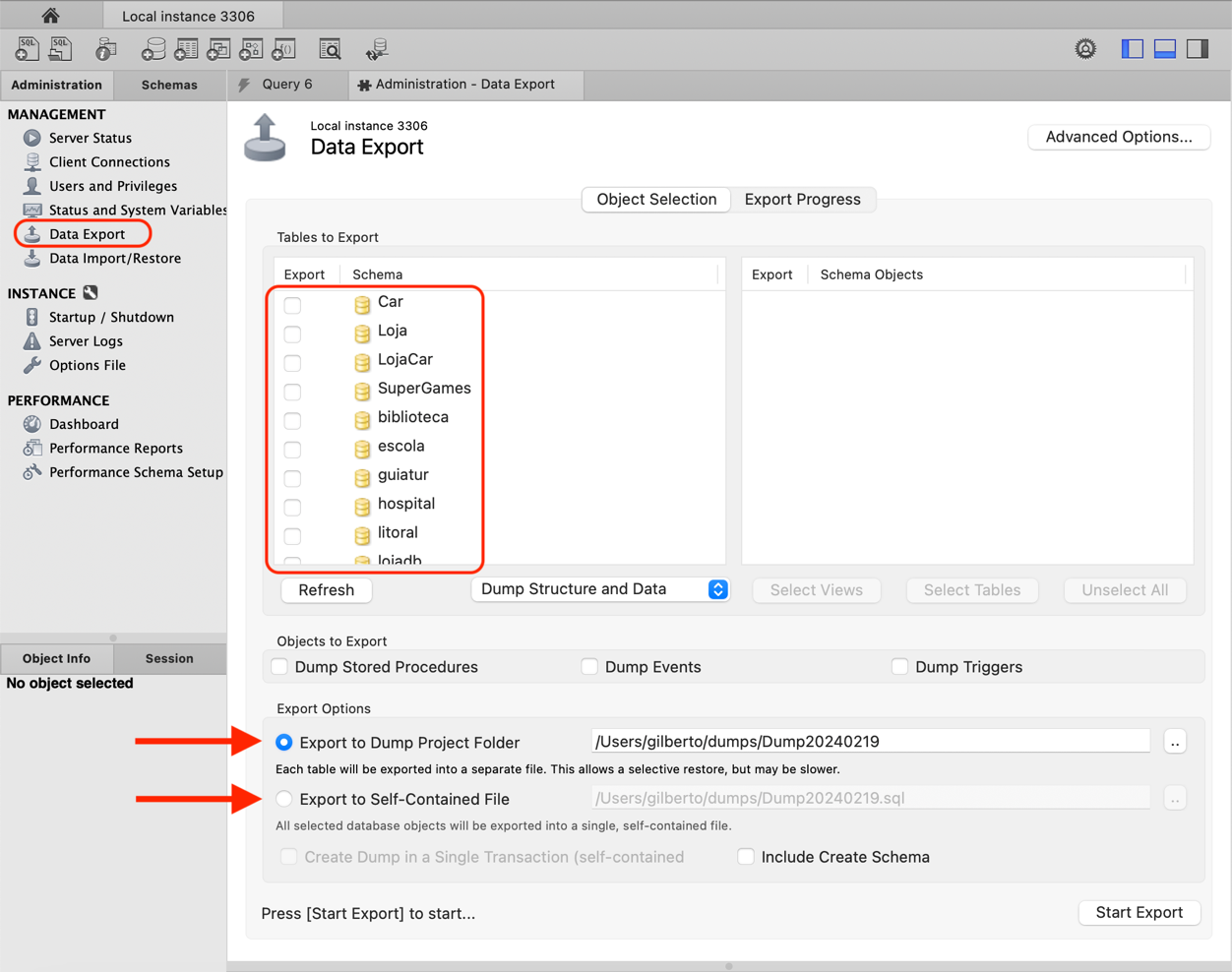
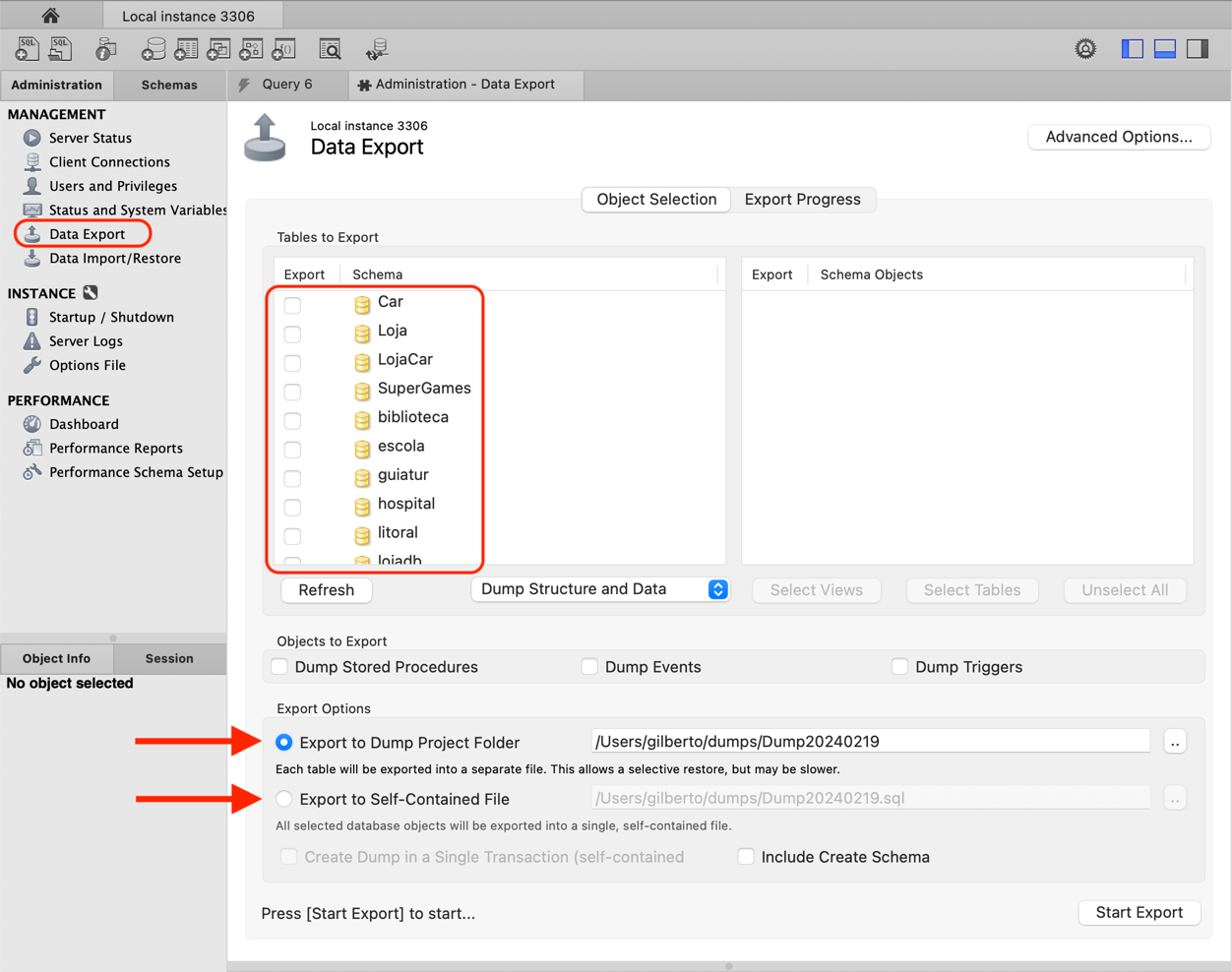
Uma ferramenta amplamente utilizada para realizar backups em bancos de dados MySQL é o Workbench, um gerenciador de banco de dados incluído na instalação do MySQL. Com o Workbench, é possível realizar consultas, modificações de dados, inclusão de usuários e conceder permissões, além de gerenciar um ou mais bancos de dados. Para efetuar um backup usando o Workbench, é necessário conectar-se à base de dados desejada e acessar o menu à esquerda, selecionando a opção "Data Export". Dentro dessa opção, existem duas alternativas:
- Export to Dump Project Folder: essa opção gera o backup no diretório especificado. Para incluir o conteúdo de cada tabela na base de dados, é necessário desmarcar a opção "Skip table data (no-data)". Essa funcionalidade é ideal para criar um banco de dados sem informações, utilizando apenas a estrutura existente.
- Export to Self-Contained File: essa opção cria um arquivo único .sql contendo todo o código da base de dados. Para incluir as informações da base de dados, a opção "Skip table data (no-data)" deve ser desmarcada, caso contrário, apenas a estrutura das tabelas será salva.
Após escolher a opção desejada, basta selecionar "Start Export" para iniciar a construção do backup e salvá-lo no diretório selecionado. A Figura 1 apresenta a tela do Workbench com essas ações.
Embora não seja uma norma absoluta a ser estritamente seguida, é recomendável realizar operações de backup e restore quando o banco de dados não está sendo acessado por usuários. Além disso, é importante entender que não se deve confiar exclusivamente em uma única pessoa para executar a cópia de segurança, mas é prudente utilizar métodos de cópia automática sempre que possível. Ter múltiplas cópias, como uma imagem atual do banco de dados e duas anteriores, é uma prática que pode facilitar a recuperação de dados em caso de necessidade.
Outra alternativa, embora um pouco mais custosa, porém mais segura e independente de terceiros, é o uso de discos rígidos espelhados, como a configuração RAID (Redundant Array of Independent Disks – Conjunto Redundante de Discos Independentes), que será detalhada a seguir. Em ambientes cliente/servidor que executam aplicações críticas, é possível encontrar máquinas inteiras espelhadas. Essa arquitetura, tanto em hardware quanto em software, permite que, se uma máquina falhar, a outra entre em operação automaticamente, sem que os usuários percebam qualquer interrupção no serviço.
Siga em Frente...
Redundância de dados
RAID é um sistema que consiste na união de múltiplos discos rígidos que operam simultaneamente ou de forma paralela, com o propósito de mitigar os riscos de perda de dados e melhorar o desempenho de acesso às informações. Os discos podem operar de maneira independente ou coordenada, distribuindo os dados entre si. A implementação do RAID pode ser feita tanto por meio de softwares quanto de hardware, oferecendo diversos níveis de configuração. A seguir estão alguns exemplos de configurações RAID, nos quais as letras representam os discos.
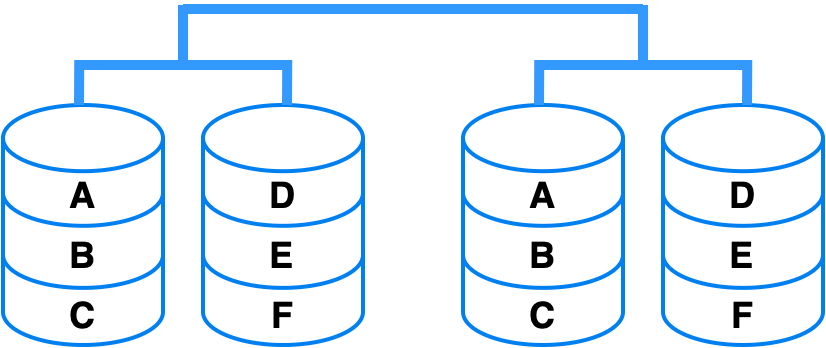
O RAID nível 0 + 1 requer, no mínimo, quatro discos para ser implementado e apresenta a duplicação de cada par de discos, sendo os pares configurados como RAID nível 0 (Figura 2). Sua vantagem reside na garantia da segurança dos dados, enquanto proporciona ganhos de desempenho. Porém, sua desvantagem é a necessidade de mais discos, resultando em custos adicionais.
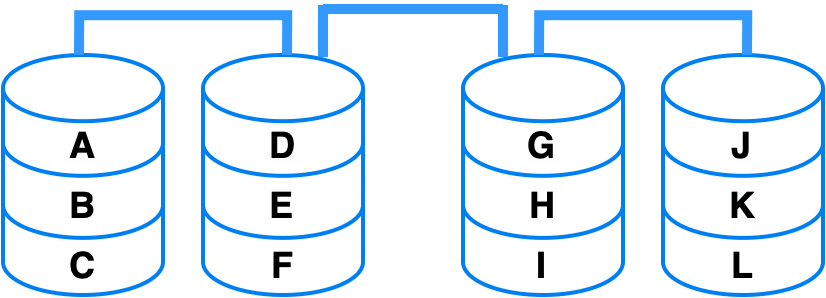
No RAID nível 0, são requeridos no mínimo dois discos. Nele, os dados são divididos em segmentos contíguos e são gravados de forma sequencial em diferentes discos do conjunto. Esses segmentos têm um tamanho fixo, determinado por blocos (Figura 3). O funcionamento do RAID 0 é considerado simples: cada byte de informação é composto por um conjunto de bits. Ao instruir o sistema para gravar um byte em um conjunto RAID 0, a informação é fatiada e distribuída, com cada parte sendo gravada em um dos discos do arranjo. Com todos os discos operando simultaneamente, há um aumento na velocidade tanto de leitura quanto de gravação de dados. Quanto mais discos forem adicionados, menor será a probabilidade de congestionamento no processo.
No entanto, uma desvantagem significativa desse nível de RAID é a completa ausência de redundância dos dados armazenados. Em outras palavras, se um dos discos no RAID falhar, todo o grupo de discos se tornará inacessível.
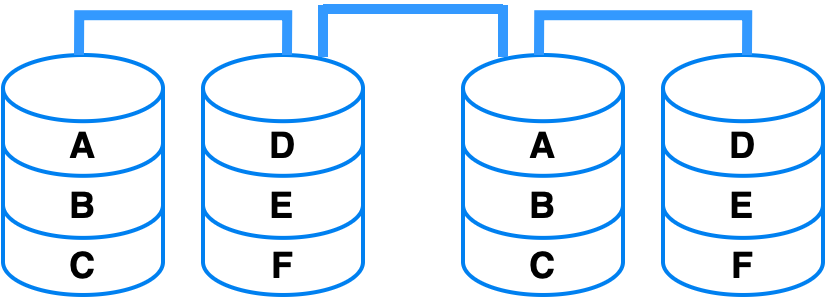
O RAID nível 1 distribui os dados entre os discos, adicionando duplicidade a eles, conforme mostrado na Figura 4. Para implementá-lo, são necessários pelo menos dois discos. Sua principal vantagem é a redundância: se houver falhas, o sistema continua operando. No entanto, essa redundância requer um mínimo de dois discos, o que pode impactar o desempenho de escrita, já que os mesmos dados são gravados nos discos configurados no RAID nível 1.
O RAID nível 2 é semelhante ao RAID 4, descrito a seguir, mas requer um disco adicional para armazenar informações de controle de erros (ECC – Error Correcting Code). Esse tipo tornou-se obsoleto devido aos drivers de disco rígido mais modernos já incluírem esse controle no próprio circuito (Figura 5).
O RAID nível 3 tem como característica principal a gravação paralela com paridade. O controle dos discos é complexo, pois utiliza segmentos de dados com o menor tamanho possível. Isso exige que todos os discos tenham seus eixos sincronizados de forma precisa para evitar atrasos na transferência de dados.
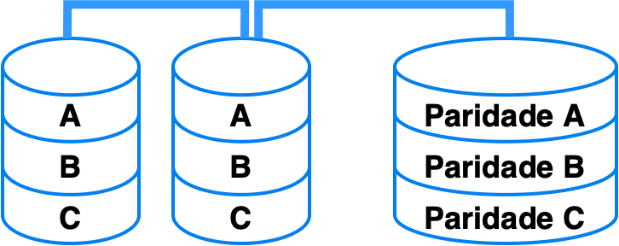
O RAID nível 4 requer um conjunto de discos idênticos, composto por, no mínimo, três unidades. Um dos discos é designado para a gravação das informações de paridade dos dados, seguindo o mesmo princípio do RAID 3. Os discos destinados à gravação dos dados são configurados para armazenar segmentos de tamanho maior. Essa configuração permite uma leitura eficiente de dados, pois apenas o disco de paridade precisa ser acessado para reconstruir informações em caso de falha de um dos discos de dados. No entanto, a gravação de pequenos segmentos pode ser menos eficiente devido à necessidade de acessar o disco de paridade para cada operação de gravação. Além disso, como ocorre com o RAID 3, todos os discos devem ter seus eixos perfeitamente sincronizados para garantir a integridade dos dados.
Nesse sentido, a replicação de um banco de dados segue este processo:
- O servidor mestre registra as alterações ocorridas no banco de dados em seu log binário.
- O servidor escravo copia os eventos registrados pelo servidor mestre no log binário.
- O servidor escravo executa, então, os mesmos eventos do log binário; um thread lê e executa todos os eventos, garantindo que os dados no servidor escravo sejam atualizados para serem idênticos aos do servidor mestre.
O servidor mestre é encarregado de registrar as mudanças em seus dados no log binário, que é cada evento registrado. A cada transação de dados, o servidor mestre registra as alterações no log binário e, em seguida, instrui as ferramentas de armazenamento para salvar as transações.
O servidor escravo é responsável por copiar os eventos do log binário do servidor mestre para seu log de retransmissão (relay log). O servidor escravo, por meio de um thread dedicado, estabelece uma nova conexão com o servidor mestre e começa a transferir os eventos do binlog, que consiste na leitura de eventos a partir do servidor mestre (log binário).
Backups da nuvem
Em contraste com o método tradicional de backup, que envolvia o armazenamento de dados em mídias físicas como CDs, discos rígidos externos e pen drives, geralmente mantidos dentro das instalações da empresa, os backups na nuvem são realizados externamente. Ou seja, os dados são salvos em servidores remotos através da internet, protegidos por empresas especializadas em manutenção e segurança de dados.
Um exemplo prático seria uma empresa que possui seu sistema local e seu banco de dados na mesma rede. Em vez de realizar manualmente um backup na máquina, o próprio banco de dados é equipado com um gerenciador que, em horários predeterminados ao longo do dia, executa automaticamente o backup e o envia para um servidor on-line. Isso garante a integridade dos dados do banco e possibilita a restauração de qualquer lugar.
Adiante podemos ver as vantagens do backup na nuvem:
- Segurança: reduz a exposição a riscos de terceiros acessarem os dados, uma vez que são armazenados em servidores mais robustos e gerenciados por especialistas em segurança de dados. Além disso, há isolamento de conteúdo e protocolos de validação de acesso.
- Flexibilidade: os backups podem ser agendados para ocorrerem automaticamente, o que reduz a dependência de armazenamento local.
- Economia de espaço: libera espaço em hardware físico, utilizado anteriormente pela empresa.
- Acessibilidade e mobilidade: os dados podem ser acessados de qualquer local, desde que haja uma conexão com a internet.
- O MySQL Workbench oferece a funcionalidade de backup on-line, permitindo que os usuários gerenciem o processo de backup, monitorando seu status e as operações realizadas no servidor.
Considere, por exemplo, uma empresa, com várias filiais pelo Brasil, que necessita acessar rapidamente informações da matriz, para verificar o estoque central. Se essa informação não estiver atualizada, um vendedor poderia vender um produto que não existe em estoque, resultando em prejuízo para a empresa. Com a replicação de dados, esse problema seria evitado.
Apesar de já ter uma compreensão sólida sobre estruturas de backup e recuperação de dados, bem como sobre sua importância no ambiente profissional e pessoal, é imprescindível continuar estudando, ampliando conhecimentos em diversas fontes. Com dedicação, você certamente se destacará na administração de bancos de dados.
Vamos Exercitar?
Conforme apresentado anteriormente nesta aula, seu objetivo, estudante, é encontrar uma maneira de melhorar a disponibilidade das informações para o Sr. Joaquim e ajudá-lo a evitar longos períodos de inatividade do sistema. Mesmo que se tenham separado as duas áreas do sistema (produção e engenharia de produtos importados), ainda há o risco de queda no desempenho do sistema na medida em que o acesso aumenta em uma das instâncias.
Para auxiliá-lo nesse aspecto, é crucial compreender que, caso uma das instâncias sofra uma interrupção, o Sr. Joaquim precisa ter acesso quase imediato a essas informações em outro servidor. Para resolver esse desafio adicional, você pode implementar a arquitetura de discos Redundant Arrays of Inexpensive Disks (RAID).
Por meio do RAID, é possível combinar múltiplos discos rígidos e melhorar, consequentemente, o desempenho do servidor de banco de dados. Se um dos discos apresentar algum problema, outro estará pronto para assumir já com as informações do banco de dados. Com exceção do RAID 0, que não é recomendado para ambientes de banco de dados devido à ausência de redundância, os demais níveis são altamente indicados.
Pensando no caso do Sr. Joaquim, a melhor opção seria o RAID 1, pois ele oferece redundância para os dados e é especialmente recomendado para uso em banco de dados devido à sua estrutura. Se um disco do servidor falhar, os dados continuarão acessíveis. Além disso, o RAID 1 é excelente para espelhamento de disco, o que significa que as informações podem ser duplicadas de um disco para outro.
Ao implementar uma configuração RAID 1, o servidor do Sr. Joaquim estará protegido contra possíveis falhas de acesso ou problemas de estrutura. Isso ocorre porque, se uma das estruturas das instâncias falhar, o RAID 1 automaticamente realocará outra instância espelhada, seja no mesmo servidor, seja em outro na rede.
Apesar dessa medida de segurança, é altamente recomendável que o Sr. Joaquim também faça backup de suas bases de dados como precaução adicional. Isso é especialmente importante no caso de corrupção de uma das bases, pois evita a replicação de informações incorretas. Para realizar esse backup, pode ser utilizada a ferramenta MySQL Workbench, que permite gerar backups de uma ou mais bases de dados armazenadas no mesmo servidor. Para acessar essa funcionalidade, é necessário estar conectado ao banco de dados e acessar o menu Administration, na opção "Data Export" (conforme mostrado na Figura 6), que oferece opções para criar backups dos dados. Na seção "export options", é possível definir o caminho de destino do backup do banco de dados, permitindo que a exportação seja salva diretamente em uma mídia externa ou em um dispositivo virtual.
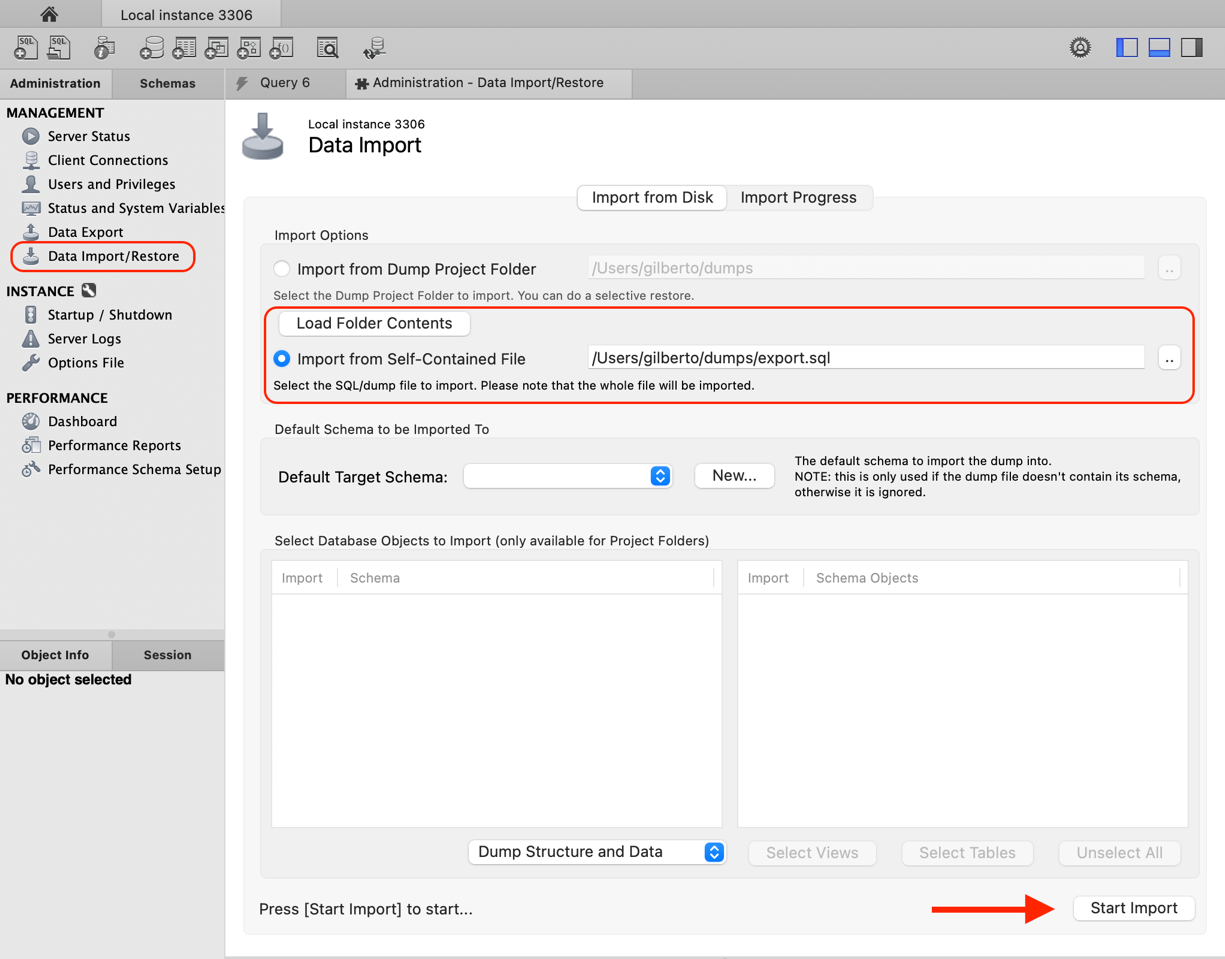
Caso haja perda de dados ou se o servidor ficar inativo por um período prolongado, será necessário restaurar essas informações em outro servidor até que o principal seja normalizado. Para fazer isso, você utilizará a funcionalidade "Data Import" (conforme ilustrado na Figura 7), que possibilita restaurar um banco de dados utilizando o arquivo de backup previamente criado.
Saiba Mais
Para complementar o estudo sobre RAIDs em bancos de dados, leia o capítulo 15 do livro Banco de dados: teoria e desenvolvimento.
ALVES, W. P. Banco de dados: teoria e desenvolvimento. 2. ed. São Paulo: Erica, 2021. E-book. cap. 15, p. 108-115.
Para aprender mais sobre como exportar dados (realizar backup) no MySQL Workbench, confira o seguinte tutorial.
ZAUSO, E. Backup utilizando MySQL Workbench 6.0. Medium, [s. l.], 10 nov. 2023.
E para aprender como importar dados (realizar o restore) no MySQL Workbench, confira o tutorial a seguir.
OLIVA, M. G. Restaurando um backup do banco de dados MySQL. Alura, [s. l.], 16 ago. 2023.
Referências Bibliográficas
ALVES, W. P. Banco de dados: teoria e desenvolvimento. 2. ed. São Paulo: Erica, 2021. E-book.
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
OLIVA, M. G. Restaurando um backup do banco de dados MySQL. Alura, [s. l.], 16 ago. 2023. Disponível em: https://www.alura.com.br/artigos/restaurar-backup-banco-de-dados-mysql#gostou-deste-artigo-e-quer-conhecer-ainda-mais-sobre-banco-de-dados-e-o-mysql. Acesso em: 19 fev. 2024.
ZAUSO, E. Backup utilizando MySQL Workbench 6.0. Medium, [s. l.], 10 nov. 2023. Disponível em: https://evertonzauso.medium.com/backup-da-base-de-dados-utilizando-mysql-workbench-6-0-45be6b817275. Acesso em: 19 fev. 2024.
Encerramento da Unidade
RECURSOS AVANÇADOS EM BANCOS DE DADOS
Videoaula de Encerramento
Olá, estudante! Na videoaula de encerramento desta unidade, você terá a oportunidade de revisar e consolidar os conhecimentos adquiridos sobre controle transacional, procedimentos e funções, controle de acesso e backup e restauração em bancos de dados. Esses conteúdos são fundamentais para a sua prática profissional, pois lhe permitem melhorar a eficiência, a segurança e a disponibilidade dos sistemas de banco de dados que gerenciará. Não perca essa chance de aprimorar suas habilidades e impulsionar sua carreira!
Vamos assistir juntos?
Ponto de Chegada
Olá, estudante! Para desenvolver a competência desta unidade, que é conhecer a automação de processos em bancos de dados, bem como o controle transacional e o controle de acesso, você teve de, primeiramente, compreender conceitos fundamentais relacionados a esses recursos avançados.
No que diz respeito ao controle transacional, você entendeu como os comandos de confirmação de transações, como COMMIT, e os de reversão, como SAVEPOINT e ROLLBACK, são utilizados para garantir a integridade dos dados e para automatizar processos críticos no banco de dados.
Além disso, ao explorar procedimentos e funções, você aprendeu a automatizar tarefas repetitivas e complexas, utilizando funções para realizar cálculos específicos e procedimentos armazenados a fim de executar operações mais elaboradas, contribuindo, assim, para a eficiência dos processos de manipulação de dados.
No âmbito do controle de acesso, você notou como é fundamental dominar os comandos de concessão e revogação de privilégios, como GRANT e REVOKE, bem como compreender a utilização de ROLES, que desempenham um papel essencial na gestão de permissões e na segurança dos dados armazenados.
Por fim, ao estudar o backup e a restauração, você entendeu a importância da redundância de dados e como realizar backups de forma eficiente, seja localmente, seja na nuvem, garantindo a disponibilidade contínua dos dados e a rápida recuperação em caso de falhas ou perdas.
É Hora de Praticar!
Este estudo de caso visa aprofundar seu conhecimento em gerenciamento de banco de dados MySQL, implementando conceitos como procedimentos, funções, controle de acesso e backup/restauração. O objetivo dele é, portanto, otimizar a manipulação de dados, garantir a segurança e proteger a integridade do banco de dados.
Uma loja virtual em crescimento necessita de uma estrutura de banco de dados robusta e segura. Para isso, serão implementadas as seguintes funcionalidades:
- Funções e procedimentos:
Função: calcular desconto em produtos com base na categoria e no valor total da compra.
Procedimento: atualizar automaticamente o estoque após a venda de um produto.
- Controle de acesso
Criar diferentes níveis de acesso para usuários (administradores, vendedores, clientes).
Restringir o acesso a tabelas e operações específicas para cada nível.
- Backup e restauração:
Implementar um cronograma de backup automático do banco de dados.
Realizar backups completos e incrementais para garantir a recuperação em caso de falhas.
Reflita
- Qual a importância do controle transacional para garantir a integridade dos dados em um banco de dados?
- Como os procedimentos armazenados podem contribuir para a automação de processos em um ambiente de banco de dados?
- Por que é fundamental implementar políticas de controle de acesso e segurança em um sistema de gerenciamento de banco de dados?
Resolução do estudo de caso
Funções e procedimentos
Função para calcular desconto:
CREATE FUNCTION calcular_desconto( categoria VARCHAR(20), valor_total DECIMAL(10,2) ) RETURNS DECIMAL(10,2) BEGIN IF categoria = 'Eletronicos' THEN RETURN valor_total * 0.1; ELSEIF categoria = 'Roupas' THEN RETURN valor_total * 0.05; ELSE RETURN 0; END IF; END |
Procedimento para atualizar estoque:
CREATE PROCEDURE atualizar_estoque( produto_id INT, quantidade_vendida INT ) |
BEGIN
UPDATE produtos SET estoque = estoque - quantidade_vendida WHERE produto_id = produto_id; END |
Controle de acesso
Criação de roles
CREATE ROLE administrador; CREATE ROLE vendedor; CREATE ROLE cliente;
GRANT ALL PRIVILEGES ON loja.* TO administrador; GRANT SELECT, INSERT, UPDATE ON loja.* TO vendedor; GRANT SELECT ON loja.* TO cliente; |
Concessão de roles a usuários
GRANT administrador TO 'joaosilva'; GRANT vendedor TO 'mariaclara'; GRANT cliente TO 'carlospereira'; Use o código com cuidado. |
Backup e restauração
Configuração de backup automático
0 0 * * * mysqldump --user=root --password=senha loja > /var/backups/loja_completo.sql 15 0 * * * mysqldump --user=root --password=senha loja --incremental --single-transaction > /var/backups/loja_incremental.sql |
Restauração do banco de dados
mysql -u root -p senha loja < /var/backups/loja_completo.sql mysql -u root -p senha loja < /var/backups/loja_incremental.sql |
Dê o play!
Assimile
Referências
ALVES, W. P. Banco de dados: teoria e desenvolvimento. 2. ed. São Paulo: Erica, 2021. E-book.
DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: LTC, 2023. E-book.
ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson Education do Brasil, 2018. E-book.
SILBERSCHATZ, A. Sistema de banco de dados. 7. ed. Rio de Janeiro: Grupo GEN, 2020. E-book.